|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
Ghi chú bài giảng, phiếu đánh giá
Cơ sở dữ liệu. Ghi chú bài giảng: ngắn gọn, quan trọng nhất
Cẩm nang / Ghi chú bài giảng, phiếu đánh giá Mục lục
Bài giảng số 1. Phần mở đầu 1. Hệ quản trị cơ sở dữ liệu Hệ thống quản lý cơ sở dữ liệu (DBMS) là các sản phẩm phần mềm chuyên dụng cho phép: 1) lưu trữ vĩnh viễn một lượng lớn dữ liệu tùy ý (nhưng không phải là vô hạn); 2) trích xuất và sửa đổi các dữ liệu được lưu trữ này theo cách này hay cách khác, sử dụng cái gọi là truy vấn; 3) tạo cơ sở dữ liệu mới, tức là mô tả cấu trúc dữ liệu logic và thiết lập cấu trúc của chúng, tức là cung cấp giao diện lập trình; 4) truy cập dữ liệu được lưu trữ bởi nhiều người dùng cùng một lúc (tức là cung cấp quyền truy cập vào cơ chế quản lý giao dịch). Theo đó, Cơ sở dữ liệu là các bộ dữ liệu dưới sự kiểm soát của các hệ thống quản lý. Hiện nay các hệ quản trị cơ sở dữ liệu là sản phẩm phần mềm phức tạp nhất trên thị trường và là cơ sở của nó. Trong tương lai, nó được lên kế hoạch tiến hành các phát triển trên sự kết hợp của các hệ thống quản lý cơ sở dữ liệu thông thường với lập trình hướng đối tượng (OOP) và công nghệ Internet. Ban đầu, DBMS dựa trên thứ bậc и mô hình dữ liệu mạng, tức là chỉ được phép làm việc với cấu trúc cây và đồ thị. Trong quá trình phát triển vào năm 1970, các hệ quản trị cơ sở dữ liệu do Codd đề xuất đã xuất hiện, dựa trên mô hình dữ liệu quan hệ. 2. Cơ sở dữ liệu quan hệ Thuật ngữ "quan hệ" bắt nguồn từ từ tiếng Anh "Relations" - "mối quan hệ". Theo nghĩa toán học chung nhất (có thể nhớ được từ khóa học đại số tập cổ điển) thái độ - đó là một bộ R = {(x1,..., xn) | x1 ∈ A1,...,xn ∈ An}, nơi một1,..., MỘTn là các tập hợp tạo thành tích Descartes. Bằng cách này, tỷ lệ R là một tập con của tích Descartes của các tập hợp: A1 x... x An : R ⊆ A 1 x... x An. Ví dụ, hãy xem xét các quan hệ nhị phân của thứ tự nghiêm ngặt "lớn hơn" và "nhỏ hơn" trên tập hợp các cặp số có thứ tự A 1 = A2 = {3, 4, 5}: R> = {(3, 4), (4, 5), (3, 5)} ⊂ A1 x A2; R< = {(5, 4), (4, 3), (5, 3)} ⊂ A1 x A2. Các mối quan hệ này có thể được trình bày dưới dạng bảng. Tỷ lệ "lớn hơn">:
Tỷ lệ "nhỏ hơn" R<:
Như vậy, chúng ta thấy rằng trong cơ sở dữ liệu quan hệ, rất nhiều loại dữ liệu được tổ chức dưới dạng các mối quan hệ và có thể được biểu diễn dưới dạng bảng. Cần lưu ý rằng hai quan hệ R> và R< không tương đương với nhau, hay nói cách khác, các bảng tương ứng với các mối quan hệ này không bằng nhau. Vì vậy, các hình thức biểu diễn dữ liệu trong cơ sở dữ liệu quan hệ có thể khác nhau. Làm thế nào để khả năng đại diện khác nhau này tự biểu hiện trong trường hợp của chúng ta? Mối quan hệ R> và R< - đây là các tập hợp, và tập hợp là một cấu trúc không có thứ tự, có nghĩa là trong các bảng tương ứng với các mối quan hệ này, các hàng có thể được hoán đổi cho nhau. Nhưng đồng thời, các phần tử của các tập hợp này là các tập hợp có thứ tự, trong trường hợp của chúng ta - các cặp số 3, 4, 5 có thứ tự, có nghĩa là các cột không thể hoán đổi cho nhau. Như vậy, chúng ta đã chứng minh rằng biểu diễn một quan hệ (theo nghĩa toán học) dưới dạng một bảng với một thứ tự hàng tùy ý và một số cột cố định là một dạng biểu diễn quan hệ đúng và có thể chấp nhận được. Nhưng nếu chúng ta xem xét các mối quan hệ R> và R< từ quan điểm của thông tin được nhúng trong chúng, rõ ràng là chúng tương đương nhau. Do đó, trong cơ sở dữ liệu quan hệ, khái niệm "mối quan hệ" có một ý nghĩa hơi khác so với một quan hệ trong toán học nói chung. Cụ thể, nó không liên quan đến thứ tự theo các cột trong một hình thức trình bày dạng bảng. Thay vào đó, cái gọi là lược đồ quan hệ "tiêu đề hàng - cột" được giới thiệu, tức là mỗi cột được cung cấp một tiêu đề, sau đó chúng có thể được hoán đổi tự do. Đây là mối quan hệ R của chúng ta sẽ như thế nào> và R< trong cơ sở dữ liệu quan hệ. Một quan hệ thứ tự nghiêm ngặt (thay vì quan hệ R>):
Một quan hệ thứ tự nghiêm ngặt (thay vì quan hệ R<):
Cả hai mối quan hệ bảng đều có một mối quan hệ mới (trong trường hợp này là giống nhau, vì bằng cách giới thiệu các tiêu đề bổ sung, chúng tôi đã xóa sự khác biệt giữa các mối quan hệ R> và R<) Tiêu đề. Vì vậy, chúng ta thấy rằng với sự trợ giúp của một thủ thuật đơn giản như thêm các tiêu đề cần thiết vào các bảng, chúng ta đi đến thực tế là các quan hệ R> và R< trở nên tương đương với nhau. Như vậy, chúng tôi kết luận rằng khái niệm "mối quan hệ" theo nghĩa toán học chung và quan hệ không hoàn toàn trùng khớp, chúng không đồng nhất với nhau. Hiện nay, các hệ quản trị cơ sở dữ liệu quan hệ là nền tảng của thị trường công nghệ thông tin. Nghiên cứu sâu hơn đang được thực hiện theo hướng kết hợp các mức độ khác nhau của mô hình quan hệ. Bài giảng số 2. Thiếu dữ liệu Hai loại giá trị được mô tả trong hệ quản trị cơ sở dữ liệu để phát hiện dữ liệu bị thiếu: trống (hoặc Giá trị trống) và không xác định (hoặc Giá trị rỗng). Trong một số tài liệu (chủ yếu là thương mại), giá trị Null đôi khi được gọi là giá trị trống hoặc rỗng, nhưng điều này không chính xác. Ý nghĩa của các nghĩa trống rỗng và không xác định về cơ bản là khác nhau, vì vậy cần phải theo dõi cẩn thận bối cảnh sử dụng một thuật ngữ cụ thể. 1. Giá trị trống (Giá trị trống) giá trị trống chỉ là một trong nhiều giá trị có thể có đối với một số kiểu dữ liệu được xác định rõ ràng. Chúng tôi liệt kê những gì "tự nhiên" nhất, tức thì giá trị trống (tức là các giá trị trống mà chúng tôi có thể tự phân bổ mà không cần có thêm thông tin): 1) 0 (không) - giá trị null trống đối với kiểu dữ liệu số; 2) false (sai) - là giá trị trống cho kiểu dữ liệu boolean; 3) B '' - chuỗi bit trống cho các chuỗi có độ dài thay đổi; 4) "" - chuỗi trống cho các chuỗi ký tự có độ dài thay đổi. Trong các trường hợp trên, bạn có thể xác định xem một giá trị có rỗng hay không bằng cách so sánh giá trị hiện có với hằng số null được xác định cho từng kiểu dữ liệu. Nhưng các hệ thống quản lý cơ sở dữ liệu, do các chương trình được thực hiện trong chúng để lưu trữ dữ liệu lâu dài, chỉ có thể hoạt động với các chuỗi có độ dài không đổi. Do đó, một chuỗi bit trống có thể được gọi là một chuỗi các số không nhị phân. Hoặc một chuỗi bao gồm dấu cách hoặc bất kỳ ký tự điều khiển nào khác là một chuỗi ký tự trống. Dưới đây là một số ví dụ về chuỗi rỗng có độ dài không đổi: 1) B'0 '; 2) B'000 '; 3) ''. Làm thế nào bạn có thể biết nếu một chuỗi trống trong những trường hợp này? Trong hệ quản trị cơ sở dữ liệu, một hàm logic được sử dụng để kiểm tra tính trống rỗng, tức là vị từ IsEmpty (<biểu thức>), nghĩa đen là "ăn no". Vị từ này thường được xây dựng trong hệ quản trị cơ sở dữ liệu và có thể được áp dụng cho bất kỳ loại biểu thức nào. Nếu không có vị từ này trong các hệ quản trị cơ sở dữ liệu, thì bạn có thể tự viết một hàm logic và đưa nó vào danh sách các đối tượng của cơ sở dữ liệu đang được thiết kế. Hãy xem xét một ví dụ khác, nơi không dễ xác định xem chúng ta có giá trị rỗng hay không. Dữ liệu kiểu ngày tháng. Giá trị nào trong loại này sẽ được coi là giá trị trống nếu ngày có thể thay đổi trong phạm vi từ 01.01.0100. trước 31.12.9999/XNUMX/XNUMX? Để làm điều này, một ký hiệu đặc biệt được đưa vào DBMS cho hằng số ngày trống {...}, nếu giá trị của kiểu này được viết: {DD. MM. YY} hoặc {YY. MM. DD}. Với giá trị này, một phép so sánh xảy ra khi kiểm tra giá trị cho độ trống. Nó được coi là giá trị được xác định rõ ràng, "đầy đủ" của một biểu thức thuộc loại này và là giá trị nhỏ nhất có thể. Khi làm việc với cơ sở dữ liệu, giá trị null thường được sử dụng làm giá trị mặc định hoặc được sử dụng khi giá trị biểu thức bị thiếu. 2. Giá trị không xác định (Giá trị rỗng) Lời Null được sử dụng để biểu thị giá trị không xác định trong cơ sở dữ liệu. Để hiểu rõ hơn những giá trị nào được hiểu là null, hãy xem xét một bảng là một phần của cơ sở dữ liệu:
Vì vậy, giá trị không xác định hoặc Giá trị rỗng - đây là: 1) không xác định, nhưng thông thường, tức là giá trị áp dụng. Ví dụ, ông Khairetdinov, người đứng đầu trong cơ sở dữ liệu của chúng tôi, chắc chắn có một số dữ liệu hộ chiếu (như một người sinh năm 1980 và là công dân của đất nước), nhưng họ không được biết đến, do đó, họ không được đưa vào cơ sở dữ liệu. . Do đó, giá trị Null sẽ được ghi vào cột tương ứng của bảng; 2) không có giá trị áp dụng. Ông Karamazov (số 2 trong cơ sở dữ liệu của chúng tôi) đơn giản là không thể có bất kỳ dữ liệu hộ chiếu nào, bởi vì tại thời điểm tạo ra cơ sở dữ liệu này hoặc nhập dữ liệu vào đó, ông ấy còn là một đứa trẻ; 3) giá trị của bất kỳ ô nào trong bảng, nếu chúng ta không thể nói liệu nó có thể áp dụng được hay không. Ví dụ, ông Kovalenko, người chiếm vị trí thứ ba trong cơ sở dữ liệu của chúng tôi, không biết năm sinh, vì vậy chúng tôi không thể nói chắc chắn liệu ông có hay không có dữ liệu hộ chiếu. Và do đó, giá trị của hai ô trong hàng dành riêng cho ông Kovalenko sẽ là giá trị Null (giá trị đầu tiên - như chưa biết nói chung, ô thứ hai - là một giá trị mà bản chất không xác định). Giống như bất kỳ kiểu dữ liệu nào khác, giá trị Null cũng có một số thuộc tính. Chúng tôi liệt kê những điều quan trọng nhất trong số đó: 1) theo thời gian, cách hiểu về giá trị Null có thể thay đổi. Ví dụ: đối với ông Karamazov (số 2 trong cơ sở dữ liệu của chúng tôi) vào năm 2014, tức là khi đến tuổi trưởng thành, giá trị Null sẽ thay đổi thành một giá trị cụ thể, được xác định rõ ràng; 2) Giá trị null có thể được gán cho một biến hoặc hằng số thuộc bất kỳ kiểu nào (số, chuỗi, boolean, ngày, giờ, v.v.); 3) kết quả của bất kỳ phép toán nào trên biểu thức có giá trị Null làm toán hạng là giá trị Null; 4) một ngoại lệ đối với quy tắc trước đó là các phép toán kết hợp và tách rời trong các điều kiện của quy luật hấp thụ (để biết thêm chi tiết về quy luật hấp thụ, xem đoạn 4 của bài giảng số 2). 3. Giá trị rỗng và quy tắc chung để đánh giá biểu thức Hãy nói thêm về các hành động trên biểu thức có chứa giá trị Null. Quy tắc chung để xử lý các giá trị Null (kết quả của các phép toán trên giá trị Null là một giá trị Null) áp dụng cho các phép toán sau: 1) số học; 2) các phép toán phủ định, kết hợp và ngắt kết hợp theo bit (ngoại trừ các luật hấp thụ); 3) với các phép toán với chuỗi (ví dụ, nối - nối chuỗi); 4) đến các phép toán so sánh (<, ≤, ≠, ≥,>). Hãy cho ví dụ. Kết quả của việc áp dụng các thao tác sau, các giá trị Null sẽ nhận được: 3 + Không, 1 / Không, (Ivanov '+' '+ Không) ≔ Không Ở đây, thay vì bình đẳng thông thường, chúng tôi sử dụng hoạt động thay thế "≔" do tính chất đặc biệt của việc làm việc với các giá trị Null. Trong phần sau, ký tự này cũng sẽ được sử dụng trong các trường hợp tương tự, có nghĩa là biểu thức ở bên phải của ký tự đại diện có thể thay thế bất kỳ biểu thức nào từ danh sách ở bên trái của ký tự đại diện. Bản chất của giá trị Null thường dẫn đến một số biểu thức tạo ra giá trị Null thay vì giá trị rỗng mong đợi, ví dụ: (x - x), y * (x - x), x * 0 ≔ Null khi x = Null. Vấn đề là khi thay, ví dụ, giá trị x = Null vào biểu thức (x - x), chúng ta nhận được biểu thức (Null - Null), và quy tắc chung để tính giá trị của biểu thức chứa giá trị Null có hiệu lực và thông tin về thực tế là ở đây giá trị Null tương ứng với cùng một biến sẽ bị mất. Chúng ta có thể kết luận rằng khi tính toán bất kỳ phép toán nào khác với phép toán logic, giá trị Null được hiểu là không thể áp dụng được, và do đó kết quả cũng là giá trị Null. Việc sử dụng các giá trị Null trong các phép toán so sánh dẫn đến không ít kết quả bất ngờ. Ví dụ: các biểu thức sau cũng tạo ra giá trị Null thay vì giá trị Boolean True hoặc False như mong đợi: (Null <Null); (Vô giá trị ≤ vô giá trị); (Null = Không); (Null ≠ Null); (Null> Null); (Null ≥ Null) ≔ Null; Do đó, chúng tôi kết luận rằng không thể nói rằng giá trị Null bằng hoặc không bằng chính nó. Mỗi lần xuất hiện mới của giá trị Null được coi là độc lập và mỗi lần giá trị Null được coi là các giá trị chưa biết khác nhau. Trong điều này, các giá trị Null về cơ bản khác với tất cả các kiểu dữ liệu khác, bởi vì chúng tôi biết rằng có thể an toàn khi nói về tất cả các giá trị \ uXNUMXb \ uXNUMXb vượt qua trước đó và các loại của chúng bằng nhau hoặc không bằng nhau. Vì vậy, chúng ta thấy rằng các giá trị Null không phải là giá trị của các biến theo nghĩa thông thường của từ này. Do đó, không thể so sánh giá trị của các biến hoặc biểu thức có chứa giá trị Null, vì kết quả là chúng ta sẽ không nhận được giá trị boolean True hoặc False mà là giá trị Null, như trong các ví dụ sau: (x <rỗng); (x ≤ vô giá trị); (x = Null); (x ≠ Không); (x> Null); (x ≥ Không) ≔ Không; Do đó, bằng cách tương tự với các giá trị trống, để kiểm tra một biểu thức cho các giá trị Null, bạn phải sử dụng một vị từ đặc biệt: IsNull (<biểu thức>), nghĩa đen là "là Null". Hàm Boolean trả về True nếu biểu thức chứa Null hoặc bằng Null, và False ngược lại, nhưng không bao giờ trả về Null. Vị từ IsNull có thể được áp dụng cho các biến và biểu thức thuộc bất kỳ kiểu nào. Khi áp dụng cho các biểu thức thuộc kiểu trống, vị từ sẽ luôn trả về False. Ví dụ:
Vì vậy, thực sự, chúng ta thấy rằng trong trường hợp đầu tiên, khi vị từ IsNull được lấy từ XNUMX, kết quả đầu ra là Sai. Trong tất cả các trường hợp, bao gồm cả trường hợp thứ hai và thứ ba, khi các đối số của hàm logic hóa ra bằng giá trị Null và trong trường hợp thứ tư, khi bản thân đối số ban đầu bằng giá trị Null, vị từ trả về True. 4. Giá trị rỗng và các phép toán logic Thông thường, chỉ có ba phép toán logic được hỗ trợ trực tiếp trong các hệ quản trị cơ sở dữ liệu: phủ định ¬, kết hợp &, và kết hợp ∨. Các phép toán liên tiếp ⇒ và tương đương ⇔ được biểu thị bằng cách sử dụng các phép thay thế: (x ⇒ y) ≔ (x ∨ y); (x ⇔ y) ≔ (x ⇒ y) & (y ⇒ x); Lưu ý rằng các thay thế này được bảo toàn đầy đủ khi sử dụng các giá trị Null. Thật thú vị, bằng cách sử dụng toán tử phủ định "¬" bất kỳ phép toán nào trong số các phép toán kết hợp & hoặc phép kết hợp ∨ có thể được biểu diễn một cách liên kết với nhau như sau: (x & y) ≔¬ (¬x ∨¬y); (x ∨ y) ≔ ¬ (¬x & ¬y); Những thay thế này, cũng như những thay thế trước đó, không bị ảnh hưởng bởi giá trị Null. Và bây giờ chúng ta sẽ đưa ra các bảng sự thật của các phép toán logic của phủ định, kết hợp và phân loại, nhưng ngoài các giá trị True và False thông thường, chúng ta cũng sử dụng giá trị Null làm toán hạng. Để thuận tiện, chúng tôi giới thiệu ký hiệu sau: thay vì True, chúng tôi sẽ viết t, thay vì False - f, và thay vì Null - n. 1. Từ chối xx.
Cần lưu ý những điểm thú vị sau liên quan đến hoạt động phủ định sử dụng các giá trị Null: 1) ¬¬x ≔ x - luật phủ định kép; 2) ¬Null ≔ Null - Giá trị Null là một điểm cố định. 2. Nối x & y.
Thao tác này cũng có các thuộc tính riêng của nó: 1) x & y ≔ y & x - tính giao hoán; 2) x & x ≔ x - tính đơn vị; 3) Sai & y ≔ Sai, ở đây Sai là yếu tố hấp thụ; 4) True & y ≔ y, ở đây True là phần tử trung tính. 3. Disjunction x ∨ y.
Свойства: 1) x ∨ y ≔ y ∨ x - tính giao hoán; 2) x ∨ x ≔ x - tính vô nghiệm; 3) Sai ∨ y ≔ y, ở đây Sai là phần tử trung tính; 4) Đúng ∨ y ≔ Đúng, ở đây Đúng là một phần tử hấp thụ. Một ngoại lệ đối với quy tắc chung là các quy tắc để tính toán các phép toán logic kết hợp & và phân tách ∨ trong các điều kiện hành động luật hấp thụ: (Sai & y) ≔ (x & Sai) ≔ Sai; (Đúng ∨ y) ≔ (x ∨ Đúng) ≔ Đúng; Các quy tắc bổ sung này được xây dựng để khi thay thế giá trị Null bằng False hoặc True, kết quả vẫn sẽ không phụ thuộc vào giá trị này. Như đã trình bày trước đây đối với các kiểu hoạt động khác, việc sử dụng giá trị Null trong các phép toán Boolean cũng có thể dẫn đến các giá trị không mong muốn. Ví dụ, ngay từ cái nhìn đầu tiên, logic bị phá vỡ trong luật loại trừ thứ ba (x ∨ ¬x) và luật phản xạ (x = x), vì với x ≔ Null, chúng ta có: (x ∨ ¬x), (x = x) ≔ Không. Luật pháp không được thực thi! Điều này được giải thích theo cách tương tự như trước đây: khi một giá trị Null được thay thế thành một biểu thức, thông tin mà giá trị này được báo cáo bởi cùng một biến sẽ bị mất và quy tắc chung để làm việc với giá trị Null có hiệu lực. Do đó, chúng tôi kết luận: khi thực hiện các phép toán logic với các giá trị Null như một toán hạng, các giá trị này được xác định bởi hệ quản trị cơ sở dữ liệu như có thể áp dụng nhưng không xác định. 5. Giá trị rỗng và kiểm tra điều kiện Vì vậy, từ những điều trên, chúng ta có thể kết luận rằng trong logic của hệ quản trị cơ sở dữ liệu không có hai giá trị logic (Đúng và Sai) mà là ba, vì giá trị Null cũng được coi là một trong những giá trị logic có thể có. Đó là lý do tại sao nó thường được gọi là giá trị không xác định, giá trị không xác định. Tuy nhiên, mặc dù vậy, chỉ có logic hai giá trị được thực hiện trong các hệ quản trị cơ sở dữ liệu. Do đó, một điều kiện có giá trị Null (một điều kiện không xác định) phải được máy hiểu là Đúng hoặc Sai. Theo mặc định, ngôn ngữ DBMS nhận ra một điều kiện có giá trị Null là Sai. Chúng tôi minh họa điều này bằng các ví dụ sau về việc thực hiện các câu lệnh If và While có điều kiện trong hệ quản trị cơ sở dữ liệu: Nếu P thì A khác B; Mục nhập này có nghĩa là: nếu P đánh giá là Đúng, thì hành động A được thực hiện, và nếu P đánh giá là Sai hoặc Null, thì hành động B được thực hiện. Bây giờ chúng ta áp dụng phép toán phủ định cho toán tử này, chúng ta nhận được: Nếu ¬P thì B khác A; Đổi lại, toán tử này có nghĩa như sau: nếu ¬P đánh giá là Đúng, thì hành động B được thực hiện, và nếu ¬P đánh giá là Sai hoặc Null, thì hành động A sẽ được thực hiện. Và một lần nữa, như chúng ta có thể thấy, khi giá trị Null xuất hiện, chúng ta gặp phải kết quả không mong muốn. Vấn đề là hai câu lệnh If trong ví dụ này không tương đương nhau! Mặc dù một trong số chúng có được từ cái kia bằng cách phủ định điều kiện và sắp xếp lại các nhánh, tức là bằng một phép toán tiêu chuẩn. Các toán tử như vậy nói chung là tương đương! Nhưng trong ví dụ của chúng tôi, chúng tôi thấy rằng giá trị null của điều kiện P trong trường hợp đầu tiên tương ứng với lệnh B và trong trường hợp thứ hai - đến A. Bây giờ hãy xem xét hành động của câu lệnh điều kiện while: Trong khi P làm A; B; Nhà điều hành này hoạt động như thế nào? Miễn là P là True, hành động A sẽ được thực hiện, và ngay khi P là Sai hoặc Null, hành động B sẽ được thực hiện. Nhưng giá trị Null không phải lúc nào cũng được hiểu là Sai. Ví dụ, trong các ràng buộc toàn vẹn, các điều kiện không xác định được công nhận là Đúng (các ràng buộc toàn vẹn là các điều kiện được áp đặt lên dữ liệu đầu vào và đảm bảo tính đúng đắn của chúng). Điều này là do trong những ràng buộc như vậy, chỉ những dữ liệu cố tình sai mới bị loại bỏ. Và một lần nữa, trong các hệ quản trị cơ sở dữ liệu, có một hàm thay thế IfNull (ràng buộc toàn vẹn, True), với các giá trị Null và các điều kiện không xác định có thể được biểu diễn một cách rõ ràng. Hãy viết lại các câu lệnh If và While có điều kiện bằng cách sử dụng hàm này: 1) If IfNull (P, False) then A else B; 2) Trong khi IfNull (P, Sai) do A; B; Vì vậy, hàm thay thế IfNull (biểu thức 1, biểu thức 2) trả về giá trị của biểu thức đầu tiên nếu nó không chứa giá trị Null và giá trị của biểu thức thứ hai nếu không. Cần lưu ý rằng không có hạn chế nào được áp đặt đối với kiểu biểu thức được trả về bởi hàm IfNull. Do đó, bằng cách sử dụng hàm này, bạn có thể ghi đè rõ ràng bất kỳ quy tắc nào để làm việc với giá trị Null. Bài giảng số 3. Đối tượng dữ liệu quan hệ 1. Yêu cầu đối với hình thức biểu diễn quan hệ dạng bảng 1. Yêu cầu đầu tiên đối với dạng bảng biểu diễn các quan hệ là tính hữu hạn. Làm việc với các bảng, các mối quan hệ vô hạn hoặc bất kỳ biểu diễn và tổ chức dữ liệu nào khác là không thuận tiện, hiếm khi biện minh cho nỗ lực đã bỏ ra và hơn nữa, hướng này có rất ít ứng dụng thực tế. Nhưng bên cạnh điều này, khá mong đợi, có những yêu cầu khác. 2. Tiêu đề của bảng đại diện cho mối quan hệ nhất thiết phải bao gồm một dòng - tiêu đề của các cột và với các tên duy nhất. Tiêu đề nhiều cấp không được phép. Ví dụ:
Tất cả các tiêu đề nhiều cấp được thay thế bằng các tiêu đề một cấp bằng cách chọn các tiêu đề phù hợp. Trong ví dụ của chúng tôi, bảng sau các phép biến đổi được chỉ định sẽ trông như thế này:
Chúng tôi thấy rằng tên của mỗi cột là duy nhất, vì vậy chúng có thể được hoán đổi theo ý muốn của bạn, tức là thứ tự của chúng trở nên không liên quan. Và điều này rất quan trọng vì nó là tài sản thứ ba. 3. Thứ tự của các dòng không liên quan. Tuy nhiên, yêu cầu này cũng không phải là hạn chế nghiêm ngặt, vì bất kỳ bảng nào cũng có thể dễ dàng rút gọn thành dạng yêu cầu. Ví dụ: bạn có thể nhập một cột bổ sung sẽ xác định thứ tự của các hàng. Trong trường hợp này, sẽ không có gì thay đổi so với hoán vị của các dòng. Đây là một ví dụ về một bảng như vậy:
4. Không được có hàng trùng lặp trong bảng đại diện cho mối quan hệ. Nếu có các hàng trùng lặp trong bảng, điều này có thể dễ dàng được khắc phục bằng cách giới thiệu một cột bổ sung chịu trách nhiệm về số lượng bản sao của mỗi hàng, ví dụ:
Thuộc tính sau đây cũng khá được mong đợi, vì nó làm nền tảng cho tất cả các nguyên tắc lập trình và thiết kế cơ sở dữ liệu quan hệ. 5. Dữ liệu trong tất cả các cột phải cùng loại. Và bên cạnh đó, chúng phải thuộc loại đơn giản. Hãy để chúng tôi giải thích kiểu dữ liệu đơn giản và phức tạp là gì. Kiểu dữ liệu đơn giản là kiểu dữ liệu có giá trị dữ liệu không phải là hỗn hợp, nghĩa là chúng không chứa các phần cấu thành. Do đó, không được có danh sách, cũng như mảng, cây, hoặc các đối tượng tổng hợp tương tự trong các cột của bảng. Những đối tượng như vậy là kiểu dữ liệu tổng hợp - trong các hệ quản trị cơ sở dữ liệu quan hệ, bản thân chúng được trình bày dưới dạng các bảng-quan hệ độc lập. 2. Miền và thuộc tính Miền và thuộc tính là những khái niệm cơ bản trong lý thuyết về tạo và quản lý cơ sở dữ liệu. Hãy giải thích nó là gì. Về mặt hình thức, miền thuộc tính (biểu thị dom (a)), trong đó a là một thuộc tính, được định nghĩa là tập hợp các giá trị hợp lệ cùng loại của thuộc tính tương ứng a. Loại này phải đơn giản, tức là: dom (a) ⊆ {x | type (x) = type (a)}; Thuộc tính (ký hiệu là a) lần lượt được định nghĩa là một cặp có thứ tự bao gồm tên tên thuộc tính (a) và tên miền thuộc tính dom (a), tức là: a = (tên (a): dom (a)); Định nghĩa này sử dụng ":" thay vì "," thông thường (như trong định nghĩa cặp có thứ tự tiêu chuẩn). Điều này được thực hiện để nhấn mạnh sự liên kết giữa miền của thuộc tính và kiểu dữ liệu của thuộc tính. Dưới đây là một số ví dụ về các thuộc tính khác nhau: а1 = (Khóa học: {1, 2, 3, 4, 5}); а2 = (MassaKg: {x | type (x) = real, x 0}); а3 = (LengthSm: {x | type (x) = real, x 0}); Lưu ý rằng các thuộc tính a2 và một3 các miền chính thức khớp. Nhưng ý nghĩa ngữ nghĩa của các thuộc tính này là khác nhau, bởi vì so sánh các giá trị của khối lượng và chiều dài là vô nghĩa. Do đó, miền thuộc tính không chỉ được liên kết với kiểu giá trị hợp lệ mà còn với ý nghĩa ngữ nghĩa. Ở dạng bảng của mối quan hệ, thuộc tính được hiển thị dưới dạng tiêu đề cột trong bảng và miền của thuộc tính không được chỉ định, nhưng được ngụ ý. Nó trông như thế này:
Có thể dễ dàng nhận thấy rằng ở đây mỗi đề mục a1, Một2, Một3 các cột của bảng đại diện cho một mối quan hệ là một thuộc tính riêng biệt. 3. Lược đồ các mối quan hệ. Các bộ giá trị được đặt tên Trong lý thuyết và thực hành của DBMS, các khái niệm về lược đồ quan hệ và giá trị được đặt tên của một bộ giá trị trên một thuộc tính là cơ bản. Hãy mang chúng đi. Lược đồ quan hệ (biểu thị S) được định nghĩa là một tập hợp hữu hạn các thuộc tính với các tên duy nhất, tức là: S = {a | một ∈ S}; Trong mỗi bảng đại diện cho một mối quan hệ, tất cả các tiêu đề cột (tất cả các thuộc tính) được kết hợp thành lược đồ của mối quan hệ. Số lượng thuộc tính trong lược đồ mối quan hệ xác định quyền lực nó quan hệ và được biểu thị là bản số của tập hợp: |S|. Một lược đồ mối quan hệ có thể được kết hợp với một tên lược đồ mối quan hệ. Trong dạng biểu diễn mối quan hệ dạng bảng, như bạn có thể dễ dàng thấy, lược đồ mối quan hệ không hơn gì một hàng tiêu đề cột.
S = {a1, Một2, Một3, Một4} - lược đồ quan hệ của bảng này. Tên quan hệ được hiển thị dưới dạng tiêu đề sơ đồ của bảng. Ở dạng văn bản, lược đồ mối quan hệ có thể được biểu diễn dưới dạng danh sách tên thuộc tính được đặt tên, ví dụ: Học sinh (số hiệu, họ, tên, họ, ngày tháng năm sinh). Ở đây, như trong dạng bảng, các miền thuộc tính không được chỉ định nhưng được ngụ ý. Từ định nghĩa này, lược đồ của một quan hệ cũng có thể trống (S = ∅). Đúng, điều này chỉ có thể thực hiện được trên lý thuyết, vì trong thực tế hệ quản trị cơ sở dữ liệu sẽ không bao giờ cho phép tạo một lược đồ quan hệ rỗng. Đã đặt tên giá trị tuple trên thuộc tính (biểu thị t (a)) được định nghĩa bằng phép loại suy với một thuộc tính là một cặp có thứ tự bao gồm tên thuộc tính và giá trị thuộc tính, tức là: t (a) = (tên (a): x), x ∈ dom (a); Chúng ta thấy rằng giá trị thuộc tính được lấy từ miền thuộc tính. Ở dạng bảng của một mối quan hệ, mỗi giá trị được đặt tên của một bộ giá trị trên một thuộc tính là một ô bảng tương ứng:
Đây t (a1), t (a2), t (a3) - các giá trị được đặt tên của tuple t trên các thuộc tính a1Và2Và3. Các ví dụ đơn giản nhất về các giá trị tuple được đặt tên trên các thuộc tính: (Khóa: 5), (Điểm: 5); Ở đây Khóa học và Điểm số lần lượt là tên của hai thuộc tính và 5 là một trong những giá trị của chúng được lấy từ các miền của chúng. Tất nhiên, mặc dù các giá trị này bằng nhau trong cả hai trường hợp, nhưng chúng khác nhau về mặt ngữ nghĩa, vì tập hợp các giá trị này trong cả hai trường hợp đều khác nhau. 4. Tuples. Tuple các loại Khái niệm về một bộ trong các hệ quản trị cơ sở dữ liệu có thể được tìm thấy một cách trực quan từ điểm trước, khi chúng ta nói về giá trị được đặt tên của một bộ trên các thuộc tính khác nhau. Vì thế, tuple (biểu thị t, từ tiếng Anh. tuple - "tuple") với lược đồ quan hệ S được định nghĩa là tập các giá trị được đặt tên của bộ giá trị này trên tất cả các thuộc tính có trong lược đồ quan hệ S. Nói cách khác, các thuộc tính được lấy từ phạm vi của một tuple, def (t), I E.: t ≡ t (S) = {t (a) | a ∈ def (t) ⊆ S ;. Điều quan trọng là không có nhiều hơn một giá trị thuộc tính phải tương ứng với một tên thuộc tính. Ở dạng bảng của mối quan hệ, một bộ giá trị sẽ là bất kỳ hàng nào của bảng, tức là:
Đây t1(S) = {t (a1), t (a2), t (a3), t (a4)} và t2(S) = {t (a5), t (a6), t (a7), t (a8)} - bộ giá trị. Các bộ dữ liệu trong DBMS khác nhau ở các loại tùy thuộc vào miền định nghĩa của nó. Các bộ giá trị được gọi là: 1) một phần, nếu miền định nghĩa của chúng được bao gồm hoặc trùng với lược đồ của quan hệ, tức là def(t) ⊆ S. Đây là một trường hợp phổ biến trong thực hành cơ sở dữ liệu; 2) hoàn thành, trong trường hợp miền định nghĩa của chúng hoàn toàn trùng khớp, sẽ bằng sơ đồ quan hệ, tức là def(t) = S; 3) chưa hoàn thiện, nếu miền định nghĩa hoàn toàn được bao gồm trong lược đồ quan hệ, tức là def(t) ⊂ S; 4) không có nơi nào được xác định, nếu miền định nghĩa của chúng bằng tập rỗng, tức là def(t) = ∅. Hãy giải thích bằng một ví dụ. Giả sử chúng ta có một mối quan hệ được cho bởi bảng sau.
Hãy để ở đây t1 = {10, 20, 30}, t2 = {10, 20, Null}, t3 = {Null, Null, Null}. Sau đó, dễ dàng nhận thấy rằng tuple t1 - hoàn thành, vì miền định nghĩa của nó là def (t1) = {a, b, c} = S. Tuple t2 - không đầy đủ, def (t2) = {a, b} ⊂ S. Cuối cùng, bộ tuple t3 - không được xác định ở bất kỳ đâu, vì def (t3) = ∅ của nó. Cần lưu ý rằng một tuple không được xác định là một tập hợp rỗng, tuy nhiên được liên kết với một lược đồ quan hệ. Đôi khi một bộ giá trị không xác định được ký hiệu là: ∅ (S). Như chúng ta đã thấy trong ví dụ trên, một bộ giá trị như vậy là một hàng bảng chỉ bao gồm các giá trị Null. Thật thú vị, có thể so sánh, tức là có thể bằng nhau, chỉ là các bộ giá trị có cùng một lược đồ quan hệ. Do đó, ví dụ, hai bộ giá trị không xác định với các lược đồ quan hệ khác nhau sẽ không bằng nhau, như có thể mong đợi. Họ sẽ khác nhau giống như mô hình mối quan hệ của họ. 5. Các mối quan hệ. Các kiểu quan hệ Và cuối cùng, hãy định nghĩa mối quan hệ như một loại đỉnh của kim tự tháp, bao gồm tất cả các khái niệm trước đó. Vì thế, thái độ (biểu thị r, từ tiếng Anh. quan hệ) với lược đồ quan hệ S được định nghĩa là một tập hợp hữu hạn nhất thiết của các bộ giá trị có cùng một lược đồ quan hệ S. Như vậy: r ≡ r (S) = {t (S) | t ∈r}; Tương tự với các lược đồ quan hệ, số lượng bộ giá trị trong một quan hệ được gọi là sức mạnh mối quan hệ và được biểu thị là bản số của tập hợp: |r|. Các mối quan hệ, giống như các bộ giá trị, khác nhau về các loại. Vì vậy, mối quan hệ được gọi là: 1) một phần, nếu điều kiện sau được thỏa mãn đối với bất kỳ bộ giá trị nào có trong quan hệ: [def (t) ⊆ S]. Đây là (như với bộ giá trị) trường hợp chung; 2) hoàn thành, trong trường hợp nếu ∀t ∈ r (S) ta có [def (t) = S]; 3) chưa hoàn thiện, nếu ∃t ∈ r (S) def (t) ⊂ S; 4) không có nơi nào được xác định, nếu ∀t ∈ r (S) [def (t) = ∅]. Chúng ta hãy đặc biệt chú ý đến các mối quan hệ không xác định. Không giống như tuples, làm việc với những mối quan hệ như vậy đòi hỏi một chút tinh tế. Vấn đề là các quan hệ hư không xác định có thể có hai loại: chúng có thể trống hoặc có thể chứa một bộ giá trị hư không xác định (các quan hệ như vậy được ký hiệu là {∅ (S)}). có thể so sánh (tương tự với các bộ giá trị), tức là, có thể bằng nhau, chỉ là các quan hệ với cùng một lược đồ quan hệ. Do đó, các mối quan hệ với các khuôn mẫu quan hệ khác nhau là khác nhau. Ở dạng bảng, một quan hệ là nội dung của bảng, tương ứng với dòng - tiêu đề của các cột, nghĩa là - toàn bộ bảng, cùng với hàng đầu tiên chứa các tiêu đề. Bài giảng số 4. Đại số quan hệ. Hoạt động đơn nguyên đại số quan hệ, như bạn có thể đoán, là một loại đại số đặc biệt trong đó tất cả các phép toán được thực hiện trên các mô hình dữ liệu quan hệ, tức là trên các mối quan hệ. Theo thuật ngữ bảng, một mối quan hệ bao gồm các hàng, cột và một hàng - tiêu đề của các cột. Do đó, các phép toán một ngôi tự nhiên là các phép toán chọn hàng hoặc cột nhất định, cũng như thay đổi tiêu đề cột - đổi tên các thuộc tính. 1. Thao tác lựa chọn đơn nguyên Hoạt động một lần đầu tiên chúng ta sẽ xem xét là thao tác tìm nạp - hoạt động chọn các hàng từ một bảng đại diện cho một quan hệ, theo một số nguyên tắc, tức là, chọn các bộ hàng thỏa mãn một điều kiện hoặc điều kiện nhất định. Nhà điều hành tìm nạp ký hiệu là σ , điều kiện lấy mẫu - P , tức là, toán tử σ luôn được sử dụng với một điều kiện nhất định trên các bộ giá trị P, và bản thân điều kiện P được viết tùy thuộc vào lược đồ của quan hệ S. Tính đến tất cả những điều này, thao tác tìm nạp qua lược đồ của quan hệ S so với quan hệ r sẽ giống như sau: σ r (S) ≡ σ r = {t (S) | t ∈ r & P t} = {t (S) | t ∈ r & IfNull (P t, False}; Kết quả của phép toán này sẽ là một quan hệ mới với cùng một lược đồ quan hệ S, bao gồm các bộ giá trị t (S) của toán hạng quan hệ ban đầu thỏa mãn điều kiện lựa chọn P t. Rõ ràng là để áp dụng một số loại điều kiện cho một tuple, cần phải thay thế các giá trị của các thuộc tính tuple thay vì các tên thuộc tính. Để hiểu rõ hơn về cách hoạt động của thao tác này, chúng ta hãy xem một ví dụ. Hãy cho sơ đồ quan hệ sau: S: Session (Số Sổ Điểm, Họ, Môn học, Lớp). Hãy lấy điều kiện lựa chọn như sau: P = (Chủ đề = 'Khoa học máy tính' và Đánh giá > 3). Chúng ta cần trích xuất từ quan hệ ban đầu-toán hạng những bộ giá trị có chứa thông tin về những học sinh đã đạt ít nhất ba điểm môn "Khoa học Máy tính". Chúng ta hãy cung cấp bộ giá trị sau từ mối quan hệ này: t0(S) ∈ r (S): {(Sổ điểm #: 100), (Họ: 'Ivanov'), (Chủ đề: 'Cơ sở dữ liệu'), (Điểm: 5)}; Áp dụng điều kiện lựa chọn của chúng tôi cho tuple t0, chúng tôi nhận được: P t0 = ('Cơ sở dữ liệu' = 'Khoa học máy tính' và 5 > 3); Trên tuple cụ thể này, điều kiện lựa chọn không được đáp ứng. Nói chung, kết quả của mẫu cụ thể này σ <Môn học = 'Khoa học Máy tính' và Lớp> 3> Buổi sẽ có một bảng "Phiên", trong đó các hàng còn lại thỏa mãn điều kiện lựa chọn. 2. Phép chiếu đơn nguyên Một phép toán đơn phân tiêu chuẩn khác mà chúng ta sẽ nghiên cứu là phép toán chiếu. Phép chiếu là thao tác chọn các cột từ bảng biểu diễn một quan hệ, theo một số thuộc tính. Cụ thể, máy chọn các thuộc tính đó (nghĩa là các cột đó) của quan hệ toán hạng ban đầu đã được chỉ định trong phép chiếu. nhà điều hành chiếu ký hiệu là [S '] hoặc π . Ở đây S 'là một lược đồ con của lược đồ ban đầu của quan hệ S, tức là một số cột của nó. Điều đó có nghĩa là gì? Điều này có nghĩa là S 'có ít thuộc tính hơn S, vì chỉ những thuộc tính đó còn lại trong S' mà điều kiện chiếu đã được thỏa mãn. Và trong bảng biểu diễn quan hệ r (S '), có bao nhiêu hàng trong bảng r (S) và có ít cột hơn, vì chỉ những cột tương ứng với các thuộc tính còn lại vẫn còn. Do đó, toán tử phép chiếu π <S '> được áp dụng cho quan hệ r (S) dẫn đến một quan hệ mới với một lược đồ quan hệ khác r (S'), bao gồm các phép chiếu t (S) [S '] của các bộ giá trị ban đầu quan hệ. Các phép chiếu này được định nghĩa như thế nào? Phép chiếu của bất kỳ bộ t (S) nào của quan hệ ban đầu r (S) với mạch con S 'được xác định theo công thức sau: t (S) [S '] = {t (a) | a ∈ def (t) ∩ S'}, S '⊆S. Điều quan trọng cần lưu ý là các bộ giá trị trùng lặp bị loại trừ khỏi kết quả, tức là sẽ không có hàng trùng lặp nào trong bảng đại diện cho hàng mới. Với tất cả những điều trên, hoạt động chiếu trong hệ thống quản lý cơ sở dữ liệu sẽ trông giống như sau: π r (S) ≡ π r ≡ r (S) [S '] ≡ r [S'] = {t (S) [S '] | t ∈ r}; Hãy xem một ví dụ minh họa cách hoạt động của thao tác tìm nạp. Cho quan hệ "Phiên" và lược đồ của quan hệ này: S: Session (số lớp, Họ, Chủ đề, Lớp); Chúng tôi sẽ chỉ quan tâm đến hai thuộc tính từ lược đồ này, đó là "Sổ điểm #" và "Họ" của học sinh, do đó, tiểu vùng của S sẽ trông như thế này: S ': (Ghi số sách, Họ). Cần phải chiếu quan hệ ban đầu r (S) lên mạch con S '. Tiếp theo, hãy để chúng tôi được cung cấp một tuple t0(S) từ quan hệ ban đầu: t0(S) ∈ r (S): {(Sổ điểm #: 100), (Họ: 'Ivanov'), (Chủ đề: 'Cơ sở dữ liệu'), (Điểm: 5)}; Do đó, hình chiếu của bộ này lên mạch con S 'đã cho sẽ giống như sau: t0(S) S ': {(Số sổ tài khoản: 100), (Họ:' Ivanov ')}; Nếu chúng ta nói về hoạt động chiếu dưới dạng bảng, thì phép chiếu Phiên [số sổ điểm, Họ] của quan hệ ban đầu là bảng Phiên, từ đó tất cả các cột đều bị xóa, ngoại trừ hai: số điểm và Họ. Ngoài ra, tất cả các dòng trùng lặp cũng đã được loại bỏ. 3. Thao tác đổi tên một lần Và hoạt động một lần cuối cùng mà chúng ta sẽ xem xét là hoạt động đổi tên thuộc tính. Nếu chúng ta nói về mối quan hệ dưới dạng bảng, thì thao tác đổi tên là cần thiết để thay đổi tên của tất cả hoặc một số cột. đổi tên nhà điều hành trông như thế này: ρ <φ>, đây φ - đổi tên chức năng. Hàm này thiết lập sự tương ứng XNUMX-XNUMX giữa các tên thuộc tính lược đồ S và Ŝ, trong đó S tương ứng là lược đồ của quan hệ ban đầu và Ŝ là lược đồ của quan hệ với các thuộc tính được đổi tên. Do đó, toán tử ρ <φ> được áp dụng cho quan hệ r (S) đưa ra một quan hệ mới với lược đồ Ŝ, bao gồm các bộ giá trị của quan hệ ban đầu với chỉ các thuộc tính được đổi tên. Hãy viết hoạt động đổi tên các thuộc tính trong hệ quản trị cơ sở dữ liệu: ρ <φ> r (S) ≡ ρ <φ> r = {ρ <φ> t (S) | t ∈ r}; Đây là một ví dụ về việc sử dụng thao tác này: Hãy xem xét mối quan hệ Session đã quen thuộc với chúng ta, với lược đồ: S: Session (số lớp, Họ, Chủ đề, Lớp); Hãy giới thiệu một lược đồ mối quan hệ mới Ŝ, với các tên thuộc tính khác nhau mà chúng ta muốn thấy thay vì những tên hiện có: Ŝ: (Số ZK, Họ, Chủ đề, Điểm); Ví dụ: một khách hàng cơ sở dữ liệu muốn xem các tên khác trong mối quan hệ ngoài hộp của bạn. Để thực hiện thứ tự này, bạn cần thiết kế hàm đổi tên sau: φ: (Số sổ tài khoản, Họ, Môn, Lớp) → (Số ZK, Họ, Môn, Điểm); Trên thực tế, chỉ có hai thuộc tính cần được đổi tên, vì vậy việc viết hàm đổi tên sau thay vì hàm hiện tại là hợp pháp: φ: (số sổ ghi chép, Lớp) → (Số ZK, Điểm); Hơn nữa, hãy cung cấp cho bộ tuple đã quen thuộc thuộc quan hệ Phiên: t0(S) ∈ r (S): {(Sổ điểm #: 100), (Họ: 'Ivanov'), (Chủ đề: 'Cơ sở dữ liệu'), (Điểm: 5)}; Áp dụng toán tử đổi tên cho bộ này: ρ <φ> t0(S): {(ZK #: 100), (Họ: 'Ivanov'), (Chủ đề: 'Cơ sở dữ liệu'), (Điểm: 5)}; Vì vậy, đây là một trong những bộ giá trị của mối quan hệ của chúng ta, có các thuộc tính đã được đổi tên. Theo thuật ngữ bảng, tỷ lệ ρ <Số sổ điểm, Lớp → "Không. ZK, Điểm> Phiên - đây là một bảng mới có được từ bảng quan hệ "Phiên" bằng cách đổi tên các thuộc tính đã chỉ định. 4. Các thuộc tính của phép toán một ngôi Các phép toán một ngôi, giống như bất kỳ phép toán nào khác, có một số thuộc tính nhất định. Hãy xem xét điều quan trọng nhất trong số chúng. Thuộc tính đầu tiên của các phép toán đơn phân về lựa chọn, chiếu và đổi tên là thuộc tính đặc trưng cho tỷ lệ của các trọng số của các quan hệ. (Nhớ lại rằng cardinality là số lượng các bộ giá trị trong một quan hệ này hoặc một quan hệ khác.) Rõ ràng là ở đây chúng ta đang xem xét, tương ứng, quan hệ ban đầu và quan hệ thu được do áp dụng một hoặc một phép toán khác. Lưu ý rằng tất cả các thuộc tính của phép toán một ngôi tuân theo trực tiếp từ các định nghĩa của chúng, vì vậy chúng có thể dễ dàng được giải thích và thậm chí, nếu muốn, được suy luận một cách độc lập. Vì vậy: 1) tỷ lệ quyền lực: a) cho hoạt động lựa chọn: | σ r | ≤ | r |; b) cho phép chiếu: | r [S '] | ≤ | r |; c) cho hoạt động đổi tên: | ρ <φ> r | = | r |; Tổng cộng, chúng ta thấy rằng đối với hai toán tử, cụ thể là đối với toán tử lựa chọn và toán tử chiếu, sức mạnh của các quan hệ ban đầu - các toán hạng lớn hơn sức mạnh của các quan hệ có được từ các toán tử ban đầu bằng cách áp dụng các phép toán tương ứng. Điều này là do lựa chọn đi kèm với hai hoạt động chọn và dự án này loại trừ một số hàng hoặc cột không thỏa mãn các điều kiện lựa chọn. Trong trường hợp khi tất cả các hàng hoặc cột thỏa mãn các điều kiện, thì không có sự suy giảm lũy thừa (tức là số bộ giá trị), do đó bất đẳng thức trong công thức là không nghiêm ngặt. Trong trường hợp của thao tác đổi tên, sức mạnh của quan hệ không thay đổi, do khi thay đổi tên, không có bộ giá trị nào bị loại trừ khỏi quan hệ; 2) thuộc tính Idempotent: a) đối với hoạt động lấy mẫu: σ σ r = σ ; b) cho phép chiếu: r [S '] [S'] = r [S ']; c) đối với hoạt động đổi tên, trong trường hợp chung, tính chất của tính đơn giản không được áp dụng. Thuộc tính này có nghĩa là việc áp dụng cùng một toán tử hai lần liên tiếp cho bất kỳ quan hệ nào cũng tương đương với việc áp dụng nó một lần. Nói chung, đối với hoạt động đổi tên các thuộc tính quan hệ, thuộc tính này có thể được áp dụng, nhưng với các điều kiện và bảo lưu đặc biệt. Tính chất của iđêan rất thường được sử dụng để đơn giản hóa hình thức của một biểu thức và đưa nó về một dạng thực tế, kinh tế hơn. Và thuộc tính cuối cùng chúng ta sẽ xem xét là tính chất của tính đơn điệu. Điều thú vị cần lưu ý là trong bất kỳ điều kiện nào, cả ba toán tử đều đơn điệu; 3) tính chất monotonicity: a) cho một hoạt động tìm nạp: r1 ⊆ r2 ⇒σ r1 ⇒ σ r2; b) đối với hoạt động chiếu: r1 ⊆ r2 ⇒ r1[S'] ⊆ r2 [S']; c) cho hoạt động đổi tên: r1 ⊆ r2 ⇒ ρ <φ> r1 ⊆ ρ <φ> r2; Khái niệm về tính đơn điệu trong đại số quan hệ tương tự như khái niệm tương tự từ đại số thông thường, tổng quát. Hãy để chúng tôi làm rõ: nếu ban đầu các quan hệ r1 và r2 liên quan đến nhau theo cách mà r ⊆ r2, thì ngay cả sau khi áp dụng bất kỳ toán tử nào trong ba toán tử lựa chọn, phép chiếu hoặc đổi tên, mối quan hệ này sẽ được giữ nguyên. Bài giảng số 5. Đại số quan hệ. Hoạt động nhị phân 1. Hoạt động của liên hiệp, giao điểm, khác biệt Bất kỳ hoạt động nào cũng có các quy tắc ứng dụng riêng phải được tuân thủ để các biểu thức và hành động không bị mất ý nghĩa của chúng. Các phép toán lý thuyết tập hợp nhị phân của liên hợp, giao điểm và hiệu số chỉ có thể được áp dụng cho hai quan hệ nhất thiết phải có cùng một lược đồ quan hệ. Kết quả của các phép toán nhị phân như vậy sẽ là các quan hệ bao gồm các bộ giá trị thỏa mãn các điều kiện của phép toán, nhưng có cùng một lược đồ quan hệ như các toán hạng. 1. Kết quả hoạt động công đoàn hai mối quan hệ r1(S) và r2(S) sẽ có một quan hệ mới r3(S) bao gồm các bộ giá trị quan hệ r1(S) và r2(S) thuộc về ít nhất một trong các quan hệ ban đầu và với cùng một lược đồ quan hệ. Vậy giao điểm của hai quan hệ là: r3(S) = r1(S) r2(S) = {t (S) | t ∈r1 ∪t ∈r2}; Để rõ ràng, đây là một ví dụ về bảng: Cho hai quan hệ: r1(S):
r2(S):
Chúng ta thấy rằng lược đồ của quan hệ thứ nhất và thứ hai giống nhau, chỉ khác là chúng có một số bộ giá trị khác nhau. Hợp của hai quan hệ này sẽ là quan hệ r3(S), sẽ tương ứng với bảng sau: r3 (S) = r1(S) r2(S):
Vì vậy, lược đồ của quan hệ S không thay đổi, chỉ có số lượng bộ giá trị tăng lên. 2. Hãy chuyển sang việc xem xét phép toán nhị phân sau: hoạt động giao nhau hai mối quan hệ. Như chúng ta đã biết từ hình học trường học, quan hệ kết quả sẽ chỉ bao gồm những bộ giá trị của quan hệ ban đầu có mặt đồng thời trong cả hai quan hệ r1(S) và r2(S) (một lần nữa, lưu ý mô hình quan hệ tương tự). Hoạt động của giao điểm của hai quan hệ sẽ như thế này: r4(S) = r1(S)∩r2(S) = {t (S) | t ∈ r1 & t ∈ r2}; Và một lần nữa, hãy xem xét ảnh hưởng của phép toán này đối với các quan hệ được trình bày dưới dạng bảng: r1(S):
r2(S):
Theo định nghĩa của phép toán bằng giao điểm của các quan hệ r1(S) và r2(S) sẽ có một quan hệ mới r4(S), có chế độ xem bảng sẽ giống như sau: r4(S) = r1(S)∩r2(S):
Thật vậy, nếu chúng ta nhìn vào các bộ giá trị của quan hệ ban đầu thứ nhất và thứ hai, chỉ có một điểm chung trong số chúng: {b, 2}. Nó trở thành bộ duy nhất của quan hệ mới r4(S). 3. Hoạt động khác biệt hai quan hệ được xác định theo cách tương tự như các hoạt động trước đó. Quan hệ toán hạng, như trong các phép toán trước, phải có cùng các lược đồ quan hệ, khi đó quan hệ kết quả sẽ bao gồm tất cả các bộ giá trị của quan hệ đầu tiên không có trong quan hệ thứ hai, tức là: r5(S) = r1(S)\r2(S) = {t (S) | t ∈ r1 & t ∉ r2}; Các mối quan hệ đã nổi tiếng r1(S) và r2(S), trong chế độ xem dạng bảng trông như thế này: r1(S):
r2(S):
Chúng ta sẽ xem xét cả hai toán hạng trong hoạt động của giao điểm của hai quan hệ. Sau đó, theo định nghĩa này, quan hệ kết quả r5 (S) sẽ giống như sau: r5(S) = r1(S)\r2(S):
Các phép toán nhị phân được coi là cơ bản, các phép toán khác, phức tạp hơn, dựa trên chúng. 2. Sản phẩm Descartes và các phép toán liên kết tự nhiên Phép toán tích Descartes và phép toán kết hợp tự nhiên là phép toán nhị phân của kiểu sản phẩm và dựa trên sự kết hợp của hai phép toán quan hệ mà chúng ta đã thảo luận trước đó. Mặc dù hành động của phép toán Descartes có vẻ quen thuộc với nhiều người, tuy nhiên, chúng ta sẽ bắt đầu với phép toán sản phẩm tự nhiên, vì nó là một trường hợp tổng quát hơn phép toán đầu tiên. Vì vậy, hãy xem xét hoạt động tham gia tự nhiên. Cần lưu ý ngay rằng các toán hạng của hành động này có thể là các quan hệ với các lược đồ khác nhau, ngược lại với ba phép toán nhị phân là liên hợp, giao nhau và đổi tên. Nếu chúng ta xem xét hai quan hệ với các lược đồ quan hệ khác nhau r1(S1) và r2(S2), và rồi họ hợp chất tự nhiên sẽ có một mối quan hệ mới r3(S3), sẽ chỉ bao gồm các bộ toán hạng phù hợp tại giao điểm của các lược đồ quan hệ. Theo đó, lược đồ của mối quan hệ mới sẽ lớn hơn bất kỳ lược đồ nào của mối quan hệ của những mối quan hệ ban đầu, vì nó là sự kết nối của chúng, "dán" lại. Nhân tiện, các bộ giá trị giống hệt nhau trong hai quan hệ toán hạng, theo đó sự "dán" này xảy ra, được gọi là kết nối được. Hãy viết định nghĩa của phép nối tự nhiên trong ngôn ngữ công thức của hệ quản trị cơ sở dữ liệu: r3(S3) = r1(S1)xr2(S2) = {t (S1 ∪S2) | t [S1] ∈ r1 & t (S2) ∈ r2}; Hãy xem xét một ví dụ minh họa rõ ràng công việc của một kết nối tự nhiên, "sự kết dính" của nó. Cho hai quan hệ r1(S1) và r2(S2), ở dạng bảng biểu diễn, tương ứng, bằng: r1(S1):
r2(S2):
Chúng ta thấy rằng các quan hệ này có các bộ giá trị trùng nhau tại giao điểm của các lược đồ S1 và S2 các mối quan hệ. Hãy liệt kê chúng: 1) tuple {a, 1} của quan hệ r1(S1) khớp với bộ giá trị {1, x} của quan hệ r2(S2); 2) tuple {b, 1} từ r1(S1) cũng khớp với bộ giá trị {1, x} từ r2(S2); 3) tuple {c, 3} giống với tuple {3, z}. Do đó, theo phép nối tự nhiên, quan hệ mới r3(S3) có được bằng cách "dán" chính xác vào các bộ giá trị này. Vì vậy, r3(S3) trong chế độ xem bảng sẽ trông như thế này: r3(S3) = r1(S1)xr2(S2):
Hóa ra theo định nghĩa: lược đồ S3 không trùng với sơ đồ S1, cũng không phải với lược đồ S2, chúng tôi đã "dán" hai lược đồ ban đầu bằng cách các bộ giá trị giao nhau để có được phép nối tự nhiên của chúng. Hãy để chúng tôi chỉ ra sơ đồ cách các bộ giá trị được nối khi áp dụng thao tác nối tự nhiên. Cho quan hệ r1 có dạng điều kiện:
Và tỷ lệ r2 - lượt xem:
Sau đó, kết nối tự nhiên của chúng sẽ trông như thế này:
Chúng ta thấy rằng việc "dán" các toán hạng-quan hệ xảy ra theo cùng một sơ đồ mà chúng ta đã đưa ra trước đó, xem xét ví dụ. Hoạt động Kết nối Descartes là một trường hợp đặc biệt của hoạt động kết hợp tự nhiên. Cụ thể hơn, khi xem xét ảnh hưởng của phép toán Descartes lên các quan hệ, chúng tôi cố ý quy định rằng trong trường hợp này chúng ta chỉ có thể nói về các lược đồ quan hệ không giao nhau. Kết quả của việc áp dụng cả hai phép toán, các quan hệ với các lược đồ bằng sự kết hợp của các lược đồ của quan hệ toán hạng, chỉ tất cả các cặp bộ giá trị có thể có của chúng đều thuộc tích Descartes của hai quan hệ, vì các lược đồ của toán hạng trong mọi trường hợp không được giao nhau. Do đó, dựa trên những điều đã nói ở trên, chúng tôi viết một công thức toán học cho phép toán tích Descartes: r4(S4) = r1(S1)xr2(S2) = {t (S1 ∪S2) | t[S1] ∈ r1 & t (S2) ∈ r2}, S1 ∩S2= ∅; Bây giờ chúng ta hãy xem xét một ví dụ để cho thấy lược đồ quan hệ kết quả sẽ trông như thế nào khi áp dụng phép toán tích số Descartes. Cho hai quan hệ r1(S1) và r2(S2), được trình bày dưới dạng bảng như sau: r1(S1):
r2(S2):
Vì vậy, chúng ta thấy rằng không có bộ giá trị nào của quan hệ r1(S1) và r2(S2), thực sự, không trùng khớp trong giao điểm của chúng. Do đó, trong quan hệ kết quả r4(S4) tất cả các cặp bộ giá trị có thể có của quan hệ toán hạng thứ nhất và thứ hai sẽ giảm. Lấy: r4(S4) = r1(S1)xr2(S2):
Chúng tôi đã có được một lược đồ quan hệ mới r4(S4) không phải bằng cách "dán" các bộ giá trị như trong trường hợp trước, mà bằng cách liệt kê tất cả các cặp bộ giá trị khác nhau có thể không khớp trong giao điểm của các lược đồ ban đầu. Một lần nữa, như trong trường hợp liên kết tự nhiên, chúng tôi đưa ra một ví dụ sơ đồ về hoạt động của phép toán tích Descartes. Hãy để r1 thiết lập như sau:
Và tỷ lệ r2 được:
Sau đó, tích Descartes của họ có thể được biểu diễn dưới dạng giản đồ như sau:
Theo cách này, quan hệ kết quả thu được khi áp dụng phép toán tích Đề-các. 3. Các thuộc tính của phép toán nhị phân Từ các định nghĩa trên về các phép toán nhị phân của liên hợp, giao điểm, hiệu số, tích Descartes và phép nối tự nhiên, các thuộc tính tuân theo. 1. Thuộc tính đầu tiên, như trong trường hợp các phép toán một ngôi, minh họa tỷ lệ quyền lực quan hệ: 1) đối với hoạt động của công đoàn: |r1 ∪r2| ≤ |r1| + | r2|; 2) đối với hoạt động giao cắt: |r1 ∩r2 | ≤ tối thiểu (| r1|, | r2|); 3) đối với hoạt động khác biệt: |r1 \r2| ≤ | r1|; 4) cho hoạt động sản phẩm Descartes: |r1 xr2| = | r1| | r2|; 5) đối với hoạt động tham gia tự nhiên: |r1 xr2| ≤ | r1| | r2|. Tỷ lệ lũy thừa, như chúng ta nhớ, đặc trưng cho cách số lượng bộ giá trị trong quan hệ thay đổi sau khi áp dụng một hoặc một phép toán khác. Vậy chúng ta thấy gì? Quyền lực hiệp hội hai mối quan hệ r1 và r2 nhỏ hơn tổng các con số của các quan hệ toán hạng ban đầu. Tại sao chuyện này đang xảy ra? Vấn đề là khi bạn hợp nhất, các bộ giá trị phù hợp sẽ biến mất, chồng chéo lên nhau. Vì vậy, tham khảo ví dụ mà chúng tôi đã xem xét sau khi thực hiện thao tác này, bạn có thể thấy rằng trong quan hệ đầu tiên có hai bộ giá trị, trong mối quan hệ thứ hai - ba và trong kết quả - bốn, tức là nhỏ hơn năm (tổng của cardinalities của các quan hệ-toán hạng). Bởi bộ giá trị phù hợp {b, 2}, các mối quan hệ này được "gắn lại với nhau". Sức mạnh kết quả Giao lộ hai quan hệ nhỏ hơn hoặc bằng tổng số nhỏ nhất của quan hệ toán hạng ban đầu. Chúng ta hãy chuyển sang định nghĩa của phép toán này: chỉ những bộ giá trị có trong cả hai quan hệ ban đầu mới được tham gia vào quan hệ kết quả. Điều này có nghĩa là bản số của quan hệ mới không thể vượt quá bản số của toán hạng quan hệ mà số bộ giá trị là nhỏ nhất trong hai. Và lũy thừa của kết quả có thể bằng với tổng số tối thiểu này, vì trường hợp này luôn được cho phép khi tất cả các bộ giá trị của một quan hệ với một quân số thấp hơn trùng với một số bộ giá trị của toán hạng quan hệ thứ hai. Trong trường hợp hoạt động sự khác biệt mọi thứ đều khá tầm thường. Thật vậy, nếu tất cả các bộ giá trị cũng có trong quan hệ thứ hai bị "trừ" khỏi toán hạng-quan hệ thứ nhất, thì số của chúng (và do đó, sức mạnh của chúng) sẽ giảm. Trong trường hợp không có một bộ giá trị nào của quan hệ đầu tiên khớp với bất kỳ bộ giá trị nào của quan hệ thứ hai, tức là không có gì để "trừ", thì sức mạnh của nó sẽ không giảm. Thật thú vị, nếu hoạt động Sản phẩm Descartes lũy thừa của quan hệ kết quả chính xác bằng tích lũy thừa của hai quan hệ toán hạng. Rõ ràng là điều này xảy ra bởi vì tất cả các cặp bộ giá trị có thể có của các quan hệ ban đầu đều được ghi vào kết quả và không có gì bị loại trừ. Và cuối cùng, hoạt động kết nối tự nhiên Một quan hệ nhận được có lũy thừa lớn hơn hoặc bằng tích lũy thừa của hai quan hệ ban đầu. Một lần nữa, điều này xảy ra bởi vì các quan hệ toán hạng được "gắn chặt" bởi các bộ giá trị phù hợp và các bộ giá trị không phù hợp bị loại trừ hoàn toàn khỏi kết quả. 2. Thuộc tính lý tưởng: 1) cho phép toán liên hiệp: r ∪ r = r; 2) đối với phép toán giao nhau: r ∩ r = r; 3) cho hoạt động khác biệt: r \ r ≠ r; 4) đối với hoạt động sản phẩm Descartes (trong trường hợp chung, tài sản không được áp dụng); 5) đối với phép nối tự nhiên: rxr = r. Điều thú vị là, thuộc tính của tính đơn giản không đúng cho tất cả các phép toán trên, và đối với phép toán của tích Descartes, nó hoàn toàn không áp dụng được. Thật vậy, nếu bạn kết hợp, giao nhau hoặc kết nối tự nhiên bất kỳ mối quan hệ nào với chính nó, nó sẽ không thay đổi. Nhưng nếu bạn trừ khỏi một quan hệ chính xác bằng nó, kết quả sẽ là một quan hệ rỗng. 3. tính chất giao hoán: 1) đối với hoạt động của công đoàn: r1 ∪r2 = r2 ∪r1; 2) đối với hoạt động giao cắt: r ∩ r = r ∩ r; 3) đối với hoạt động khác biệt: r1 \r2 ≠r2 \r1; 4) cho hoạt động sản phẩm Descartes: r1 xr2 = r2 xr1; 5) đối với hoạt động tham gia tự nhiên: r1 xr2 = r2 xr1. Thuộc tính giao hoán giữ cho tất cả các phép toán ngoại trừ phép toán chênh lệch. Điều này rất dễ hiểu, bởi vì thành phần của chúng (các bộ giá trị) không thay đổi so với việc sắp xếp lại các quan hệ ở các vị trí. Và khi áp dụng phép toán chênh lệch, điều quan trọng là quan hệ toán hạng nào đứng trước, bởi vì nó phụ thuộc vào bộ giá trị nào của quan hệ nào sẽ được coi là tham chiếu, tức là bộ giá trị nào sẽ được so sánh để loại trừ. 4. Thuộc tính liên kết: 1) đối với hoạt động của công đoàn: (r1 ∪r2)∪r3 = r1 ∪ (r2 ∪r3); 2) đối với hoạt động giao cắt: (r1 ∩r2) ∩r3 = r1 ∩(r2 ∩r3); 3) đối với hoạt động khác biệt: (r1 \r2)\r3 ≠r1 \(r2 \r3); 4) cho hoạt động sản phẩm Descartes: (r1 xr2)xr3 = r1 x(r2 xr3); 5) đối với hoạt động tham gia tự nhiên: (r1 xr2)xr3 = r1 x(r2 xr3). Và một lần nữa chúng ta thấy rằng thuộc tính được thực thi cho tất cả các hoạt động ngoại trừ hoạt động khác biệt. Điều này được giải thích theo cách tương tự như trong trường hợp áp dụng tính chất giao hoán. Nhìn chung, các phép toán liên hợp, giao, chênh lệch và phép nối tự nhiên không quan tâm đến thứ tự của các quan hệ toán hạng. Nhưng khi các quan hệ bị “lấy mất” khỏi nhau, trật tự đóng vai trò chi phối. Dựa vào các tính chất và suy luận trên, có thể rút ra kết luận sau: ba tính chất cuối cùng, cụ thể là tính chất đơn vị, tính giao hoán và tính kết hợp, đúng với tất cả các phép toán đã xét, ngoại trừ phép toán về hiệu của hai quan hệ. , không có thuộc tính nào trong số ba thuộc tính được chỉ ra là thỏa mãn cả, và chỉ trong một trường hợp, thuộc tính được phát hiện là không thể áp dụng được. 4. Tùy chọn hoạt động kết nối Sử dụng làm cơ sở các phép toán đơn phân của phép chọn, phép chiếu, đổi tên và phép toán nhị phân của phép kết hợp, điểm giao nhau, điểm khác biệt, tích Descartes và phép nối tự nhiên được xem xét trước đó (tất cả chúng thường được gọi là hoạt động kết nối), chúng tôi có thể giới thiệu các phép toán mới xuất phát từ các khái niệm và định nghĩa ở trên. Hoạt động này được gọi là biên dịch. tham gia các tùy chọn hoạt động. Biến thể đầu tiên của hoạt động kết hợp là hoạt động kết nối bên trong theo điều kiện kết nối được chỉ định. Hoạt động của một phép nối bên trong, theo một số điều kiện cụ thể, được định nghĩa là một phép toán phái sinh từ các phép toán của tích Descartes và phép chọn. Chúng tôi viết định nghĩa công thức của hoạt động này: r1(S1)x P r2(S2) = σ (r1 xr2), S1 ∩S2 = ∅; Đây P = P <S1 ∪S2> - một điều kiện áp đặt cho sự kết hợp của hai lược đồ của các toán hạng-quan hệ ban đầu. Chính điều kiện này mà các bộ giá trị được chọn từ các quan hệ r1 và r2 vào quan hệ kết quả. Lưu ý rằng thao tác nối bên trong có thể được áp dụng cho các mối quan hệ với các lược đồ quan hệ khác nhau. Các lược đồ này có thể là bất kỳ, nhưng trong mọi trường hợp, chúng không được giao nhau. Các bộ giá trị của các toán hạng quan hệ ban đầu là kết quả của phép toán nối bên trong được gọi là bộ sưu tập có thể ghép lại. Để minh họa trực quan hoạt động của phép nối bên trong, chúng tôi sẽ đưa ra ví dụ sau. Hãy cho chúng ta hai quan hệ r1(S1) và r2(S2) với các lược đồ quan hệ khác nhau: r1(S1):
r2(S2):
Bảng sau đây sẽ cho kết quả của việc áp dụng phép toán nối trong với điều kiện P = (b1 = b2). r1(S1)x P r2(S2):
Vì vậy, chúng ta thấy rằng thực sự "dính" hai bảng biểu diễn các mối quan hệ đã xảy ra chính xác trong các bộ giá trị mà điều kiện của phép toán nối bên trong P = (b1 = b2) được thỏa mãn. Bây giờ, dựa trên hoạt động kết hợp bên trong đã được giới thiệu, chúng tôi có thể giới thiệu hoạt động tham gia bên ngoài bên trái и tham gia bên ngoài bên phải. Hãy giải thích. Kết quả của phép toán nối bên trái bên ngoài là kết quả của phép nối bên trong, được hoàn thành với các bộ giá trị không thể ghép nối của toán hạng-quan hệ nguồn bên trái. Tương tự, kết quả của hoạt động nối bên ngoài bên phải được định nghĩa là kết quả của hoạt động nối bên trong, được hoàn thành với các bộ giá trị không thể ghép nối của toán hạng quan hệ nguồn ở bên phải. Câu hỏi làm thế nào các mối quan hệ kết quả của các hoạt động của các phép nối bên trái và bên phải được bổ sung lại là điều khá mong đợi. Các bộ số của một toán hạng-quan hệ được bổ sung trên lược đồ của một toán hạng-quan hệ khác Giá trị rỗng. Cần lưu ý rằng các phép toán nối ngoài bên trái và bên phải được giới thiệu theo cách này là các phép toán bắt nguồn từ phép toán nối bên trong. Để viết ra các công thức chung cho các phép toán nối ngoài trái và phải, chúng ta sẽ thực hiện một số cấu tạo bổ sung. Hãy cho chúng ta hai quan hệ r1(S1) và r2(S2) với các sơ đồ quan hệ khác nhau S1 và S2, mà không giao nhau. Vì chúng ta đã quy định rằng các phép toán nối trong bên trái và bên phải là các dẫn xuất, chúng ta có thể nhận được các công thức bổ trợ sau để xác định phép toán nối bên trái bên ngoài: 1) r3 (S2 ∪S1) ≔ r1(S1)x Pr2(S2); r 3 (S2 ∪S1) đơn giản là kết quả của phép nối bên trong của các quan hệ r1(S1) và r2(S2). Phép nối bên ngoài bên trái là một phép toán phái sinh của phép toán phép nối bên trong, đó là lý do tại sao chúng ta bắt đầu các cấu trúc của mình với nó; 2) r4(S1) ≔ r 3(S2 ∪S1) [S1]; Do đó, với sự trợ giúp của phép chiếu một ngôi, chúng tôi đã chọn tất cả các bộ giá trị có thể ghép nối của toán hạng quan hệ ban đầu bên trái r1(S1). Kết quả được chỉ định r4(S1) để dễ sử dụng; 3) r5 (S1) ≔ r1(S1)\r4(S1); Đây r1(S1) là tất cả các bộ giá trị của toán hạng quan hệ nguồn bên trái và r4(S1) - bộ giá trị riêng của nó, chỉ được kết nối. Do đó, sử dụng phép toán nhị phân của sự khác biệt, đối với r5(S1) chúng tôi nhận được tất cả các bộ giá trị không thể ghép nối của quan hệ toán hạng bên trái; 4) r6(S2) ≔ {∅ (S2)}; {∅ (S2)} là một quan hệ mới với lược đồ (S2) chỉ chứa một bộ giá trị và được tạo thành từ các giá trị Null. Để thuận tiện, chúng tôi ký hiệu tỷ lệ này là r6(S2); 5) r7 (S2 ∪S1) ≔ r5(S1)xr6(S2); Ở đây chúng tôi đã lấy các bộ giá trị không được kết nối của quan hệ toán hạng bên trái (r5(S1)) và bổ sung chúng trên lược đồ của quan hệ thứ hai-toán hạng S2 Giá trị rỗng, tức là Descartes nhân quan hệ bao gồm các bộ giá trị rất không thể ghép nối này với quan hệ r6(S2) được định nghĩa trong đoạn bốn; 6) r1(S1) →x P r2(S2) ≔ (r1 x P r2)∪r7 (S2 ∪S1); Đó là những gì nó là tham gia bên ngoài bên trái, thu được, như có thể thấy, bởi sự kết hợp của tích Descartes của các toán hạng-quan hệ ban đầu r1 và r2 và quan hệ r7 (S2 ∪ S1) được định nghĩa trong đoạn XNUMX. Bây giờ chúng ta có tất cả các tính toán cần thiết để xác định không chỉ hoạt động của liên kết ngoài bên trái, mà còn bằng phép loại suy và xác định hoạt động của liên kết ngoài bên phải. Vì thế: 1) hoạt động tham gia bên ngoài bên trái ở dạng nghiêm ngặt, nó trông như thế này: r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪ [(r1 \(r1 x P r2) [S1]) x {∅(S2)}]; 2) hoạt động tham gia bên ngoài bên phải được định nghĩa theo cách tương tự với hoạt động nối ngoài bên trái và có dạng sau: r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪ [(r2 \(r1 x P r2) [S2]) x {∅(S1)}]; Hai phép toán dẫn xuất này chỉ có hai thuộc tính đáng nói. 1. Tính chất giao hoán: 1) đối với hoạt động nối bên ngoài bên trái: r1(S1) →x P r2(S2) ≠ r2(S2) →x P r1(S1); 2) cho hoạt động nối bên ngoài bên phải: r1(S1) ←x P r2(S2) ≠ r2(S2) ←x P r1(S1) Vì vậy, chúng ta thấy rằng tính chất giao hoán không được thỏa mãn đối với các phép toán này ở dạng tổng quát, nhưng đồng thời, các phép toán của phép nối bên trái và bên phải là nghịch đảo lẫn nhau, tức là điều sau là đúng: 1) đối với hoạt động nối bên ngoài bên trái: r1(S1) →x P r2(S2) = r2(S2) →x P r1(S1); 2) cho hoạt động nối bên ngoài bên phải: r1(S1) ←x P r2(S2) = r2(S2) ←x Pr1(S1). 2. Thuộc tính chính của các hoạt động kết hợp bên ngoài bên trái và bên phải là chúng cho phép phục hồi quan hệ-toán hạng ban đầu theo kết quả cuối cùng của một phép toán nối cụ thể, tức là, các thao tác sau được thực hiện: 1) đối với hoạt động nối bên ngoài bên trái: r1(S1) = (r1 →x P r2) [S1]; 2) cho hoạt động nối bên ngoài bên phải: r2(S2) = (r1 ←x P r2) [S2]. Do đó, chúng ta thấy rằng toán hạng quan hệ ban đầu đầu tiên có thể được khôi phục từ kết quả của phép toán nối trái-phải, và cụ thể hơn, bằng cách áp dụng cho kết quả của phép nối này (r1 xr2) phép toán đơn nguyên của phép chiếu lên lược đồ S1, [S1]. Và tương tự, toán hạng quan hệ ban đầu thứ hai có thể được khôi phục bằng cách áp dụng phép nối bên ngoài bên phải (r1 xr2) phép toán đơn vị của phép chiếu lên lược đồ của quan hệ S2. Hãy đưa ra một ví dụ để xem xét chi tiết hơn về hoạt động của các hoạt động của các phép nối bên trái và bên phải bên ngoài. Hãy để chúng tôi giới thiệu các quan hệ đã quen thuộc r1(S1) và r2(S2) với các lược đồ quan hệ khác nhau: r1(S1):
r2(S2):
Bộ số không thể ghép nối của quan hệ bên trái-toán hạng r2(S2) là một bộ giá trị {d, 4}. Theo định nghĩa, chính họ là những người bổ sung cho kết quả của kết nối bên trong của hai quan hệ toán hạng ban đầu. Điều kiện tham gia bên trong của các quan hệ r1(S1) và r2(S2) chúng ta cũng để tương tự: P = (b1 = b2). Sau đó, kết quả của hoạt động tham gia bên ngoài bên trái sẽ có bảng sau: r1(S1) →x P r2(S2):
Thật vậy, như chúng ta có thể thấy, do tác động của hoạt động của phép nối bên ngoài bên trái, kết quả của hoạt động nối bên trong được bổ sung bằng các bộ giá trị không thể ghép nối bên trái, tức là, trong trường hợp của chúng ta, quan hệ thứ nhất- toán hạng. Việc bổ sung bộ tuple trong lược đồ của toán hạng quan hệ nguồn thứ hai (bên phải), theo định nghĩa, đã xảy ra với sự trợ giúp của các giá trị Null. Và tương tự với kết quả tham gia bên ngoài bên phải giống như trước đây, điều kiện P = (b1 = b2) của các toán hạng-quan hệ ban đầu r1(S1) và r2(S2) là bảng sau: r1(S1) ←x P r2(S2):
Thật vậy, trong trường hợp này, kết quả của phép toán nối bên trong phải được bổ sung bằng các bộ giá trị không thể ghép nối của quyền, trong trường hợp của chúng ta, là toán hạng-quan hệ ban đầu thứ hai. Một bộ giá trị như vậy, như không khó để thấy, trong quan hệ thứ hai r2(S2) một, cụ thể là {2, y}. Tiếp theo, chúng ta thực hiện định nghĩa hoạt động của phép nối ngoài bên phải, bổ sung bộ giá trị của toán hạng đầu tiên (bên trái) trong lược đồ của toán hạng đầu tiên với giá trị Null. Cuối cùng, hãy xem phiên bản thứ ba của các thao tác nối ở trên. Toàn bộ hoạt động tham gia bên ngoài. Phép toán này không chỉ có thể được coi là một phép toán bắt nguồn từ các phép toán phép nối bên trong, mà còn như một sự kết hợp của các phép toán phép nối bên trái và bên phải. Toàn bộ hoạt động tham gia bên ngoài được định nghĩa là kết quả của việc hoàn thành cùng một phép nối bên trong (như trong trường hợp định nghĩa phép nối bên trái và bên phải) với các bộ giá trị không thể nối của cả quan hệ toán hạng ban đầu bên trái và bên phải. Dựa trên định nghĩa này, chúng tôi đưa ra dạng công thức của định nghĩa này: r1(S1) ↔x P r2(S2) = (r1 →x P r2) ∪ (r1 ←x P r2); Phép toán nối ngoài đầy đủ cũng có một thuộc tính tương tự như phép toán nối ngoài bên trái và bên phải. Chỉ do bản chất tương hỗ ban đầu của hoạt động liên kết ngoài đầy đủ (xét cho cùng, nó được định nghĩa là sự kết hợp của các hoạt động liên kết ngoài bên trái và bên phải), nó thực hiện tính chất giao hoán: r1(S1) ↔x P r2(S2) = r2(S2) ↔ x P r1(S1); Và để hoàn thành việc xem xét các tùy chọn cho các hoạt động nối, chúng ta hãy xem một ví dụ minh họa hoạt động của một hoạt động nối bên ngoài đầy đủ. Chúng tôi giới thiệu hai quan hệ r1(S1) và r2(S2) và điều kiện tham gia. Hãy r1(S1)
r2(S2):
Và để điều kiện kết nối của các quan hệ r1(S1) và r2(S2) sẽ là: P = (b1 = b2), như trong các ví dụ trước. Sau đó, kết quả của phép toán nối bên ngoài đầy đủ của các quan hệ r1(S1) và r2(S2) với điều kiện P = (b1 = b2) sẽ có bảng sau: r1(S1) ↔x P r2(S2):
Vì vậy, chúng ta thấy rằng phép toán liên kết ngoài đầy đủ biện minh rõ ràng cho định nghĩa của nó là sự kết hợp các kết quả của các phép toán liên kết ngoài bên trái và bên phải. Mối quan hệ kết quả của hoạt động nối bên trong được bổ sung bởi các bộ giá trị không thể ghép đồng thời như bên trái (đầu tiên, r1(S1)), và phải (thứ hai, r2(S2)) của toán hạng-quan hệ ban đầu. 5. Hoạt động phái sinh Vì vậy, chúng tôi đã xem xét các biến thể khác nhau của các phép toán nối, cụ thể là các phép toán của phép nối trong, phép nối bên trái, bên phải và đầy đủ, là các dẫn xuất của tám phép toán ban đầu của đại số quan hệ: phép toán một bậc của phép chọn, phép chiếu, đổi tên và phép toán nhị phân của liên hiệp, giao điểm, sự khác biệt, tích Descartes và kết nối tự nhiên. Nhưng ngay cả trong số các phép toán ban đầu này cũng có các ví dụ về các phép toán phái sinh. 1. Ví dụ, hoạt động Giao lộ hai tỷ lệ là một đạo hàm của phép toán của hiệu của hai tỷ số giống nhau. Hãy thể hiện nó. Hoạt động giao cắt có thể được biểu thị bằng công thức sau: r1(S)∩r2(S) = r1 \r1 \r2 hoặc, cho cùng một kết quả: r1(S)∩r2(S) = r2 \r2 \r1; 2. Một ví dụ khác về một phép toán cơ bản bắt nguồn từ tám phép toán ban đầu là phép toán kết nối tự nhiên. Ở dạng tổng quát nhất của nó, phép toán này có nguồn gốc từ phép toán nhị phân của tích Descartes và các phép toán đơn phân của việc chọn, chiếu và đổi tên các thuộc tính. Tuy nhiên, đến lượt nó, phép toán liên kết bên trong lại là một phép toán phái sinh của phép toán tương tự của tích Descartes của các quan hệ. Do đó, để chỉ ra rằng phép toán liên kết tự nhiên là một phép toán phái sinh, hãy xem xét ví dụ sau. Hãy so sánh các ví dụ trước cho các phép toán nối tự nhiên và phép nối bên trong. Hãy cho chúng ta hai quan hệ r1(S1) và r2(S2) sẽ hoạt động như các toán hạng. Họ đều bình đẳng: r1(S1):
r2(S2):
Như chúng ta đã nhận được trước đó, kết quả của phép toán liên kết tự nhiên của các quan hệ này sẽ là một bảng có dạng sau: r3(S3) ≔ r1(S1)xr2(S2):
Và kết quả của sự nối bên trong của các quan hệ giống nhau r1(S1) và r2(S2) với điều kiện P = (b1 = b2) sẽ có bảng sau: r4(S4) ≔ r1(S1)x P r2(S2):
Hãy để chúng tôi so sánh hai kết quả này, các quan hệ mới kết quả r3(S3) và r4(S4). Rõ ràng là phép toán liên kết tự nhiên được thể hiện thông qua hoạt động nối bên trong, nhưng quan trọng nhất là với một điều kiện nối có dạng đặc biệt. Hãy viết một công thức toán học mô tả hoạt động của phép toán liên kết tự nhiên dưới dạng đạo hàm của phép toán nối bên trong. r1(S1)xr2(S2) = {ρ <ϕ1> r1 x E ρ <ϕ2>r2}[S1 ∪S2], nơi E - điều kiện kết nối tuples; E = ∀a ∈S1 ∩S2 [IsNull (b1) & IsNull (2) ∪b1 = b2]; b1 = ϕ1 (tên (a)), b2 = ϕ2 (tên (a)); Đây là một trong những đổi tên các chức năng ϕ1 giống hệt nhau và một chức năng đổi tên khác (cụ thể là ϕ2) đổi tên các thuộc tính nơi các lược đồ của chúng ta giao nhau. Điều kiện kết nối E cho các bộ giá trị được viết ở dạng tổng quát, có tính đến khả năng xuất hiện của các giá trị Null, bởi vì phép toán nối bên trong (như đã đề cập ở trên) là một phép toán phái sinh từ tích Descartes của hai quan hệ và phép toán chọn một bậc. 6. Biểu thức của đại số quan hệ Hãy để chúng tôi chỉ ra cách các biểu thức và phép toán của đại số quan hệ được xem xét trước đó có thể được sử dụng trong hoạt động thực tế của các cơ sở dữ liệu khác nhau. Ví dụ, chúng ta có thể xử lý một đoạn của một số cơ sở dữ liệu thương mại: Các nhà cung cấp (Mã nhà cung cấp, Tên nhà cung cấp, Thành phố của nhà cung cấp); Công cụ (Mã công cụ, Tên công cụ,...); Giao hàng (Mã nhà cung cấp, mã phần); Các tên thuộc tính được gạch dưới [1] là các thuộc tính chính (tức là nhận dạng), mỗi thuộc tính có mối quan hệ riêng. Giả sử rằng chúng tôi, với tư cách là nhà phát triển cơ sở dữ liệu này và người quản lý thông tin về vấn đề này, được lệnh lấy tên của các nhà cung cấp (Tên nhà cung cấp) và vị trí của họ (Thành phố nhà cung cấp) trong trường hợp các nhà cung cấp này không cung cấp bất kỳ công cụ nào một tên chung "Kìm". Để xác định tất cả các nhà cung cấp đáp ứng yêu cầu này trong cơ sở dữ liệu có thể rất lớn của chúng tôi, chúng tôi viết một vài biểu thức của đại số quan hệ. 1. Chúng tôi hình thành một kết nối tự nhiên của mối quan hệ "Nhà cung cấp" và "Nguồn cung cấp" để khớp với từng nhà cung cấp mã của các bộ phận do họ cung cấp. Quan hệ mới - kết quả của việc áp dụng phép toán của phép nối tự nhiên - để thuận tiện cho việc áp dụng thêm, chúng tôi ký hiệu là r1. Nhà cung cấp x Nguồn cung cấp ≔ r1 (Mã nhà cung cấp, Tên nhà cung cấp, Thành phố của nhà cung cấp, Trong ngoặc đơn, chúng tôi đã liệt kê tất cả các thuộc tính của các quan hệ liên quan đến phép toán nối tự nhiên này. Chúng ta có thể thấy rằng thuộc tính "ID nhà cung cấp" bị trùng lặp, nhưng trong bản ghi tóm tắt giao dịch, mỗi tên thuộc tính sẽ chỉ xuất hiện một lần, tức là: Nhà cung cấp x Nguồn cung cấp ≔ r1 (Mã nhà cung cấp, Tên nhà cung cấp, Thành phố nhà cung cấp, Mã công cụ); 2. một lần nữa chúng tôi hình thành một kết nối tự nhiên, chỉ lần này là mối quan hệ có được trong đoạn một và mối quan hệ Dụng cụ. Chúng tôi làm điều này để khớp tên của công cụ này với từng mã công cụ có được trong đoạn trước. r1 x Công cụ [Mã công cụ, Tên công cụ] ≔ r2 (Mã nhà cung cấp, Tên nhà cung cấp, Thành phố của nhà cung cấp, Kết quả thu được sẽ được ký hiệu là r2, các thuộc tính trùng lặp bị loại trừ: r1 x Công cụ [Mã công cụ, Tên công cụ] ≔ r2 (Mã nhà cung cấp, Tên nhà cung cấp, Thành phố nhà cung cấp, Mã thiết bị, Tên thiết bị); Lưu ý rằng chúng tôi chỉ lấy hai thuộc tính từ quan hệ Công cụ: "Mã công cụ" và "Tên công cụ". Để làm điều này, chúng ta, như có thể thấy từ ký hiệu của quan hệ r2, đã áp dụng thao tác chiếu đơn vị: Công cụ [Mã công cụ, Tên công cụ], tức là nếu các Công cụ liên quan được trình bày dưới dạng bảng, kết quả của thao tác chiếu này sẽ là hai cột đầu tiên có tiêu đề "Mã công cụ" và "Công cụ tên "tương ứng". Điều thú vị là hai bước đầu tiên mà chúng ta đã xem xét là khá chung chung, đó là, chúng có thể được sử dụng để thực hiện bất kỳ yêu cầu nào khác. Nhưng hai điểm tiếp theo lần lượt thể hiện các bước cụ thể để đạt được nhiệm vụ cụ thể đặt ra trước mắt. 3. Viết phép toán chọn một bậc theo điều kiện <"Tên dụng cụ" = "Kìm"> liên quan đến tỷ số r2thu được ở đoạn trước. Và đến lượt chúng tôi, áp dụng hoạt động dự báo một lần [Mã nhà cung cấp, Tên nhà cung cấp, Thành phố của nhà cung cấp] cho kết quả của hoạt động này để nhận được tất cả các giá trị của các thuộc tính này, bởi vì chúng tôi cần lấy thông tin này dựa trên gọi món. Vì vậy: (σ <Tên dụng cụ = "Kìm"> r2) [Mã nhà cung cấp, Tên nhà cung cấp, Thành phố của nhà cung cấp] ≔ r3 (Mã nhà cung cấp, Tên nhà cung cấp, Thành phố nhà cung cấp, Mã dụng cụ, Tên dụng cụ). Trong tỷ lệ kết quả, ký hiệu là r3, chỉ những nhà cung cấp (với tất cả dữ liệu nhận dạng của họ) mới quay ra cung cấp các công cụ có tên chung là "Kìm". Nhưng theo đơn đặt hàng, chúng tôi cần chọn ra những nhà cung cấp mà ngược lại, không cung cấp các công cụ đó. Do đó, hãy chuyển sang bước tiếp theo của thuật toán và viết ra biểu thức đại số quan hệ cuối cùng, biểu thức này sẽ cung cấp cho chúng ta thông tin mà chúng ta đang tìm kiếm. 4. Đầu tiên, chúng ta hãy tạo sự khác biệt giữa tỷ lệ "Nhà cung cấp" và tỷ lệ r3và sau khi áp dụng phép toán nhị phân này, chúng tôi áp dụng phép toán chiếu một lần trên các thuộc tính "Tên nhà cung cấp" và "Thành phố nhà cung cấp". (Nhà cung cấp \ r3) [Tên nhà cung cấp, Thành phố của nhà cung cấp] ≔ r4 (Mã nhà cung cấp, Tên nhà cung cấp, Thành phố nhà cung cấp); Kết quả được chỉ định r4, mối quan hệ này chỉ bao gồm những bộ giá trị của mối quan hệ "Nhà cung cấp" ban đầu tương ứng với điều kiện của đơn đặt hàng của chúng tôi. Vì vậy, chúng tôi đã chỉ ra cách, bằng cách sử dụng các biểu thức và phép toán của đại số quan hệ, bạn có thể thực hiện tất cả các loại hành động với cơ sở dữ liệu tùy ý, thực hiện các lệnh khác nhau, v.v. Bài giảng số 6. Ngôn ngữ SQL Đầu tiên chúng ta hãy đưa ra một chút bối cảnh lịch sử. Ngôn ngữ SQL, được thiết kế để tương tác với cơ sở dữ liệu, xuất hiện vào giữa những năm 1970. (xuất bản lần đầu từ năm 1974) và được phát triển bởi IBM như một phần của dự án hệ quản trị cơ sở dữ liệu quan hệ thử nghiệm. Tên ban đầu của ngôn ngữ là SEQUEL (Có cấu trúc English Ngôn ngữ truy vấn) - chỉ phản ánh một phần bản chất của ngôn ngữ này. Ban đầu, ngay sau khi được phát minh và trong thời kỳ đầu hoạt động của ngôn ngữ SQL, tên của nó là viết tắt của cụm từ Ngôn ngữ truy vấn có cấu trúc, được dịch là "Ngôn ngữ truy vấn có cấu trúc". Tất nhiên, ngôn ngữ này chủ yếu tập trung vào việc xây dựng các truy vấn đến cơ sở dữ liệu quan hệ sao cho thuận tiện và dễ hiểu đối với người dùng. Nhưng trên thực tế, hầu như ngay từ đầu, nó đã là một ngôn ngữ cơ sở dữ liệu hoàn chỉnh, ngoài các phương tiện tạo truy vấn và thao tác cơ sở dữ liệu, nó còn cung cấp các tính năng sau: 1) phương tiện xác định và thao tác với lược đồ cơ sở dữ liệu; 2) các phương tiện để xác định các ràng buộc toàn vẹn và các trình kích hoạt (sẽ được đề cập sau); 3) phương tiện xác định các khung nhìn cơ sở dữ liệu; 4) phương tiện xác định cấu trúc lớp vật lý hỗ trợ việc thực thi hiệu quả các yêu cầu; 5) các phương tiện cho phép truy cập vào các quan hệ và các lĩnh vực của chúng. Ngôn ngữ này thiếu các phương tiện để đồng bộ hóa rõ ràng quyền truy cập vào các đối tượng cơ sở dữ liệu từ phía các giao dịch song song: ngay từ đầu, người ta cho rằng việc đồng bộ hóa cần thiết đã được thực hiện ngầm bởi hệ quản trị cơ sở dữ liệu. Hiện tại, SQL không còn là viết tắt nữa mà là tên của một ngôn ngữ độc lập. Ngoài ra, hiện tại, ngôn ngữ truy vấn có cấu trúc được thực hiện trong tất cả các hệ thống quản lý cơ sở dữ liệu quan hệ thương mại và trong hầu hết các DBMS ban đầu không dựa trên cách tiếp cận quan hệ. Tất cả các công ty sản xuất đều tuyên bố rằng việc triển khai của họ tuân theo tiêu chuẩn SQL và trên thực tế, các phương ngữ được triển khai của Ngôn ngữ truy vấn có cấu trúc là rất gần nhau. Điều này đã không đạt được ngay lập tức. Một đặc điểm của hầu hết các hệ quản trị cơ sở dữ liệu thương mại hiện đại gây khó khăn cho việc so sánh các phương ngữ hiện có của SQL là thiếu mô tả thống nhất về ngôn ngữ. Thông thường, mô tả nằm rải rác trong các sách hướng dẫn khác nhau và trộn lẫn với mô tả về các tính năng ngôn ngữ dành riêng cho hệ thống không liên quan trực tiếp đến ngôn ngữ truy vấn có cấu trúc. Tuy nhiên, có thể nói rằng tập hợp các câu lệnh SQL cơ bản, bao gồm các câu lệnh để xác định lược đồ cơ sở dữ liệu, tìm nạp và thao tác dữ liệu, cho phép truy cập dữ liệu, hỗ trợ nhúng SQL vào ngôn ngữ lập trình và các câu lệnh SQL động, được thiết lập tốt trong triển khai thương mại và ít nhiều phù hợp với tiêu chuẩn. Theo thời gian và làm việc trên Ngôn ngữ truy vấn có cấu trúc, người ta đã có thể đạt được tiêu chuẩn để chuẩn hóa rõ ràng cú pháp và ngữ nghĩa của các câu lệnh truy xuất dữ liệu, thao tác dữ liệu và khắc phục các ràng buộc về tính toàn vẹn của cơ sở dữ liệu. Các phương tiện đã được chỉ định để xác định khóa chính và khóa ngoại của các mối quan hệ và cái gọi là ràng buộc kiểm tra tính toàn vẹn, là một tập hợp con của các ràng buộc toàn vẹn SQL được kiểm tra ngay lập tức. Các công cụ xác định khóa ngoại giúp dễ dàng hình thành các yêu cầu của cái gọi là tính toàn vẹn tham chiếu của cơ sở dữ liệu (mà chúng ta sẽ đề cập sau). Yêu cầu này, phổ biến trong cơ sở dữ liệu quan hệ, cũng có thể được xây dựng trên cơ sở cơ chế chung của các ràng buộc toàn vẹn SQL, nhưng việc xây dựng dựa trên khái niệm khóa ngoại đơn giản và dễ hiểu hơn. Vì vậy, tính đến tất cả những điều này, hiện tại, ngôn ngữ truy vấn có cấu trúc không chỉ là tên của một ngôn ngữ, mà là tên của toàn bộ nhóm ngôn ngữ, vì mặc dù có các tiêu chuẩn hiện có, nhưng nhiều phương ngữ khác nhau của ngôn ngữ truy vấn có cấu trúc vẫn được triển khai. trong các hệ quản trị cơ sở dữ liệu khác nhau, tất nhiên, có một cơ sở chung. 1. Câu lệnh Select là câu lệnh cơ bản của Ngôn ngữ truy vấn có cấu trúc Vị trí trung tâm trong ngôn ngữ truy vấn có cấu trúc SQL bị chiếm bởi câu lệnh Select, câu lệnh này thực hiện hoạt động được yêu cầu nhiều nhất khi làm việc với cơ sở dữ liệu - truy vấn. Toán tử Chọn đánh giá cả biểu thức đại số quan hệ và giả quan hệ. Trong khóa học này, chúng ta sẽ xem xét việc triển khai chỉ các phép toán đơn phân và nhị phân của đại số quan hệ mà chúng ta đã trình bày, cũng như việc triển khai các truy vấn bằng cách sử dụng cái gọi là truy vấn con. Nhân tiện, cần lưu ý rằng trong trường hợp làm việc với các phép toán đại số quan hệ, các bộ giá trị trùng lặp có thể xuất hiện trong các quan hệ kết quả. Không có sự nghiêm cấm nghiêm ngặt nào đối với sự hiện diện của các hàng trùng lặp trong quan hệ trong các quy tắc của ngôn ngữ truy vấn có cấu trúc (không giống như trong đại số quan hệ thông thường), vì vậy không cần thiết phải loại trừ các hàng trùng lặp khỏi kết quả. Vì vậy, chúng ta hãy xem cấu trúc cơ bản của câu lệnh Select. Nó khá đơn giản và bao gồm các cụm từ bắt buộc tiêu chuẩn sau: Lựa chọn... Từ... Ở đâu... ; Thay cho dấu chấm lửng trong mỗi dòng phải là các quan hệ, thuộc tính và điều kiện của một cơ sở dữ liệu cụ thể và các nhiệm vụ cho nó. Trong trường hợp chung nhất, cấu trúc Chọn cơ bản sẽ giống như sau: Chọn chọn một số thuộc tính Từ từ một mối quan hệ như vậy Ở đâu với các điều kiện như vậy và như vậy để lấy mẫu các bộ Do đó, chúng tôi chọn các thuộc tính từ lược đồ mối quan hệ (tiêu đề của một số cột), đồng thời chỉ ra các mối quan hệ từ đó (và, như bạn có thể thấy, có thể có một số) chúng tôi thực hiện lựa chọn của mình và cuối cùng, dựa trên điều kiện nào chúng tôi dừng sự lựa chọn của chúng tôi trên một số bộ giá trị nhất định. Điều quan trọng cần lưu ý là các tham chiếu thuộc tính được tạo bằng cách sử dụng tên của chúng. Như vậy, sau đây thu được thuật toán làm việc câu lệnh Chọn cơ bản này: 1) các điều kiện để chọn các bộ giá trị từ quan hệ được ghi nhớ; 2) nó được kiểm tra xem bộ giá trị nào đáp ứng các thuộc tính được chỉ định. Các bộ giá trị như vậy được ghi nhớ; 3) các thuộc tính được liệt kê trong dòng đầu tiên của cấu trúc cơ bản của câu lệnh Select với các giá trị của chúng là đầu ra. (Nếu chúng ta nói về dạng bảng của mối quan hệ, thì các cột đó của bảng sẽ được hiển thị, các tiêu đề của chúng được liệt kê là các thuộc tính cần thiết; tất nhiên, các cột sẽ không được hiển thị hoàn toàn, trong mỗi cột chỉ có các bộ giá trị đó thỏa mãn các điều kiện đã đặt tên sẽ vẫn còn.) Hãy xem xét một ví dụ. Hãy cho chúng tôi mối quan hệ sau r1, dưới dạng một phần của cơ sở dữ liệu hiệu sách nào đó:
Giả sử chúng ta cũng được cung cấp biểu thức sau với câu lệnh Chọn: Chọn Tên sách, Tác giả của sách Từ r1 Ở đâu Giá sách> 200; Kết quả của toán tử này sẽ là đoạn tuple sau: (Điện thoại di động, S. King). (Trong phần tiếp theo, chúng tôi sẽ xem xét nhiều ví dụ về triển khai truy vấn bằng cách sử dụng cấu trúc cơ bản này và nghiên cứu ứng dụng của nó một cách chi tiết.) 2. Hoạt động đơn nguyên trong ngôn ngữ của truy vấn có cấu trúc Trong phần này, chúng ta sẽ xem xét cách triển khai các phép toán đơn nguyên quen thuộc về lựa chọn, phép chiếu và đổi tên trong ngôn ngữ truy vấn có cấu trúc bằng cách sử dụng toán tử Chọn. Điều quan trọng cần lưu ý là nếu trước đó chúng ta chỉ có thể làm việc với các phép toán riêng lẻ, thì ngay cả một câu lệnh Chọn duy nhất trong trường hợp chung cũng cho phép chúng ta xác định toàn bộ biểu thức đại số quan hệ chứ không chỉ một phép toán đơn lẻ. Vì vậy, chúng ta hãy tiến hành phân tích trực tiếp sự biểu diễn của các phép toán một ngôi trong ngôn ngữ của các truy vấn có cấu trúc. 1. Thao tác lấy mẫu. Thao tác lựa chọn trong SQL được thực hiện bởi câu lệnh Chọn có dạng sau: Chọn tất cả các thuộc tính Từ tên quan hệ Ở đâu điều kiện lựa chọn; Ở đây, thay vì viết "tất cả các thuộc tính", bạn có thể sử dụng dấu "*". Trong lý thuyết ngôn ngữ truy vấn có cấu trúc, biểu tượng này có nghĩa là chọn tất cả các thuộc tính từ lược đồ quan hệ. Điều kiện lựa chọn ở đây (và trong tất cả các hoạt động triển khai khác) được viết dưới dạng biểu thức logic với các kết nối chuẩn không phải (not), và (và), hoặc (hoặc). Các thuộc tính mối quan hệ được gọi bằng tên của chúng. Hãy xem xét một ví dụ. Hãy xác định lược đồ quan hệ sau: học lực (Số sổ điểm, Học kỳ, Mã môn học, Xếp hạng, Ngày tháng); Ở đây, như đã đề cập trước đó, các thuộc tính được gạch dưới tạo thành khóa quan hệ. Hãy để chúng tôi soạn một câu lệnh Chọn có dạng sau, thực hiện thao tác lựa chọn một lần: lựa chọn* Từ kết quả học tập Trường hợp Sổ điểm # = 100 và Học kỳ = 6; Rõ ràng là với kết quả của nhà điều hành này, máy sẽ hiển thị sự tiến bộ của học sinh với số kỷ lục là một trăm cho học kỳ thứ sáu. 2. Thao tác chiếu. Thao tác chiếu trong Ngôn ngữ truy vấn có cấu trúc thậm chí còn dễ triển khai hơn thao tác tìm nạp. Nhớ lại rằng khi áp dụng thao tác chiếu, không phải hàng được chọn (như khi áp dụng thao tác chọn), mà là cột. Do đó, nó đủ để liệt kê các tiêu đề của các cột bắt buộc (tức là tên thuộc tính), mà không chỉ định bất kỳ điều kiện không liên quan nào. Tổng cộng, chúng ta nhận được một toán tử có dạng sau: Chọn danh sách các tên thuộc tính Từ tên quan hệ; Sau khi áp dụng câu lệnh này, máy sẽ trả về các cột của bảng quan hệ có tên đã được chỉ định trong dòng đầu tiên của câu lệnh Chọn này. Như chúng tôi đã đề cập trước đó, không cần thiết phải loại trừ các hàng và cột trùng lặp khỏi quan hệ kết quả. Nhưng nếu trong một đơn đặt hàng hoặc trong một nhiệm vụ cần phải loại bỏ các bản sao, bạn nên sử dụng một tùy chọn đặc biệt của ngôn ngữ truy vấn có cấu trúc - khác biệt. Tùy chọn này đặt tính năng tự động loại bỏ các bộ giá trị trùng lặp khỏi mối quan hệ. Với tùy chọn này được áp dụng, câu lệnh Chọn sẽ giống như sau: Chọn danh sách các tên thuộc tính riêng biệt Từ tên quan hệ; Trong SQL, có một ký hiệu đặc biệt cho các thành phần tùy chọn của biểu thức - dấu ngoặc vuông [...]. Do đó, ở dạng tổng quát nhất, thao tác chiếu sẽ như sau: Chọn [riêng biệt] danh sách các tên thuộc tính Từ tên quan hệ; Tuy nhiên, nếu kết quả của việc áp dụng hoạt động được đảm bảo không chứa các bản sao hoặc các bản sao vẫn được chấp nhận, thì tùy chọn khác biệt tốt hơn là không chỉ định để không làm lộn xộn hồ sơ, tức là vì lý do hoạt động của người vận hành. Hãy xem xét một ví dụ minh họa khả năng tin cậy XNUMX% trong trường hợp không có bản sao. Hãy để sơ đồ các mối quan hệ đã được biết đến với chúng ta: học lực (Số sổ điểm, Học kỳ, Mã môn học, Xếp hạng, Ngày tháng). Cho câu lệnh Chọn sau: Chọn Số sổ điểm, Học kỳ, Mã môn học Từ học lực; Ở đây, dễ dàng nhận thấy rằng ba thuộc tính được trả về bởi toán tử tạo thành khóa của quan hệ. Đó là lý do tại sao tùy chọn khác biệt trở nên thừa, vì được đảm bảo không có bản sao. Điều này xuất phát từ một yêu cầu đối với các khóa được gọi là một ràng buộc duy nhất. Chúng tôi sẽ xem xét thuộc tính này chi tiết hơn sau, nhưng nếu thuộc tính là khóa, thì không có bản sao trong đó. 3. Thao tác đổi tên. Thao tác đổi tên các thuộc tính trong ngôn ngữ truy vấn có cấu trúc khá đơn giản. Cụ thể, nó được thể hiện trong thực tế bằng thuật toán sau: 1) trong danh sách tên thuộc tính của cụm từ Chọn, những thuộc tính cần được đổi tên sẽ được liệt kê; 2) từ khóa đặc biệt được thêm vào từng thuộc tính cụ thể; 3) sau mỗi lần xuất hiện của từ as, tên của thuộc tính tương ứng được chỉ ra, mà nó là cần thiết để thay đổi tên gốc. Do đó, tính đến tất cả những điều trên, câu lệnh tương ứng với thao tác đổi tên các thuộc tính sẽ giống như sau: Chọn tên thuộc tính 1 làm tên thuộc tính mới 1,... Từ tên quan hệ; Hãy chỉ ra cách hoạt động của toán tử này với một ví dụ. Hãy để sơ đồ mối quan hệ đã quen thuộc với chúng ta được đưa ra: học lực (Số sổ điểm, Học kỳ, Mã môn học, Xếp hạng, Ngày); Để chúng tôi có lệnh thay đổi tên của một số thuộc tính, cụ thể là thay vì "Số sổ tài khoản" thì nên có "Số tài khoản" và thay vì "Điểm" - "Điểm". Hãy viết ra câu lệnh Select thực hiện thao tác đổi tên này sẽ trông như thế nào: Chọn sổ ghi chép như Số thứ tự, Học kỳ, Mã môn học, Hạng như Điểm, Ngày tháng Từ học lực; Do đó, kết quả của việc áp dụng toán tử này sẽ là một lược đồ quan hệ mới khác với lược đồ quan hệ "Thành tích" ban đầu về tên của hai thuộc tính. 3. Hoạt động nhị phân trong ngôn ngữ của truy vấn có cấu trúc Giống như các phép toán một ngôi, các phép toán nhị phân cũng có cách triển khai riêng của chúng trong ngôn ngữ truy vấn có cấu trúc hoặc SQL. Vì vậy, chúng ta hãy xem xét việc triển khai bằng ngôn ngữ này của các phép toán nhị phân mà chúng ta đã thông qua, cụ thể là các phép toán liên hợp, giao nhau, sự khác biệt, tích Descartes, phép nối tự nhiên, phép nối bên trong và bên trái, bên phải, toàn bộ bên ngoài. 1. Hoạt động công đoàn. Để thực hiện phép toán kết hợp hai quan hệ, cần sử dụng đồng thời hai toán tử Chọn, mỗi toán tử tương ứng với một trong các toán hạng-quan hệ ban đầu. Và một thao tác đặc biệt cần được áp dụng cho hai câu lệnh Chọn cơ bản này liên hiệp. Xem xét tất cả những điều trên, hãy viết ra hoạt động liên hợp sẽ trông như thế nào bằng cách sử dụng ngữ nghĩa của ngôn ngữ truy vấn có cấu trúc: Chọn liệt kê các tên thuộc tính của quan hệ 1 Từ tên quan hệ 1 liên hiệp Chọn liệt kê các tên thuộc tính của quan hệ 2 Từ tên quan hệ 2; Điều quan trọng cần lưu ý là danh sách tên thuộc tính của hai mối quan hệ đang được nối phải tham chiếu đến các thuộc tính của các loại tương thích và được liệt kê theo thứ tự nhất quán. Nếu yêu cầu này không được đáp ứng, yêu cầu của bạn không thể được thực hiện và máy tính sẽ hiển thị thông báo lỗi. Nhưng điều thú vị cần lưu ý là bản thân tên của các thuộc tính trong các mối quan hệ này có thể khác nhau. Trong trường hợp này, quan hệ kết quả được gán các tên thuộc tính được chỉ định trong câu lệnh Chọn đầu tiên. Bạn cũng cần biết rằng việc sử dụng phép toán Union sẽ tự động loại trừ tất cả các bộ giá trị trùng lặp khỏi quan hệ kết quả. Do đó, nếu bạn cần tất cả các hàng trùng lặp được giữ nguyên trong kết quả cuối cùng, thay vì hoạt động Union, bạn nên sử dụng một sửa đổi của hoạt động này - hoạt động Liên minh tất cả. Trong trường hợp này, phép toán kết hợp hai quan hệ sẽ giống như sau: Chọn liệt kê các tên thuộc tính của quan hệ 1 Từ tên quan hệ 1 Liên minh tất cả Chọn liệt kê các tên thuộc tính của quan hệ 2 Từ tên quan hệ 2; Trong trường hợp này, các bộ giá trị trùng lặp sẽ không bị xóa khỏi quan hệ kết quả. Sử dụng ký hiệu đã đề cập trước đó cho các phần tử tùy chọn và tùy chọn trong câu lệnh Chọn, chúng tôi viết dạng tổng quát nhất của hoạt động nối hai quan hệ trong ngôn ngữ truy vấn có cấu trúc: Chọn liệt kê các tên thuộc tính của quan hệ 1 Từ tên quan hệ 1 Liên minh [Tất cả] Chọn liệt kê các tên thuộc tính của quan hệ 2 Từ tên quan hệ 2; 2. Vận hành nút giao. Hoạt động của giao điểm và hoạt động của sự khác biệt của hai quan hệ trong ngôn ngữ truy vấn có cấu trúc được thực hiện theo cách tương tự (chúng tôi coi là phương pháp biểu diễn đơn giản nhất, vì phương pháp càng đơn giản, càng tiết kiệm, phù hợp và do đó, nhu cầu). Vì vậy, chúng tôi sẽ phân tích cách thực hiện thao tác giao cắt bằng cách sử dụng chìa khóa. Phương pháp này liên quan đến sự tham gia của hai cấu trúc Chọn, nhưng chúng không bằng nhau (như trong biểu diễn của phép toán liên hợp), một trong số chúng là "cấu trúc tiềm thức", "chu trình con". Toán tử như vậy thường được gọi là truy vấn con. Vì vậy, giả sử chúng ta có hai lược đồ quan hệ (R1 và R2), được định nghĩa gần như sau: R1 (chìa khóa,...) và R2 (chìa khóa,...); Khi ghi lại thao tác này, chúng tôi cũng sẽ sử dụng tùy chọn đặc biệt in, theo nghĩa đen có nghĩa là "trong" hoặc (như trong trường hợp cụ thể này) "chứa trong". Vì vậy, tính đến tất cả những điều trên, hoạt động của giao điểm của hai quan hệ sử dụng ngôn ngữ truy vấn có cấu trúc sẽ được viết như sau: Chọn * Từ R1 Ở đâu chốt vào (Chọn chìa khóa Từ R2); Như vậy, chúng ta thấy rằng truy vấn con trong trường hợp này sẽ là toán tử trong dấu ngoặc đơn. Truy vấn con này trong trường hợp của chúng ta trả về danh sách các giá trị khóa của quan hệ R2. Và, như sau từ ký hiệu của chúng tôi về các toán tử, từ việc phân tích điều kiện lựa chọn, chỉ những bộ giá trị của quan hệ R mới rơi vào quan hệ kết quả1, có khóa được chứa trong danh sách các khóa của quan hệ R2. Có nghĩa là, trong quan hệ cuối cùng, nếu chúng ta nhớ lại định nghĩa về giao của hai quan hệ, chỉ những bộ giá thuộc về cả hai quan hệ sẽ còn lại. 3. Hoạt động khác biệt. Như đã đề cập trước đó, phép toán đơn nguyên của sự khác biệt của hai quan hệ được thực hiện tương tự như phép toán giao nhau. Ở đây, ngoài truy vấn chính với toán tử Chọn, một truy vấn phụ, thứ hai được sử dụng - cái gọi là truy vấn phụ. Nhưng khác với việc thực hiện thao tác trước đó, khi thực hiện thao tác khác biệt, cần sử dụng một từ khóa khác, cụ thể là không, trong bản dịch theo nghĩa đen có nghĩa là "không có trong" hoặc (vì nó thích hợp để dịch trong trường hợp của chúng tôi đang được xem xét) - "không có trong". Vì vậy, như trong ví dụ trước, chúng ta có hai lược đồ quan hệ (R1 và R2), được đưa ra gần đúng bởi: R1 (chìa khóa,...) và R2 (chìa khóa,...); Như bạn có thể thấy, các thuộc tính chính lại được đặt trong số các thuộc tính của các quan hệ này. Do đó, chúng tôi nhận được biểu mẫu sau để biểu diễn hoạt động khác biệt trong ngôn ngữ truy vấn có cấu trúc: lựa chọn* Từ R1 Ở đâu chìa khóa không (Chọn chìa khóa Từ R2); Do đó, chỉ những bộ giá trị của quan hệ R1, có khóa không được chứa trong danh sách các khóa của quan hệ R2. Nếu chúng ta xem xét ký hiệu theo nghĩa đen, thì nó thực sự hóa ra rằng từ quan hệ R1 "trừ" tỷ lệ R2. Từ đây, chúng tôi kết luận rằng điều kiện lựa chọn trong toán tử này được viết đúng (xét cho cùng, định nghĩa về sự khác biệt của hai quan hệ được thực hiện) và việc sử dụng các khóa, như trong trường hợp thực hiện phép toán giao nhau, là hoàn toàn hợp lý. . Hai cách sử dụng "key method" mà chúng ta đã thấy là phổ biến nhất. Điều này kết thúc nghiên cứu về việc sử dụng các khóa trong việc xây dựng các toán tử đại diện cho các quan hệ. Tất cả các phép toán nhị phân còn lại của đại số quan hệ được viết theo những cách khác. 4. Hoạt động sản phẩm Descartes Như chúng ta đã nhớ từ các bài giảng trước, tích Descartes của hai toán hạng-quan hệ được tạo thành một tập hợp tất cả các cặp giá trị có thể có của các bộ giá trị được đặt tên trên các thuộc tính. Do đó, trong ngôn ngữ truy vấn có cấu trúc, phép toán tích Descartes được triển khai bằng cách sử dụng phép nối chéo, được biểu thị bằng từ khóa tham gia chéo, nghĩa đen được dịch là "tham gia chéo" hoặc "tham gia chéo". Chỉ có một toán tử Chọn trong cấu trúc đại diện cho hoạt động sản phẩm Descartes trong Ngôn ngữ truy vấn có cấu trúc và nó có dạng sau: lựa chọn* Từ R1 tham gia chéo R2 Đây R1 và R2 - tên của các toán hạng-quan hệ ban đầu. Quyền mua tham gia chéo đảm bảo rằng quan hệ kết quả sẽ chứa tất cả các thuộc tính (tất cả, vì dòng đầu tiên của toán tử chứa dấu "*") tương ứng với tất cả các cặp bộ giá trị của quan hệ R1 và R2. Điều rất quan trọng là phải nhớ một đặc điểm của việc thực hiện phép toán tích Descartes. Đặc điểm này là hệ quả của định nghĩa phép toán nhị phân của tích Descartes. Nhớ lại nó: r4(S4) = r1(S1)xr2(S2) = {t (S1 ∪S2) | t [S1] ∈ r1 & t (S2) ∈ r2}, S1 ∩S2= ∅; Như có thể thấy từ định nghĩa trên, các cặp bộ giá trị được hình thành với các lược đồ quan hệ nhất thiết không giao nhau. Do đó, khi làm việc trong ngôn ngữ truy vấn có cấu trúc SQL, người ta luôn quy định rằng các quan hệ toán hạng ban đầu không được có tên thuộc tính trùng khớp. Nhưng nếu các mối quan hệ này vẫn có cùng tên, tình huống hiện tại có thể dễ dàng được giải quyết bằng cách sử dụng thao tác đổi tên thuộc tính, tức là trong những trường hợp như vậy, bạn chỉ cần sử dụng tùy chọn as, đã được đề cập trước đó. Hãy xem xét một ví dụ trong đó chúng ta cần tìm tích Descartes của hai quan hệ có một số tên thuộc tính giống nhau. Vì vậy, cho các quan hệ sau: R1 (A, B), R2 (B,C); Chúng tôi thấy rằng các thuộc tính R1.B và R2.B có cùng tên. Với lưu ý này, câu lệnh Select triển khai thao tác tích số Descartes này trong ngôn ngữ truy vấn có cấu trúc sẽ trông giống như sau: Chọn A, R1.B as B1,R2.B as B2,C Từ R1 tham gia chéo R2; Do đó, sử dụng tùy chọn đổi tên như, máy sẽ không có "câu hỏi" về tên khớp của hai quan hệ toán hạng ban đầu. 5. Hoạt động tham gia bên trong Thoạt nhìn, có vẻ lạ khi chúng ta coi phép toán liên kết bên trong trước phép toán nối tự nhiên, bởi vì khi chúng ta trải qua các phép toán nhị phân, mọi thứ lại theo chiều ngược lại. Nhưng bằng cách phân tích biểu thức của các phép toán trong ngôn ngữ truy vấn có cấu trúc, người ta có thể đi đến kết luận rằng phép toán nối tự nhiên là một trường hợp đặc biệt của phép toán nối bên trong. Đó là lý do tại sao nó là hợp lý để xem xét các hoạt động theo thứ tự đó. Vì vậy, trước tiên, hãy nhớ lại định nghĩa của hoạt động nối bên trong mà chúng ta đã xem qua trước đó: r1(S1)x P r2(S2) = σ (r1 xr2), S1 ∩ S2 = ∅. Đối với chúng tôi, trong định nghĩa này, điều đặc biệt quan trọng là các lược đồ được xem xét của các toán hạng-quan hệ S1 và S2 không được cắt nhau. Để triển khai hoạt động nối bên trong bằng ngôn ngữ truy vấn có cấu trúc, có một tùy chọn đặc biệt tham gia bên trong, được dịch theo nghĩa đen từ tiếng Anh là "tham gia bên trong" hoặc "tham gia bên trong". Câu lệnh Select trong trường hợp hoạt động nối bên trong sẽ giống như sau: lựa chọn* Từ R1 tham gia bên trong R2; Ở đây, như trước đây, R1 và R2 - tên của các toán hạng-quan hệ ban đầu. Khi thực hiện thao tác này, các lược đồ của các toán hạng quan hệ không được phép giao nhau. 6. Hoạt động tham gia tự nhiên Như chúng ta đã nói, phép toán liên kết tự nhiên là một trường hợp đặc biệt của phép toán liên kết bên trong. Tại sao? Có, bởi vì trong quá trình thực hiện phép nối tự nhiên, các bộ giá trị của quan hệ toán hạng ban đầu được nối theo một điều kiện đặc biệt. Cụ thể là, với điều kiện bình đẳng của các bộ giá trị tại giao điểm của các toán hạng-quan hệ, trong khi với hoạt động của phép toán nối bên trong, tình huống như vậy không thể được phép xảy ra. Vì thao tác kết hợp tự nhiên mà chúng tôi đang xem xét là một trường hợp đặc biệt của thao tác kết hợp bên trong, cùng một tùy chọn được sử dụng để triển khai nó như đối với thao tác được xem xét trước đó, tức là tùy chọn tham gia bên trong. Nhưng vì khi biên dịch toán tử Chọn cho phép toán kết hợp tự nhiên, cũng cần phải tính đến điều kiện bình đẳng của các bộ giá trị của quan hệ toán hạng ban đầu tại giao điểm của các lược đồ của chúng, khi đó ngoài tùy chọn được chỉ ra, từ khóa được áp dụng on. Được dịch từ tiếng Anh, nó có nghĩa đen là "trên", và liên quan đến nghĩa của chúng ta, nó có thể được dịch là "đối tượng". Dạng chung của câu lệnh Chọn để thực hiện một thao tác kết hợp tự nhiên như sau: lựa chọn* Từ tên quan hệ 1 tham gia bên trong tên quan hệ 2 on điều kiện bình đẳng tuple; Hãy xem xét một ví dụ. Cho hai quan hệ: R1 (A, B, C), R2 (B, C, D); Phép toán kết hợp tự nhiên của các quan hệ này có thể được thực hiện bằng cách sử dụng toán tử sau: Chọn A, R1.B,R1.ĐĨA CD Từ R1 tham gia bên trong R2 on R1.B=R2.B và R1.C=R2.C Kết quả của thao tác này, các thuộc tính được chỉ định trong dòng đầu tiên của toán tử Chọn, tương ứng với các bộ giá trị bằng nhau tại giao điểm được chỉ định, sẽ được hiển thị trong kết quả. Cần lưu ý rằng ở đây chúng ta đang đề cập đến các thuộc tính chung B và C, không chỉ bằng tên. Điều này phải được thực hiện không phải vì lý do tương tự như trong trường hợp thực hiện phép toán tích Descartes, mà bởi vì nếu không sẽ không rõ ràng chúng tham chiếu đến mối quan hệ nào. Điều thú vị là từ ngữ được sử dụng của điều kiện nối (R1.B=R2.B và R1.C=R2.C) giả định rằng các thuộc tính được chia sẻ của các quan hệ giá trị Null đã kết nối là không được phép. Điều này được tích hợp vào hệ thống Ngôn ngữ truy vấn có cấu trúc ngay từ đầu. 7. Hoạt động nối bên ngoài bên trái Biểu thức ngôn ngữ truy vấn có cấu trúc SQL của phép toán nối ngoài bên trái có được từ việc triển khai phép toán nối tự nhiên bằng cách thay thế từ khóa bên trong mỗi từ khóa bên trái bên trái. Do đó, trong ngôn ngữ của các truy vấn có cấu trúc, hoạt động này sẽ được viết như sau: lựa chọn* Từ tên quan hệ 1 tham gia bên ngoài bên trái tên quan hệ 2 on điều kiện bình đẳng tuple; 8. Hoạt động nối bên ngoài bên phải Biểu thức ngôn ngữ truy vấn có cấu trúc cho thao tác nối ngoài bên phải có được khi thực hiện thao tác nối tự nhiên bằng cách thay thế từ khóa bên trong mỗi từ khóa bên phải bên ngoài. Vì vậy, chúng ta hiểu rằng trong ngôn ngữ truy vấn có cấu trúc SQL, hoạt động của phép nối bên phải bên phải sẽ được viết như sau: lựa chọn* Từ tên quan hệ 1 tham gia bên ngoài bên phải tên quan hệ 2 on điều kiện bình đẳng tuple; 9. Hoạt động tham gia bên ngoài đầy đủ Biểu thức Ngôn ngữ truy vấn có cấu trúc cho hoạt động nối bên ngoài đầy đủ nhận được, như trong hai trường hợp trước, từ biểu thức cho hoạt động nối tự nhiên bằng cách thay thế từ khóa bên trong mỗi từ khóa bên ngoài đầy đủ. Do đó, trong ngôn ngữ của truy vấn có cấu trúc, hoạt động này sẽ được viết như sau: lựa chọn* Từ tên quan hệ 1 tham gia đầy đủ bên ngoài tên quan hệ 2 on điều kiện bình đẳng tuple; Rất tiện lợi là các tùy chọn này được tích hợp vào ngữ nghĩa của ngôn ngữ truy vấn có cấu trúc SQL, bởi vì nếu không thì mỗi lập trình viên sẽ phải xuất chúng một cách độc lập và nhập chúng vào mỗi cơ sở dữ liệu mới. 4. Sử dụng truy vấn con Như có thể hiểu từ tài liệu được đề cập, khái niệm "truy vấn con" trong ngôn ngữ truy vấn có cấu trúc là một khái niệm cơ bản và được áp dụng khá rộng rãi (đôi khi, chúng còn được gọi là truy vấn SQL. Thật vậy, việc thực hành lập trình và làm việc với cơ sở dữ liệu cho thấy rằng việc biên dịch một hệ thống các truy vấn con để giải quyết các nhiệm vụ liên quan khác nhau - một hoạt động bổ ích hơn nhiều so với một số phương pháp làm việc với thông tin có cấu trúc khác. Và sử dụng. Hãy để có một đoạn sau của một cơ sở dữ liệu nhất định, có thể được sử dụng trong bất kỳ cơ sở giáo dục nào: Vật phẩm (Mã hàng, Tên mục); Sinh viên (ghi số sách, Họ và tên); Phiên họp (Mã môn học, số sổ điểm, Lớp); Hãy xây dựng một truy vấn SQL trả về một câu lệnh cho biết số sách lớp, họ và tên viết tắt và điểm của học sinh cho môn học có tên "Cơ sở dữ liệu". Các trường đại học cần nhận được thông tin như vậy luôn luôn và kịp thời, vì vậy truy vấn sau đây có lẽ là đơn vị lập trình phổ biến nhất sử dụng cơ sở dữ liệu như vậy. Để thuận tiện, hãy giả sử thêm rằng các thuộc tính "Họ", "Tên" và "Chữ viết tắt" không cho phép các giá trị Null và không trống. Yêu cầu này khá dễ hiểu và logic, bởi vì dữ liệu đầu tiên của một tân sinh viên được nhập vào cơ sở dữ liệu của bất kỳ cơ sở giáo dục nào là dữ liệu về họ, tên và họ của người đó. Và không cần phải nói rằng không thể có một mục nhập trong cơ sở dữ liệu có chứa dữ liệu về một học sinh, nhưng đồng thời tên của anh ta không được biết đến. Lưu ý rằng thuộc tính "Tên mặt hàng" của lược đồ mối quan hệ "Mặt hàng" là một khóa, vì vậy, như sau từ định nghĩa (sẽ nói thêm về điều này sau), tất cả các tên mặt hàng là duy nhất. Điều này cũng có thể hiểu được mà không cần giải thích sự đại diện của khóa, bởi vì tất cả các môn học được giảng dạy trong một cơ sở giáo dục phải có và có tên khác nhau. Bây giờ, trước khi bắt đầu biên dịch văn bản của chính toán tử, chúng tôi sẽ giới thiệu hai hàm sẽ hữu ích cho chúng tôi khi chúng tôi tiếp tục. Đầu tiên, chúng ta sẽ cần hàm Tỉa, được viết là Trim ("string"), có nghĩa là, đối số của hàm này là một chuỗi. Chức năng này làm gì? Chúng trả về chính đối số không có khoảng trắng ở đầu và cuối dòng này, tức là, hàm này được sử dụng, chẳng hạn, trong các trường hợp: Trim ("Bogucharnikov") hoặc Trim ("Maksimenko"), khi sau hoặc trước đối số là giá trị thêm một vài không gian. Và thứ hai, cũng cần phải xem xét hàm Left, được viết Left (chuỗi, số), tức là một hàm đã có hai đối số, một trong số đó, như trước đây, là một chuỗi. Đối số thứ hai của nó là một số, nó cho biết có bao nhiêu ký tự từ phía bên trái của chuỗi sẽ được xuất ra trong kết quả. Ví dụ, kết quả của hoạt động: Left ("Mikhail, 1") + "." + Bên trái ("Zinovievich, 1") sẽ là tên viết tắt "M. Z." Nó là để hiển thị tên viết tắt của sinh viên mà chúng tôi sẽ sử dụng hàm này trong truy vấn của chúng tôi. Vì vậy, hãy bắt đầu biên dịch truy vấn mong muốn. Đầu tiên, hãy tạo một truy vấn bổ trợ nhỏ, sau đó chúng tôi sử dụng trong truy vấn chính, chính: Chọn Số điểm, Lớp Từ Phiên họp Ở đâu Mã hàng = (Chọn Mã hàng Từ Đối tượng Ở đâu Tên mục = "Cơ sở dữ liệu") as "Ước tính" Cơ sở dữ liệu "; Sử dụng tùy chọn as ở đây có nghĩa là chúng tôi đã đặt bí danh cho truy vấn này là "Ước tính cơ sở dữ liệu". Chúng tôi đã làm điều này để thuận tiện cho công việc tiếp theo với yêu cầu này. Tiếp theo, trong truy vấn này, một truy vấn con: Chọn Mã hàng Từ Đối tượng Ở đâu Tên mục = "Cơ sở dữ liệu"; cho phép bạn chọn từ mối quan hệ "Phiên" những bộ giá trị liên quan đến chủ đề đang được xem xét, tức là cơ sở dữ liệu. Điều thú vị là truy vấn con bên trong này chỉ có thể trả về một giá trị, vì thuộc tính "Tên mặt hàng" là khóa của mối quan hệ "Mặt hàng", tức là tất cả các giá trị của nó là duy nhất. Và toàn bộ truy vấn "Điểm" Cơ sở dữ liệu "cho phép bạn trích xuất từ dữ liệu mối quan hệ" Phiên "về những sinh viên đó (số điểm và điểm của họ) thỏa mãn điều kiện được chỉ định trong truy vấn con, tức là thông tin về chủ đề được gọi là" Cơ sở dữ liệu ". Bây giờ chúng ta sẽ đưa ra yêu cầu chính, sử dụng kết quả đã nhận được. Chọn Sinh viên. ghi số sách, Tỉa (Họ) + "" + Còn lại (Tên, 1) + "." + Còn lại (Viết tắt, 1) + "."as Tên đầy đủ, Ước tính "Cơ sở dữ liệu". Lớp Từ Học sinh tham gia bên trong ( Chọn Số điểm, Lớp Từ Phiên họp Ở đâu Mã hàng = (Chọn Mã hàng Từ Đối tượng Ở đâu Tên mục = "Cơ sở dữ liệu") ) như "Ước tính" Cơ sở dữ liệu ". on Sinh viên. Bảng điểm # = "Cơ sở dữ liệu" điểm. Ghi số sách. Vì vậy, trước tiên, chúng tôi liệt kê các thuộc tính sẽ cần được hiển thị sau khi hoàn thành truy vấn. Cần lưu ý rằng thuộc tính "Số điểm" là từ quan hệ Học sinh, từ đó - các thuộc tính "Họ", "Tên" và "Chữ viết tắt". Đúng, hai thuộc tính cuối cùng không được suy luận đầy đủ, mà chỉ là các chữ cái đầu tiên. Chúng tôi cũng đề cập đến thuộc tính 'Điểm' từ truy vấn 'Điểm Cơ sở dữ liệu' mà chúng tôi đã nhập trước đó. Chúng tôi chọn tất cả các thuộc tính này từ phép nối bên trong của quan hệ "Sinh viên" và truy vấn "Điểm cơ sở dữ liệu". Sự liên kết bên trong này, như chúng ta có thể thấy, được chúng tôi thực hiện với điều kiện là các số của sổ ghi chép bằng nhau. Kết quả của hoạt động liên kết bên trong này, điểm được thêm vào quan hệ Học sinh. Cần lưu ý rằng vì các thuộc tính "Last Name", "First Name" và "Patronymic" theo điều kiện không cho phép giá trị Null và không trống, công thức tính toán trả về thuộc tính "Name" (Tỉa (Họ) + "" + Còn lại (Tên, 1) + "." + Còn lại (Viết tắt, 1) + "."as Tên đầy đủ), tương ứng, không yêu cầu kiểm tra bổ sung, được đơn giản hóa. Bài giảng số 7. Các quan hệ cơ bản Như chúng ta đã biết, cơ sở dữ liệu giống như một loại vật chứa, mục đích chính là lưu trữ dữ liệu được trình bày dưới dạng các mối quan hệ. Bạn cần biết rằng, tùy thuộc vào bản chất và cấu trúc của chúng, các mối quan hệ được chia thành: 1) các mối quan hệ cơ bản; 2) mối quan hệ ảo. Các mối quan hệ dạng xem cơ sở chỉ chứa dữ liệu độc lập và không thể được thể hiện theo bất kỳ mối quan hệ cơ sở dữ liệu nào khác. Trong các hệ quản trị cơ sở dữ liệu thương mại, các mối quan hệ cơ bản thường được gọi đơn giản là những cái bàn ngược lại với các biểu diễn tương ứng với khái niệm quan hệ ảo. Trong khóa học này, chúng tôi sẽ chỉ xem xét một số chi tiết các mối quan hệ cơ bản, các kỹ thuật chính và nguyên tắc làm việc với chúng. 1. Các kiểu dữ liệu cơ bản Các kiểu dữ liệu, như mối quan hệ, được chia thành căn bản и ảo. (Chúng ta sẽ nói về các kiểu dữ liệu ảo sau một chút; chúng ta sẽ dành một chương riêng cho chủ đề này.) Các kiểu dữ liệu cơ bản - đây là bất kỳ kiểu dữ liệu nào được xác định ban đầu trong các hệ quản trị cơ sở dữ liệu, nghĩa là hiển thị ở đó theo mặc định (trái ngược với kiểu dữ liệu do người dùng xác định, chúng tôi sẽ phân tích ngay sau khi chuyển qua kiểu dữ liệu cơ sở). Trước khi tiếp tục xem xét các kiểu dữ liệu cơ bản thực tế, chúng tôi liệt kê các loại dữ liệu nói chung: 1) dữ liệu số; 2) dữ liệu logic; 3) dữ liệu chuỗi; 4) dữ liệu xác định ngày và giờ; 5) dữ liệu nhận dạng. Theo mặc định, các hệ quản trị cơ sở dữ liệu đã giới thiệu một số kiểu dữ liệu phổ biến nhất, mỗi kiểu dữ liệu thuộc một trong các kiểu dữ liệu được liệt kê. Hãy gọi cho họ. 1. Trong số kiểu dữ liệu được phân biệt: 1) Số nguyên. Từ khóa này thường biểu thị một kiểu dữ liệu số nguyên; 2) Real, tương ứng với kiểu dữ liệu thực; 3) Số thập phân (n, m). Đây là một kiểu dữ liệu thập phân. Hơn nữa, trong ký hiệu n là một số cố định tổng số chữ số của một số, và m cho biết chúng có bao nhiêu ký tự sau dấu thập phân; 4) Tiền hoặc Tiền tệ, được giới thiệu đặc biệt để trình bày dữ liệu thuận tiện cho loại dữ liệu tiền tệ. 2. Trong hợp lý kiểu dữ liệu thường chỉ cấp phát một kiểu cơ bản, đây là Logical. 3. Sợi dây kiểu dữ liệu có bốn kiểu cơ bản (tất nhiên, có nghĩa là những kiểu phổ biến nhất): 1) Bit (n). Đây là các chuỗi bit có độ dài cố định n; 2) Varbit (n). Đây cũng là các chuỗi bit, nhưng có độ dài thay đổi không quá n bit; 3) Char (n). Đây là các chuỗi ký tự có độ dài không đổi n; 4) Varchar (n). Đây là các chuỗi ký tự, có độ dài thay đổi không quá n ký tự. 4. Loại ngày và giờ bao gồm các kiểu dữ liệu cơ bản sau: 1) Kiểu dữ liệu ngày tháng; 2) Thời gian - kiểu dữ liệu thể hiện thời gian trong ngày; 3) Ngày-giờ là một kiểu dữ liệu thể hiện cả ngày và giờ. 5. Nhận dạng Kiểu dữ liệu chỉ chứa một kiểu được bao gồm theo mặc định trong hệ quản trị cơ sở dữ liệu và đó là GUID (Định danh duy nhất trên toàn cầu). Cần lưu ý rằng tất cả các kiểu dữ liệu cơ bản có thể có các biến thể của các phạm vi biểu diễn dữ liệu khác nhau. Để đưa ra một ví dụ, các biến thể của kiểu dữ liệu số nguyên bốn byte có thể là kiểu dữ liệu tám byte (bigint) và hai byte (smallint). Hãy nói riêng về kiểu dữ liệu GUID cơ bản. Loại này nhằm lưu trữ các giá trị mười sáu byte của cái gọi là số nhận dạng duy nhất trên toàn cầu. Tất cả các giá trị khác nhau của mã định danh này được tạo tự động khi một hàm tích hợp đặc biệt được gọi Id mới(). Việc chỉ định này xuất phát từ cụm từ tiếng Anh đầy đủ là New Identification, có nghĩa đen là "giá trị định danh mới". Mỗi giá trị định danh được tạo trên một máy tính cụ thể là duy nhất trong tất cả các máy tính được sản xuất. Đặc biệt, mã định danh GUID được sử dụng để tổ chức sao chép cơ sở dữ liệu, tức là khi tạo bản sao của một số cơ sở dữ liệu hiện có. Các GUID như vậy có thể được sử dụng bởi các nhà phát triển cơ sở dữ liệu cùng với các loại cơ bản khác. Vị trí trung gian giữa loại GUID và các loại cơ sở khác bị chiếm bởi một loại cơ sở đặc biệt khác - loại phản đối. Một từ khóa đặc biệt được sử dụng để chỉ định dữ liệu thuộc loại này. Bộ đếm (x0, ∆x), dịch theo nghĩa đen từ tiếng Anh và có nghĩa là "bộ đếm". Tham số x0 đặt giá trị ban đầu và Δx - bước tăng dần. Giá trị của loại Bộ đếm này nhất thiết phải là số nguyên. Cần lưu ý rằng làm việc với kiểu dữ liệu cơ bản này bao gồm một số tính năng rất thú vị. Ví dụ: các giá trị của loại Bộ đếm này không được đặt, như chúng ta đã quen khi làm việc với tất cả các kiểu dữ liệu khác, chúng được tạo theo yêu cầu, giống như đối với các giá trị của loại mã định danh duy nhất trên toàn cầu. Cũng không bình thường là kiểu bộ đếm chỉ có thể được chỉ định khi xác định bảng và chỉ khi đó! Loại này không thể được sử dụng trong mã. Bạn cũng cần nhớ rằng khi xác định bảng, loại bộ đếm chỉ có thể được chỉ định cho một cột. Giá trị dữ liệu bộ đếm được tạo tự động khi các hàng được chèn vào. Hơn nữa, thế hệ này được thực hiện mà không lặp lại, do đó bộ đếm sẽ luôn nhận dạng duy nhất từng dòng. Nhưng điều này tạo ra một số bất tiện khi làm việc với các bảng chứa dữ liệu bộ đếm. Ví dụ, nếu dữ liệu trong mối quan hệ được cung cấp bởi bảng thay đổi và chúng phải bị xóa hoặc hoán đổi, các giá trị bộ đếm có thể dễ dàng "nhầm lẫn giữa các thẻ", đặc biệt nếu một lập trình viên thiếu kinh nghiệm đang làm việc. Hãy để chúng tôi đưa ra một ví dụ minh họa một tình huống như vậy. Hãy cho bảng sau đại diện cho một số quan hệ được đưa ra, trong đó bốn hàng được nhập:
Bộ đếm tự động đặt tên duy nhất cho mỗi dòng mới. Và bây giờ chúng ta hãy xóa dòng thứ hai và thứ tư khỏi bảng, sau đó thêm một dòng bổ sung. Các thao tác này sẽ dẫn đến sự chuyển đổi bảng nguồn sau:
Do đó, bộ đếm đã loại bỏ các dòng thứ hai và thứ tư cùng với tên riêng của chúng, và không "gán" lại chúng cho các dòng mới, như người ta có thể mong đợi. Hơn nữa, hệ thống quản lý cơ sở dữ liệu sẽ không bao giờ cho phép bạn thay đổi giá trị của bộ đếm theo cách thủ công, cũng như nó sẽ không cho phép bạn khai báo nhiều bộ đếm trong một bảng cùng một lúc. Thông thường, bộ đếm được sử dụng làm vật thay thế, tức là khóa nhân tạo trong bảng. Thật thú vị khi biết rằng các giá trị duy nhất của bộ đếm bốn byte với tốc độ tạo một giá trị mỗi giây sẽ tồn tại hơn 100 năm. Hãy cho biết cách nó được tính toán: 1 năm = 365 ngày * 24 giờ * 60 giây * 60 giây <366 ngày * 24 giờ * 60 giây * 60 giây <225 c. 1 giây> 2-25 năm 24*8 giá trị / 1 giá trị / giây = 232 c> 27 năm> 100 năm. 2. Kiểu dữ liệu tùy chỉnh Kiểu dữ liệu tùy chỉnh khác với tất cả các kiểu cơ sở ở chỗ ban đầu nó không được xây dựng trong hệ quản trị cơ sở dữ liệu, nó không được khai báo là kiểu dữ liệu mặc định. Loại này có thể được tạo bởi bất kỳ người dùng và lập trình viên cơ sở dữ liệu nào phù hợp với yêu cầu và yêu cầu riêng của họ. Do đó, kiểu dữ liệu do người dùng định nghĩa là một kiểu con của một số kiểu cơ sở, nghĩa là, nó là kiểu cơ sở với một số hạn chế về tập giá trị cho phép. Trong ký hiệu mã giả, kiểu dữ liệu tùy chỉnh được tạo bằng cách sử dụng câu lệnh chuẩn sau: Tạo loại phụ tên loại phụ Kiểu tên loại cơ sở As ràng buộc kiểu con; Vì vậy, trong dòng đầu tiên, chúng ta phải chỉ định tên của kiểu dữ liệu mới, do người dùng xác định, ở dòng thứ hai - kiểu dữ liệu cơ bản hiện có nào mà chúng tôi lấy làm mô hình, tạo mô hình của riêng mình, và cuối cùng, ở dòng thứ ba - những hạn chế mà chúng ta cần thêm vào những hạn chế hiện có đối với tập giá trị của kiểu dữ liệu cơ sở - mẫu. Ràng buộc kiểu con được viết như một điều kiện phụ thuộc vào tên của kiểu con đang được định nghĩa. Để hiểu rõ hơn về cách hoạt động của câu lệnh Create, hãy xem xét ví dụ sau. Giả sử chúng ta cần tạo kiểu dữ liệu chuyên biệt của riêng mình, chẳng hạn, để làm việc trong thư. Đây sẽ là kiểu làm việc với dữ liệu như số mã zip. Các số của chúng tôi sẽ khác với các số có sáu chữ số thập phân thông thường ở chỗ chúng chỉ có thể là số dương. Hãy viết một toán tử để tạo kiểu con mà chúng ta cần: Tạo loại phụ Mã bưu điện Kiểu thập phân (6, 0) As Mã bưu điện> 0. Tại sao chúng tôi chọn số thập phân (6, 0)? Nhớ lại hình thức thông thường của chỉ số, chúng ta thấy rằng những số như vậy phải bao gồm sáu số nguyên từ XNUMX đến chín. Đó là lý do tại sao chúng tôi lấy kiểu thập phân làm kiểu dữ liệu cơ sở. Điều tò mò cần lưu ý rằng, nói chung, điều kiện áp đặt cho kiểu dữ liệu cơ sở, tức là ràng buộc kiểu con, có thể chứa các kết nối logic không, và, hoặc và nói chung là một biểu thức của bất kỳ độ phức tạp tùy ý nào. Các kiểu con dữ liệu tùy chỉnh được xác định theo cách này có thể được sử dụng tự do cùng với các kiểu dữ liệu cơ bản khác cả trong mã chương trình và khi xác định kiểu dữ liệu trong cột bảng, tức là kiểu dữ liệu cơ bản và kiểu dữ liệu người dùng hoàn toàn bình đẳng khi làm việc với chúng. Trong môi trường phát triển trực quan, chúng xuất hiện trong danh sách các kiểu hợp lệ cùng với các kiểu dữ liệu cơ sở khác. Khả năng chúng ta có thể cần một kiểu dữ liệu không có tài liệu (do người dùng xác định) khi thiết kế một cơ sở dữ liệu mới của riêng mình là khá cao. Thật vậy, theo mặc định, chỉ những kiểu dữ liệu phổ biến nhất mới được đưa vào hệ quản trị cơ sở dữ liệu, tương ứng, phù hợp để giải quyết các tác vụ phổ biến nhất. Khi biên dịch cơ sở dữ liệu môn học, hầu như không thể thực hiện được nếu không thiết kế các kiểu dữ liệu của riêng bạn. Nhưng, thật kỳ lạ, với xác suất ngang nhau, chúng ta có thể cần phải loại bỏ kiểu con mà chúng ta đã tạo, để không làm rối và phức tạp mã. Để làm điều này, các hệ quản trị cơ sở dữ liệu thường có một toán tử đặc biệt được tích hợp sẵn. rơi vãi, có nghĩa là "loại bỏ". Dạng chung của toán tử này để loại bỏ các loại tùy chỉnh không cần thiết như sau: Thả loại phụ tên của loại tùy chỉnh; Các loại dữ liệu tùy chỉnh thường được khuyến nghị cho các loại phụ đủ chung chung. 3. Giá trị mặc định Hệ quản trị cơ sở dữ liệu có thể có khả năng tạo bất kỳ giá trị mặc định tùy ý nào hoặc, như chúng còn được gọi là giá trị mặc định. Thao tác này trong bất kỳ môi trường lập trình nào cũng có sức nặng khá lớn, bởi vì trong hầu hết mọi tác vụ, có thể cần phải đưa vào các hằng số, các giá trị mặc định bất biến. Để tạo mặc định trong hệ quản trị cơ sở dữ liệu, hàm đã quen thuộc với chúng ta từ việc chuyển kiểu dữ liệu do người dùng định nghĩa được sử dụng Tạo. Chỉ trong trường hợp tạo giá trị mặc định, một từ khóa bổ sung cũng được sử dụng mặc định, có nghĩa là "mặc định". Nói cách khác, để tạo giá trị mặc định trong cơ sở dữ liệu hiện có, bạn phải sử dụng câu lệnh sau: Tạo mặc định tên mặc định As biểu thức hằng số; Rõ ràng là thay cho một giá trị không đổi khi áp dụng toán tử này, bạn cần viết giá trị hoặc biểu thức mà chúng ta muốn làm giá trị hoặc biểu thức mặc định. Và, tất nhiên, chúng ta cần quyết định đặt tên nào sẽ thuận tiện cho chúng ta khi sử dụng nó trong cơ sở dữ liệu của mình và viết tên này vào dòng đầu tiên của toán tử. Lưu ý rằng trong trường hợp cụ thể này, câu lệnh Tạo này tuân theo cú pháp Transact-SQL được tích hợp trong hệ thống Microsoft SQL Server. Vậy chúng ta có những gì? Chúng tôi đã suy luận rằng mặc định là một hằng số được đặt tên được lưu trữ trong cơ sở dữ liệu, giống như đối tượng của nó. Trong môi trường phát triển trực quan, các giá trị mặc định xuất hiện trong danh sách các giá trị mặc định được tô sáng. Đây là một ví dụ về việc tạo mặc định. Giả sử rằng để hoạt động chính xác cơ sở dữ liệu của chúng ta, cần có một hàm giá trị trong nó với ý nghĩa là thời gian tồn tại không giới hạn của một thứ gì đó. Sau đó, bạn cần nhập vào danh sách các giá trị của cơ sở dữ liệu này giá trị mặc định đáp ứng yêu cầu này. Điều này có thể là cần thiết, nếu chỉ vì mỗi lần bạn gặp phải biểu thức khá rườm rà này trong đoạn mã, bạn sẽ vô cùng bất tiện khi viết lại. Đó là lý do tại sao chúng ta sẽ sử dụng câu lệnh Create ở trên để tạo mặc định, với ý nghĩa là thời gian tồn tại không giới hạn của một thứ gì đó. Tạo mặc định "không giới hạn thời gian" As ‘9999-12-31 23: 59:59’ Cú pháp Transact-SQL cũng đã được sử dụng ở đây, theo đó các giá trị của hằng số ngày-giờ (trong trường hợp này là '9999-12-31 23:59:59') được viết dưới dạng chuỗi ký tự theo một hướng nhất định. Việc giải thích các chuỗi ký tự dưới dạng giá trị ngày giờ được xác định bởi ngữ cảnh mà các chuỗi được sử dụng. Ví dụ, trong trường hợp cụ thể của chúng tôi, đầu tiên giá trị giới hạn của năm được viết trong dòng không đổi, sau đó là thời gian. Tuy nhiên, đối với tất cả tính hữu dụng của chúng, các giá trị mặc định, giống như kiểu dữ liệu do người dùng xác định, đôi khi cũng có thể yêu cầu xóa chúng. Các hệ thống quản lý cơ sở dữ liệu thường có một vị từ được tích hợp sẵn đặc biệt, tương tự như một toán tử loại bỏ một kiểu dữ liệu do người dùng định nghĩa hơn mà không còn cần thiết nữa. Đây là một vị ngữ Rơi và bản thân toán tử trông giống như sau: Bỏ mặc định tên mặc định; 4. Thuộc tính ảo Tất cả các thuộc tính trong hệ quản trị cơ sở dữ liệu được phân chia (bằng cách tương tự tuyệt đối với các mối quan hệ) thành cơ bản và ảo. Cái gọi là thuộc tính cơ sở là các thuộc tính được lưu trữ cần được sử dụng nhiều lần và do đó, bạn nên lưu lại. Và, đến lượt nó, thuộc tính ảo không được lưu trữ, mà là các thuộc tính được tính toán. Nó có nghĩa là gì? Điều này có nghĩa là các giá trị của cái gọi là thuộc tính ảo không thực sự được lưu trữ, mà được tính toán nhanh chóng thông qua các thuộc tính cơ sở bằng các công thức nhất định. Trong trường hợp này, các miền của các thuộc tính ảo được tính toán được xác định tự động. Hãy đưa ra một ví dụ về một bảng xác định một quan hệ, trong đó hai thuộc tính là thông thường, cơ bản và thuộc tính thứ ba là ảo. Nó sẽ được tính toán theo một công thức được nhập đặc biệt.
Vì vậy, chúng ta thấy rằng các thuộc tính "Trọng lượng Kg" và "Giá chênh lệch trên Kg" là các thuộc tính cơ bản, vì chúng có giá trị thông thường và được lưu trữ trong cơ sở dữ liệu của chúng ta. Nhưng thuộc tính "Cost" là một thuộc tính ảo, vì nó được thiết lập bởi công thức tính toán của nó và sẽ không thực sự được lưu trữ trong cơ sở dữ liệu. Điều thú vị là, do bản chất của chúng, các thuộc tính ảo không thể nhận các giá trị mặc định và nói chung, khái niệm giá trị mặc định cho một thuộc tính ảo là vô nghĩa và do đó không thể áp dụng được. Và bạn cũng cần lưu ý rằng, mặc dù các miền của thuộc tính ảo được xác định tự động, nhưng loại giá trị được tính toán đôi khi cần được thay đổi từ giá trị hiện có sang một số giá trị khác. Để thực hiện điều này, ngôn ngữ của hệ quản trị cơ sở dữ liệu có một vị từ Chuyển đổi đặc biệt, với sự trợ giúp của nó, loại biểu thức được tính toán có thể được xác định lại. Convert là cái gọi là hàm chuyển đổi kiểu rõ ràng. Nó được viết như sau: Chuyển đổi (kiểu dữ liệu, biểu thức); Biểu thức là đối số thứ hai của hàm Convert sẽ được tính toán và xuất ra dưới dạng dữ liệu như vậy, kiểu dữ liệu được biểu thị bằng đối số đầu tiên của hàm. Hãy xem xét một ví dụ. Giả sử chúng ta cần tính giá trị của biểu thức "2 * 2", nhưng chúng ta cần xuất giá trị này không phải là số nguyên "4", mà là một chuỗi ký tự. Để thực hiện nhiệm vụ này, chúng tôi viết hàm Chuyển đổi sau: Chuyển đổi (Biểu đồ (1), 2 * 2). Như vậy, chúng ta có thể thấy rằng ký hiệu này của hàm Convert sẽ cho kết quả chính xác mà chúng ta cần. 5. Khái niệm về chìa khóa Khi khai báo lược đồ của một quan hệ cơ sở, các khai báo của nhiều khóa có thể được đưa ra. Chúng tôi đã gặp phải điều này nhiều lần trước đây. Cuối cùng, đã đến lúc nói chi tiết hơn về khóa quan hệ là gì và không bị giới hạn trong các cụm từ chung chung và định nghĩa gần đúng. Vì vậy, chúng ta hãy đưa ra một định nghĩa chặt chẽ về một khóa quan hệ. Khóa giản đồ mối quan hệ là một sơ đồ con của lược đồ ban đầu, bao gồm một hoặc nhiều thuộc tính mà nó được khai báo điều kiện duy nhất giá trị trong bộ giá trị quan hệ. Để hiểu điều kiện tính duy nhất là gì, hay nó còn được gọi là hạn chế duy nhất, hãy bắt đầu với định nghĩa của một bộ tuple và hoạt động một lần của việc chiếu một bộ tuple lên một mạch phụ. Hãy mang chúng: t = t (S) = {t (a) | a ∈ def (t) ⊆ S} - định nghĩa của một bộ giá trị, t (S) [S '] = {t (a) | a ∈ def (t) ∩ S '}, S' ⊆ S là định nghĩa của phép chiếu một ngôi; Rõ ràng là phép chiếu của bộ tuple lên ô con tương ứng với một chuỗi con của hàng trong bảng. Vậy, chính xác thì ràng buộc tính duy nhất thuộc tính khóa là gì? Việc khai báo khóa K cho lược đồ quan hệ S dẫn đến việc hình thành điều kiện bất biến sau, được gọi, như chúng ta đã nói, hạn chế tính duy nhất và được ký hiệu là: Inv <K → S> r (S): Inv <K → S> r (S) = ∀t1, T2 ∈ r(t 1[K] = t2 [K] → t 1(S) = t2(S)), K ⊆ S; Vì vậy, ràng buộc tính duy nhất này Inv <K → S> r (S) của khóa K có nghĩa là nếu hai bộ giá trị bất kỳ t1 và t2, thuộc quan hệ r (S), bằng nhau trong phép chiếu lên khóa K, khi đó điều này nhất thiết đòi hỏi sự bằng nhau của hai bộ giá trị này và trong phép chiếu lên toàn bộ lược đồ của quan hệ S. Nói cách khác, tất cả các giá trị Của các bộ giá trị thuộc các thuộc tính chính là duy nhất, duy nhất trong mối quan hệ của chúng. Và yêu cầu quan trọng thứ hai đối với khóa quan hệ là yêu cầu dự phòng. Nó có nghĩa là gì? Yêu cầu này có nghĩa là không có tập hợp con nghiêm ngặt nào của khóa được yêu cầu phải là duy nhất. Ở mức độ trực quan, rõ ràng thuộc tính khóa là thuộc tính quan hệ xác định duy nhất và chính xác từng bộ của quan hệ. Ví dụ, trong quan hệ sau được đưa ra bởi một bảng:
Thuộc tính khóa là thuộc tính "Sổ điểm #", bởi vì các học sinh khác nhau không thể có cùng một số điểm trong sổ điểm, tức là thuộc tính này phải tuân theo một ràng buộc duy nhất. Điều thú vị là trong lược đồ của bất kỳ mối quan hệ nào, có thể xuất hiện nhiều khóa khác nhau. Chúng tôi liệt kê các loại khóa chính: 1) chìa khóa đơn giản là một khóa bao gồm một và không có nhiều thuộc tính. Ví dụ, trong một phiếu kiểm tra cho một môn học cụ thể, một khóa đơn giản là số thẻ tín dụng, vì nó có thể nhận dạng duy nhất bất kỳ sinh viên nào; 2) tổ hợp phím là một khóa bao gồm hai hoặc nhiều thuộc tính. Ví dụ, một khóa tổng hợp trong danh sách các lớp học là số tòa nhà và số phòng học. Rốt cuộc, không thể xác định duy nhất từng đối tượng với một trong những thuộc tính này, và khá dễ dàng để làm điều này với tổng thể của họ, nghĩa là, với một khóa tổng hợp; 3) siêu chìa khóa là tập siêu bất kỳ của bất kỳ khóa nào. Do đó, bản thân lược đồ của mối quan hệ chắc chắn là một siêu khóa. Từ đó, chúng ta có thể kết luận rằng bất kỳ quan hệ nào về mặt lý thuyết đều có ít nhất một khóa và có thể có một số khóa trong số đó. Tuy nhiên, việc khai báo superkey thay cho khóa thông thường là bất hợp pháp về mặt logic, vì nó liên quan đến việc nới lỏng ràng buộc tính duy nhất được thực thi tự động. Rốt cuộc, siêu khóa, mặc dù nó có thuộc tính là duy nhất, nhưng không có thuộc tính không dư thừa; 4) khóa chính chỉ đơn giản là khóa được khai báo đầu tiên khi quan hệ cơ sở được định nghĩa. Điều quan trọng là một và chỉ một khóa chính được khai báo. Ngoài ra, các thuộc tính khóa chính không bao giờ có thể nhận giá trị rỗng. Khi tạo một quan hệ cơ sở trong một mục nhập mã giả, khóa chính được biểu thị khóa chính và trong ngoặc là tên của thuộc tính, là khóa này; 5) chìa khóa ứng cử viên là tất cả các khóa khác được khai báo sau khóa chính. Sự khác biệt chính giữa khóa ứng viên và khóa chính là gì? Đầu tiên, có thể có một số khóa ứng viên, trong khi khóa chính, như đã đề cập ở trên, chỉ có thể là một. Và, thứ hai, nếu các thuộc tính của khóa chính không thể nhận giá trị Null, thì điều kiện này không được áp đặt cho các thuộc tính của khóa ứng viên. Trong mã giả, khi xác định một quan hệ cơ sở, các khóa ứng viên được khai báo bằng cách sử dụng các từ chìa khóa ứng viên và trong ngoặc vuông tiếp theo, như trong trường hợp khai báo khóa chính, tên của thuộc tính được chỉ ra, đó là khóa ứng viên đã cho; 6) chìa khóa bên ngoài là một khóa được khai báo trong một quan hệ cơ sở cũng tham chiếu đến một khóa chính hoặc khóa ứng viên của cùng một hoặc một số quan hệ cơ sở khác. Trong trường hợp này, mối quan hệ mà khóa ngoại tham chiếu đến được gọi là một tham chiếu (hoặc cha mẹ) Thái độ. Một quan hệ có chứa khóa ngoại được gọi là đứa trẻ. Trong mã giả, khóa ngoại được ký hiệu là khóa ngoại, trong dấu ngoặc ngay sau những từ này, tên của thuộc tính của mối quan hệ này, là khóa ngoại, được chỉ ra và sau đó từ khóa được viết tài liệu tham khảo ("tham chiếu đến") và chỉ định tên của quan hệ cơ sở và tên của thuộc tính mà khóa ngoại cụ thể này tham chiếu đến. Ngoài ra, khi tạo một quan hệ cơ sở, đối với mỗi khóa ngoại, một điều kiện được viết, được gọi là ràng buộc toàn vẹn tham chiếu, nhưng chúng ta sẽ nói về điều này một cách chi tiết sau. Bài giảng số 8 Chủ đề của bài giảng này sẽ là một cuộc thảo luận khá chi tiết về toán tử tạo quan hệ cơ sở. Chúng tôi sẽ phân tích chính toán tử trong một bản ghi mã giả, phân tích tất cả các thành phần của nó và công việc của chúng, đồng thời phân tích các phương pháp sửa đổi, tức là thay đổi các quan hệ cơ bản. 1. Biểu tượng kim loại Khi mô tả các cấu trúc cú pháp được sử dụng để viết toán tử tạo quan hệ cơ sở trong mã giả, nhiều phương pháp khác nhau được sử dụng. biểu tượng kim loại. Đây là tất cả các loại dấu ngoặc mở và đóng, các kết hợp khác nhau của dấu chấm và dấu phẩy, trong một từ, các ký hiệu mà mỗi ký hiệu mang ý nghĩa riêng của chúng và giúp lập trình viên viết mã dễ dàng hơn. Hãy để chúng tôi giới thiệu và giải thích ý nghĩa của các ký hiệu kim loại chính thường được sử dụng nhất trong thiết kế các quan hệ cơ bản. Vì thế: 1) ký tự metalinguistic "{}". Các cấu trúc cú pháp trong dấu ngoặc nhọn là bắt buộc đơn vị cú pháp. Khi xác định một quan hệ cơ sở, các phần tử bắt buộc, ví dụ, là các thuộc tính cơ sở; mà không khai báo các thuộc tính cơ sở thì không thể thiết kế được mối quan hệ nào. Do đó, khi viết toán tử tạo quan hệ cơ sở trong mã giả, các thuộc tính cơ sở được liệt kê trong dấu ngoặc nhọn; 2) biểu tượng ngôn ngữ kim loại "[]". Trong trường hợp này, điều ngược lại là đúng: cấu trúc cú pháp trong dấu ngoặc vuông thể hiện không bắt buộc các yếu tố cú pháp. Đến lượt mình, các đơn vị cú pháp tùy chọn trong toán tử tạo quan hệ cơ sở là các thuộc tính ảo của khóa chính, khóa ứng viên và khóa ngoại. Ở đây, tất nhiên, cũng có những điều tinh tế, nhưng chúng ta sẽ nói về chúng sau, khi chúng ta tiến hành trực tiếp đến thiết kế của toán tử để tạo quan hệ cơ sở; 3) ký hiệu metalinguistic "|". Biểu tượng này có nghĩa đen là "hoặc", giống như biểu tượng tương tự trong toán học. Việc sử dụng biểu tượng ngôn ngữ học kim loại này có nghĩa là người ta phải chọn giữa hai hoặc nhiều công trình được ngăn cách tương ứng bằng biểu tượng này; 4) ký hiệu kim loại học "...". Dấu chấm lửng được đặt ngay sau bất kỳ đơn vị cú pháp nào có nghĩa là khả năng sự lặp lại những yếu tố cú pháp này đứng trước biểu tượng ngôn ngữ kim loại; 5) ký hiệu metalinguistic ", ..". Biểu tượng này có nghĩa gần giống với biểu tượng trước đó. Chỉ khi sử dụng biểu tượng ngôn ngữ kim loại ", ..", sự nhắc lại cấu trúc cú pháp xảy ra phân tách bằng dấu phẩymà thường thuận tiện hơn nhiều. Với ý nghĩ này, chúng ta có thể nói về sự tương đương của hai cấu trúc cú pháp sau: đơn vị [, đơn vị]... и đơn vị,.. ; 2. Ví dụ về cách tạo mối quan hệ cơ bản trong mục nhập mã giả Bây giờ chúng ta đã làm rõ ý nghĩa của các ký hiệu kim loại học chính được sử dụng khi viết toán tử tạo quan hệ cơ sở trong mã giả, chúng ta có thể tiến hành xem xét thực tế của chính toán tử này. Như có thể hiểu từ các tham chiếu ở trên, toán tử để tạo quan hệ cơ sở trong mục nhập mã giả bao gồm khai báo các thuộc tính cơ sở và ảo, khóa chính, ứng viên và khóa ngoại. Ngoài ra, như sẽ được trình bày và giải thích ở trên, toán tử này cũng bao gồm các ràng buộc giá trị thuộc tính và ràng buộc tuple, cũng như cái gọi là ràng buộc toàn vẹn tham chiếu. Hai ràng buộc đầu tiên, cụ thể là ràng buộc giá trị thuộc tính và ràng buộc tuple, được khai báo sau từ dành riêng đặc biệt kiểm tra. Ràng buộc toàn vẹn tham chiếu có thể có hai loại: cập nhật, có nghĩa là "khi cập nhật" và trên xóa, có nghĩa là "khi xóa". Nó có nghĩa là gì? Điều này có nghĩa là khi cập nhật hoặc xóa các thuộc tính của các mối quan hệ được tham chiếu bởi khóa ngoại, tính toàn vẹn của trạng thái phải được duy trì. (Chúng ta sẽ nói thêm về điều này sau.) Bản thân toán tử tạo quan hệ cơ sở được chúng tôi sử dụng đã được nghiên cứu - toán tử Tạo, chỉ để tạo mối quan hệ cơ bản, từ khóa được thêm vào bàn ("Thái độ"). Và, tất nhiên, vì bản thân quan hệ lớn hơn và bao gồm tất cả các cấu trúc đã thảo luận trước đó, cũng như các cấu trúc bổ sung mới, nên toán tử tạo sẽ khá ấn tượng. Vì vậy, hãy viết bằng mã giả dạng chung của toán tử được sử dụng để tạo các quan hệ cơ bản: Tạo bảng tên quan hệ cơ sở {tên thuộc tính cơ sở loại giá trị thuộc tính cơ sở kiểm tra (ràng buộc giá trị thuộc tính) {Không có | có giá trị} mặc định (giá trị mặc định) }, .. [tên thuộc tính ảo as (công thức tính) ], .. [,kiểm tra (ràng buộc tuple)] [,khóa chính (tên thuộc tính, ..)] [,chìa khóa ứng viên (tên thuộc tính,..)]... [,khóa ngoại (tên thuộc tính, ..) tài liệu tham khảo tên quan hệ tham chiếu (tên thuộc tính, ..) trên bản cập nhật {Restrict | Xếp tầng | Đặt Null} khi xóa {Hạn chế | Xếp tầng | Đặt Null} ] ... Vì vậy, chúng tôi thấy rằng một số thuộc tính cơ bản và ảo, ứng cử viên và khóa ngoại có thể được khai báo, vì sau các cấu trúc cú pháp tương ứng có một ký hiệu metalinguistic ", .." Sau khi khai báo khóa chính, ký hiệu này không xuất hiện, bởi vì các quan hệ cơ sở, như đã đề cập trước đó, chỉ cho phép một khóa chính. Tiếp theo, chúng ta hãy xem xét kỹ hơn cơ chế khai báo. thuộc tính cơ bản. Khi mô tả bất kỳ thuộc tính nào trong toán tử tạo quan hệ cơ sở, trong trường hợp chung, tên, kiểu, các hạn chế đối với giá trị của nó, cờ hiệu lực Null-giá trị và các giá trị mặc định được chỉ định. Dễ dàng nhận thấy rằng kiểu của một thuộc tính và các ràng buộc giá trị của nó xác định miền của nó, nghĩa là tập các giá trị hợp lệ cho thuộc tính cụ thể đó theo nghĩa đen. Giới hạn giá trị thuộc tính được viết như một điều kiện phụ thuộc vào tên thuộc tính. Dưới đây là một ví dụ nhỏ để làm cho tài liệu này dễ hiểu hơn: Tạo bảng tên quan hệ cơ sở Khóa học số nguyên kiểm tra (1 <= Khóa học và Khóa học <= 5; Ở đây, điều kiện "1 <= Heading và Heading <= 5" cùng với định nghĩa về kiểu dữ liệu số nguyên thực sự hoàn toàn điều kiện hóa tập hợp các giá trị được phép của thuộc tính, nghĩa là miền của nó. Cờ cho phép các giá trị Null (Null | not Null) cấm (không Null) hoặc ngược lại, cho phép (Null) sự xuất hiện của các giá trị Null giữa các giá trị thuộc tính. Lấy ví dụ vừa thảo luận, cơ chế áp dụng cờ Null-valid như sau: Tạo bảng tên quan hệ cơ sở Khóa học số nguyên kiểm tra (1 <= Khóa học và Khóa học <= 5); Có giá trị; Vì vậy, số khóa học của sinh viên không bao giờ được rỗng, không thể không xác định đối với trình biên dịch cơ sở dữ liệu, và không thể không tồn tại. Giá trị mặc định (mặc định (giá trị mặc định)) được sử dụng khi chèn một bộ giá trị vào một mối quan hệ nếu các giá trị thuộc tính không được đặt rõ ràng trong câu lệnh chèn. Điều thú vị cần lưu ý là các giá trị mặc định cũng có thể là giá trị Null, miễn là các giá trị Null cho thuộc tính cụ thể đó được khai báo hợp lệ. Bây giờ hãy xem xét định nghĩa thuộc tính ảo trong toán tử tạo quan hệ cơ sở. Như chúng ta đã nói trước đó, việc thiết lập một thuộc tính ảo bao gồm việc thiết lập các công thức cho phép tính của nó thông qua các thuộc tính cơ sở khác. Hãy xem xét một ví dụ về việc khai báo thuộc tính ảo "Cost Rub." dưới dạng công thức tùy thuộc vào các thuộc tính cơ bản "Trọng lượng Kg" và "Chênh lệch giá trên mỗi Kg". Tạo bảng tên quan hệ cơ sở Trọng lượng, kg loại giá trị thuộc tính cơ sở Trọng lượng Kg kiểm tra (giới hạn của giá trị thuộc tính Trọng lượng Kg) có giá trị mặc định (giá trị mặc định) Giá, chà. mỗi kg loại giá trị của thuộc tính cơ sở Giá Chà. mỗi kg kiểm tra (giới hạn giá trị của thuộc tính Chà giá trên mỗi Kg) có giá trị mặc định (giá trị mặc định) hữu ích. Cảm ơn ! Chi phí, chà. as (Trọng lượng Kg * Chà giá trên mỗi Kg) Trước đó một chút, chúng ta đã xem xét các ràng buộc thuộc tính, được viết dưới dạng các điều kiện phụ thuộc vào tên thuộc tính. Bây giờ hãy xem xét loại ràng buộc thứ hai được khai báo khi tạo quan hệ cơ sở, cụ thể là ràng buộc tuple. Ràng buộc tuple là gì, nó khác với ràng buộc thuộc tính như thế nào? Ràng buộc tuple cũng được viết như một điều kiện phụ thuộc vào tên thuộc tính cơ sở, nhưng chỉ trong trường hợp ràng buộc tuple, điều kiện có thể phụ thuộc vào nhiều tên thuộc tính cùng một lúc. Hãy xem xét một ví dụ minh họa cơ chế hoạt động với các ràng buộc tuple: Tạo bảng tên quan hệ cơ sở Trọng lượng tối thiểu Kg loại giá trị của thuộc tính cơ sở tối thiểu Trọng lượng Kg kiểm tra (giới hạn của giá trị thuộc tính tối thiểu Trọng lượng Kg) có giá trị mặc định (giá trị mặc định) trọng lượng tối đa Kg loại giá trị của thuộc tính cơ sở tối đa Trọng lượng Kg kiểm tra (giới hạn của giá trị thuộc tính tối đa Trọng lượng Kg) có giá trị mặc định (giá trị mặc định) kiểm tra (0 <min Trọng lượng Kg và tối thiểu Trọng lượng Kg <Trọng lượng tối đa Kg); Do đó, việc áp dụng một ràng buộc đối với một bộ giá trị để thay thế các giá trị của bộ giá trị cho các tên thuộc tính. Hãy chuyển sang xem xét toán tử tạo quan hệ cơ sở. Sau khi được khai báo, các thuộc tính cơ sở và ảo có thể được khai báo hoặc không. phím: chính, ứng cử viên và bên ngoài. Như chúng ta đã nói trước đó, thiếu đồ của một quan hệ cơ sở mà trong một quan hệ cơ sở khác (hoặc tương tự) tương ứng với một khóa chính hoặc khóa ứng viên trong ngữ cảnh của quan hệ đầu tiên được gọi là khóa ngoại. Các khóa ngoại đại diện cơ chế liên kết bộ giá trị của một số quan hệ trên bộ giá trị của các quan hệ khác, tức là có các khai báo khóa ngoại liên quan đến việc áp đặt cái gọi là ràng buộc toàn vẹn tham chiếu. (Ràng buộc này sẽ là trọng tâm của bài giảng tiếp theo, vì tính toàn vẹn trạng thái (tức là tính toàn vẹn được thực thi bởi các ràng buộc toàn vẹn) là rất quan trọng đối với sự thành công của quan hệ cơ sở và toàn bộ cơ sở dữ liệu.) Đến lượt mình, việc khai báo các khóa chính và khóa ứng viên sẽ áp đặt các ràng buộc về tính duy nhất thích hợp trên lược đồ quan hệ cơ sở mà chúng ta đã thảo luận trước đó. Và, cuối cùng, cần nói về khả năng xóa quan hệ cơ sở. Thông thường trong thực hành thiết kế cơ sở dữ liệu, cần phải loại bỏ một quan hệ cũ không cần thiết để không làm lộn xộn mã chương trình. Điều này có thể được thực hiện bằng cách sử dụng toán tử đã quen thuộc Rơi. Ở dạng tổng quát đầy đủ của nó, toán tử xóa quan hệ cơ sở trông giống như sau: thả bàn tên của quan hệ cơ sở; 3. Ràng buộc toàn vẹn theo trạng thái Ràng buộc về tính toàn vẹn đối tượng dữ liệu quan hệ kể từ là cái gọi là bất biến dữ liệu. Đồng thời, tính toàn vẹn nên được phân biệt một cách chắc chắn với bảo mật, do đó, nghĩa là bảo vệ dữ liệu khỏi sự truy cập trái phép vào chúng nhằm tiết lộ, sửa đổi hoặc phá hủy dữ liệu. Nói chung, các ràng buộc toàn vẹn trên các đối tượng dữ liệu quan hệ được phân loại theo cấp độ phân cấp cùng các đối tượng dữ liệu quan hệ này (thứ bậc của các đối tượng dữ liệu quan hệ là một chuỗi các khái niệm lồng nhau: "thuộc tính - tuple - quan hệ - cơ sở dữ liệu"). Điều đó có nghĩa là gì? Điều này có nghĩa là các ràng buộc toàn vẹn phụ thuộc vào: 1) ở cấp thuộc tính - từ các giá trị thuộc tính; 2) ở cấp bộ - từ các giá trị của bộ, tức là từ các giá trị của một số thuộc tính; 3) ở cấp độ quan hệ - từ một quan hệ, tức là từ một số bộ giá trị; 4) ở cấp độ cơ sở dữ liệu - từ một số mối quan hệ. Vì vậy, bây giờ chúng ta chỉ cần xem xét chi tiết hơn về các ràng buộc toàn vẹn đối với trạng thái của mỗi khái niệm trên. Nhưng trước tiên, hãy đưa ra các khái niệm về hỗ trợ thủ tục và khai báo cho các ràng buộc toàn vẹn trạng thái. Vì vậy, hỗ trợ cho các ràng buộc toàn vẹn có thể có hai loại: 1) thủ tục, tức là, được tạo ra bằng cách viết mã chương trình; 2) khai báo, tức là, được tạo bằng cách khai báo các hạn chế nhất định cho mỗi khái niệm lồng nhau ở trên. Hỗ trợ khai báo cho các ràng buộc toàn vẹn được thực hiện trong ngữ cảnh của câu lệnh Tạo để tạo quan hệ cơ sở. Hãy nói về điều này chi tiết hơn. Hãy bắt đầu xem xét tập hợp các hạn chế từ cuối bậc thang phân cấp của các đối tượng dữ liệu quan hệ, tức là từ khái niệm thuộc tính. Ràng buộc mức thuộc tính bao gồm: 1) hạn chế về loại giá trị thuộc tính. Ví dụ, một điều kiện số nguyên cho các giá trị, tức là một điều kiện số nguyên cho thuộc tính "Course" từ một trong các quan hệ cơ sở đã thảo luận trước đó; 2) một ràng buộc giá trị thuộc tính, được viết như một điều kiện phụ thuộc vào tên thuộc tính. Ví dụ, phân tích quan hệ cơ bản tương tự như trong đoạn trước, chúng ta thấy rằng trong quan hệ đó cũng có ràng buộc về giá trị thuộc tính bằng cách sử dụng tùy chọn kiểm tra, I E.: kiểm tra (1 <= Khóa học và Khóa học <= 5); 3) Ràng buộc cấp thuộc tính bao gồm các ràng buộc giá trị Null được xác định bởi cờ hiệu lực nổi tiếng (Null) hoặc ngược lại, không thể chấp nhận (không phải Null) giá trị Null. Như chúng ta đã đề cập trước đó, hai ràng buộc đầu tiên xác định ràng buộc miền của thuộc tính, tức là giá trị của tập định nghĩa của nó. Hơn nữa, theo bậc thang phân cấp của các đối tượng dữ liệu quan hệ, chúng ta cần nói về các bộ giá trị. Vì thế, hạn chế mức tuple giảm thành ràng buộc tuple và được viết dưới dạng điều kiện phụ thuộc vào tên của một số thuộc tính cơ bản của lược đồ quan hệ, tức là, ràng buộc toàn vẹn trạng thái này nhỏ hơn và đơn giản hơn nhiều so với ràng buộc tương tự, chỉ tương ứng với thuộc tính. Và một lần nữa, sẽ rất hữu ích khi nhớ lại ví dụ về quan hệ cơ bản mà chúng ta đã trải qua trước đó, có ràng buộc tuple mà chúng ta cần bây giờ, cụ thể là: kiểm tra (0 <min Trọng lượng Kg và tối thiểu Trọng lượng Kg <Trọng lượng tối đa Kg); Và, cuối cùng, khái niệm quan trọng cuối cùng trong bối cảnh ràng buộc toàn vẹn đối với trạng thái là khái niệm về mức độ quan hệ. Như chúng tôi đã nói trước đây, ràng buộc mức độ quan hệ bao gồm việc giới hạn các giá trị của chính (khóa chính) và ứng cử viên (chìa khóa ứng viên) các phím. Thật kỳ lạ rằng các hạn chế áp đặt cho cơ sở dữ liệu không còn là các ràng buộc toàn vẹn trạng thái nữa mà là các ràng buộc toàn vẹn tham chiếu. 4. Ràng buộc về tính toàn vẹn tham chiếu Vì vậy, ràng buộc mức cơ sở dữ liệu bao gồm ràng buộc toàn vẹn tham chiếu khóa ngoại (khóa ngoại). Chúng tôi đã đề cập ngắn gọn đến vấn đề này khi chúng tôi nói về các ràng buộc toàn vẹn tham chiếu khi tạo mối quan hệ cơ sở và khóa ngoại. Bây giờ là lúc để nói về khái niệm này chi tiết hơn. Như chúng ta đã nói trước đây, khóa ngoại của quan hệ cơ sở được khai báo đề cập đến khóa chính hoặc khóa ứng viên của một số quan hệ cơ sở khác (thường gặp nhất). Nhớ lại rằng trong trường hợp này, quan hệ được tham chiếu bởi khóa ngoại được gọi là tài liệu tham khảo hoặc cha mẹ, bởi vì nó sắp xếp "sinh ra" một thuộc tính hoặc nhiều thuộc tính trong quan hệ cơ sở tham chiếu. Và đến lượt nó, một quan hệ có chứa khóa ngoại được gọi là đứa trẻ, cũng vì những lý do hiển nhiên. Cái gì là ràng buộc toàn vẹn tham chiếu? Và nó bao gồm thực tế là mỗi giá trị của khóa ngoại của mối quan hệ con nhất thiết phải tương ứng với giá trị của bất kỳ khóa nào của mối quan hệ mẹ, trừ khi giá trị của khóa ngoại chứa giá trị Null trong bất kỳ thuộc tính nào. Các bộ số của một quan hệ con vi phạm điều kiện này được gọi là treo cổ. Thật vậy, nếu khóa ngoại của quan hệ con đề cập đến một thuộc tính không thực sự tồn tại trong quan hệ mẹ, thì nó không tham chiếu đến bất cứ thứ gì. Chính xác là những tình huống này phải được tránh bằng mọi cách có thể, và điều này có nghĩa là duy trì tính toàn vẹn của tham chiếu. Tuy nhiên, biết rằng không có cơ sở dữ liệu nào cho phép tạo một bộ giá trị treo lơ lửng, các nhà phát triển đảm bảo rằng không có bộ giá trị treo lơ lửng ban đầu nào trong cơ sở dữ liệu và tất cả các khóa có sẵn đều tham chiếu đến một thuộc tính rất thực của mối quan hệ mẹ. Tuy nhiên, có những tình huống khi các bộ giá trị treo lủng lẳng đã được hình thành trong quá trình vận hành cơ sở dữ liệu. Những tình huống này là gì? Được biết rằng khi các bộ giá trị bị xóa khỏi quan hệ mẹ hoặc khi giá trị khóa của một bộ giá trị của quan hệ mẹ được cập nhật, tính toàn vẹn tham chiếu có thể bị vi phạm, tức là các bộ giá trị treo có thể xảy ra. Để loại trừ khả năng xuất hiện của chúng khi khai báo giá trị khóa ngoại, một trong những điều sau được chỉ định: ba có sẵn quy tắc duy trì tính toàn vẹn tham chiếu, được áp dụng tương ứng khi cập nhật giá trị khóa trong quan hệ mẹ (tức là, như chúng tôi đã đề cập trước đó, cập nhật) hoặc khi xóa một bộ khỏi quan hệ mẹ (trên xóa). Cần lưu ý rằng việc thêm một bộ giá trị mới vào mối quan hệ mẹ không thể phá vỡ tính toàn vẹn của tham chiếu, vì những lý do rõ ràng. Rốt cuộc, nếu tuple này chỉ được thêm vào quan hệ cơ sở, không có thuộc tính nào có thể tham chiếu đến nó trước đó vì sự vắng mặt của nó! Vậy ba quy tắc này được sử dụng để duy trì tính toàn vẹn của tham chiếu trong cơ sở dữ liệu là gì? Hãy liệt kê chúng. 1. hạn chếHoặc quy tắc hạn chế. Nếu, khi thiết lập quan hệ cơ sở của chúng tôi, khi khai báo khóa ngoại trong một ràng buộc toàn vẹn tham chiếu, chúng tôi đã áp dụng quy tắc duy trì nó này, thì việc cập nhật khóa trong quan hệ mẹ hoặc xóa một bộ từ quan hệ mẹ chỉ đơn giản là không thể thực hiện được nếu bộ này là được tham chiếu bởi ít nhất một bộ quan hệ con, tức là hoạt động hạn chế nghiêm cấm thực hiện bất kỳ hành động nào có thể dẫn đến sự xuất hiện của các bộ giá treo. Chúng tôi minh họa việc áp dụng quy tắc này bằng ví dụ sau. Cho hai quan hệ: Thái độ của cha mẹ
quan hệ con cái
Chúng ta thấy rằng các bộ quan hệ con (2,...) và (2,...) đề cập đến bộ dữ liệu quan hệ cha (..., 2), và bộ dữ liệu quan hệ con (3,...) đề cập đến ( ..., 3) thái độ của cha mẹ. Bộ dữ liệu (100,...) của quan hệ con bị treo lủng lẳng và không hợp lệ. Ở đây, chỉ các bộ quan hệ cha (..., 1) và (..., 4) mới cho phép cập nhật các giá trị khóa và các bộ dữ liệu bị xóa vì chúng không được tham chiếu bởi bất kỳ khóa ngoại nào của quan hệ con. Hãy soạn toán tử để tạo một quan hệ cơ bản, bao gồm khai báo tất cả các khóa ở trên: Tạo bảng Thái độ của cha mẹ Khóa chính Số nguyên có giá trị khóa chính (Khóa chính) Tạo bảng quan hệ con cái khóa_cầu_cầu Số nguyên Null khóa ngoại (khóa ngoại) tài liệu tham khảo Mối quan hệ cha mẹ (Khóa_chính_chính) trên cập nhật Hạn chế xóa hạn chế 2. CascadeHoặc quy tắc sửa đổi tầng. Nếu, khi khai báo khóa ngoại trong quan hệ cơ sở của chúng tôi, chúng tôi đã sử dụng quy tắc duy trì tính toàn vẹn tham chiếu Cascade, sau đó cập nhật một khóa trong quan hệ mẹ hoặc xóa một bộ từ quan hệ mẹ khiến các khóa và bộ giá trị tương ứng của quan hệ con được tự động cập nhật hoặc xóa. Hãy xem một ví dụ để hiểu rõ hơn về cách hoạt động của quy tắc sửa đổi tầng. Hãy đưa ra các quan hệ cơ bản đã quen thuộc với chúng ta từ ví dụ trước: Thái độ của cha mẹ
и quan hệ con cái
Giả sử chúng ta cập nhật một số bộ dữ liệu trong bảng xác định mối quan hệ “Mối quan hệ cha mẹ”, cụ thể là chúng ta thay thế bộ dữ liệu (..., 2) bằng bộ dữ liệu (..., 20), tức là chúng ta có một mối quan hệ mới: Thái độ của cha mẹ
Và đồng thời trong câu lệnh tạo quan hệ cơ sở của chúng tôi "Quan hệ con" khi khai báo khóa ngoại, chúng tôi đã sử dụng quy tắc duy trì tính toàn vẹn tham chiếu Cascade, tức là toán tử để tạo mối quan hệ cơ sở của chúng tôi trông giống như sau: Tạo bảng Thái độ của cha mẹ Khóa chính Số nguyên có giá trị khóa chính (Khóa chính) Tạo bảng quan hệ con cái khóa_cầu_cầu Số nguyên Null khóa ngoại (khóa ngoại) tài liệu tham khảo Mối quan hệ cha mẹ (Khóa_chính_chính) cập nhật Cascade xóa Cascade Sau đó, điều gì sẽ xảy ra với quan hệ con khi quan hệ mẹ được cập nhật theo cách được mô tả ở trên? Nó sẽ có dạng sau: quan hệ con cái
Vì vậy, thực tế, quy tắc Cascade cung cấp bản cập nhật theo tầng của tất cả các bộ giá trị trong quan hệ con để đáp ứng với các cập nhật đối với quan hệ mẹ. 3. Đặt NullHoặc quy tắc gán rỗng. Nếu, trong câu lệnh tạo quan hệ cơ sở của chúng tôi, khi khai báo khóa ngoại, chúng tôi áp dụng quy tắc duy trì tính toàn vẹn tham chiếu Đặt Null, khi đó việc cập nhật khóa của quan hệ cha hoặc xóa một bộ khỏi quan hệ cha sẽ đòi hỏi phải tự động gán giá trị Null cho các thuộc tính khóa ngoài của quan hệ con cho phép giá trị Null. Vì vậy, quy tắc có thể áp dụng được nếu thuộc tính đó tồn tại. Hãy xem một ví dụ mà chúng tôi đã sử dụng trước đây. Giả sử chúng ta có hai quan hệ cơ bản: "Nuôi dạy con cái"
quan hệ con cái
Như bạn có thể thấy, các thuộc tính quan hệ con cho phép các giá trị Null, do đó quy tắc Đặt Null áp dụng trong trường hợp cụ thể này. Bây giờ chúng ta giả sử rằng bộ dữ liệu (..., 1) đã bị xóa khỏi quan hệ cha và bộ dữ liệu (..., 2) đã được cập nhật, như trong ví dụ trước. Do đó, quan hệ cha mẹ có dạng sau: Thái độ của cha mẹ
Sau đó, có tính đến thực tế là khi khai báo các khóa ngoại của quan hệ con, chúng tôi đã áp dụng quy tắc duy trì tính toàn vẹn tham chiếu Đặt Null, quan hệ con sẽ trông như thế này: quan hệ con cái
Bộ dữ liệu (..., 1) không được tham chiếu bởi bất kỳ khóa quan hệ con nào, do đó việc xóa nó không gây hậu quả gì. Bản thân toán tử tạo quan hệ cơ sở sử dụng quy tắc Đặt Null khi khai báo khóa ngoại, mối quan hệ trông như thế này: Tạo bảng Thái độ của cha mẹ Khóa chính Số nguyên có giá trị khóa chính (Khóa chính) Tạo bảng quan hệ con cái khóa_cầu_cầu Số nguyên Null khóa ngoại (khóa ngoại) tài liệu tham khảo Mối quan hệ cha mẹ (Khóa_chính_chính) trên bản cập nhật Đặt Null khi xóa Set Null Vì vậy, chúng tôi thấy rằng sự hiện diện của ba quy tắc khác nhau để duy trì tính toàn vẹn của tham chiếu đảm bảo rằng trong các cụm từ cập nhật и trên xóa các chức năng có thể khác nhau. Cần phải nhớ và hiểu rằng việc chèn các bộ giá trị vào một quan hệ con hoặc cập nhật các giá trị khóa của các quan hệ con sẽ không được thực hiện nếu điều này dẫn đến sự vi phạm tính toàn vẹn của tham chiếu, tức là sự xuất hiện của cái gọi là các bộ giá trị treo lơ lửng. Loại bỏ các bộ giá trị khỏi quan hệ con trong mọi trường hợp có thể dẫn đến vi phạm tính toàn vẹn tham chiếu. Điều thú vị là một quan hệ con có thể đồng thời hoạt động như một quan hệ mẹ với các quy tắc riêng của nó để duy trì tính toàn vẹn tham chiếu, nếu các khóa ngoại của các quan hệ cơ sở khác tham chiếu đến một số thuộc tính của nó như là khóa chính. Nếu các lập trình viên muốn đảm bảo rằng tính toàn vẹn của tham chiếu được thực thi bởi một số quy tắc khác với các quy tắc tiêu chuẩn ở trên, thì hỗ trợ thủ tục cho các quy tắc phi tiêu chuẩn đó để duy trì tính toàn vẹn của tham chiếu được cung cấp với sự trợ giúp của cái gọi là trình kích hoạt. Thật không may, việc xem xét chi tiết về khái niệm này không được đưa vào quá trình giảng dạy của chúng tôi. 5. Khái niệm về chỉ số Việc tạo các khóa trong các mối quan hệ cơ sở được tự động liên kết với việc tạo các chỉ mục. Hãy để chúng tôi xác định khái niệm về một chỉ mục. Index - đây là cấu trúc dữ liệu hệ thống chứa danh sách các giá trị có thứ tự nhất thiết của một khóa với các liên kết đến các bộ giá trị của mối quan hệ mà các giá trị này xảy ra. Có hai loại chỉ mục trong hệ quản trị cơ sở dữ liệu: 1) đơn giản. Một chỉ mục đơn giản được lấy cho một lược đồ con của quan hệ cơ sở từ một thuộc tính duy nhất; 2) hỗn hợp. Theo đó, một chỉ mục tổng hợp là một chỉ mục cho một địa chỉ con bao gồm một số thuộc tính. Nhưng, ngoài việc phân chia thành các chỉ mục đơn giản và tổng hợp, trong các hệ quản trị cơ sở dữ liệu còn có sự phân chia các chỉ mục thành duy nhất và không duy nhất. Vì thế: 1) độc đáo indexes là các chỉ mục đề cập đến nhiều nhất một thuộc tính. Các chỉ mục duy nhất thường tương ứng với khóa chính của quan hệ; 2) không duy nhất indexes là các chỉ mục có thể khớp với nhiều thuộc tính cùng một lúc. Đến lượt mình, các khóa không phải là duy nhất thường tương ứng với các khóa ngoại của mối quan hệ. Hãy xem xét một ví dụ minh họa việc phân chia chỉ mục thành duy nhất và không duy nhất, tức là xem xét các mối quan hệ sau được xác định bởi các bảng:
Ở đây tương ứng, Khóa chính là khóa chính của mối quan hệ, Khóa ngoại là khóa ngoại. Rõ ràng là trong các quan hệ này, chỉ mục của thuộc tính Khóa chính là duy nhất, vì nó tương ứng với khóa chính, tức là một thuộc tính, và chỉ mục của thuộc tính Khóa ngoại là không duy nhất, vì nó tương ứng với ngoại chìa khóa. Và giá trị "20" của nó tương ứng với cả hàng đầu tiên và hàng thứ ba của bảng quan hệ. Nhưng đôi khi chỉ mục có thể được tạo mà không liên quan đến khóa. Điều này được thực hiện trong các hệ quản trị cơ sở dữ liệu để hỗ trợ việc thực hiện các thao tác sắp xếp và tìm kiếm. Ví dụ, một tìm kiếm lưỡng phân cho một giá trị chỉ mục trong các bộ giá trị sẽ được thực hiện trong hệ thống quản lý cơ sở dữ liệu trong hai mươi lần lặp lại. Thông tin này đến từ đâu? Chúng thu được bằng các phép tính đơn giản, tức là như sau: 106 = (103)2 = 220; Chỉ mục được tạo trong hệ quản trị cơ sở dữ liệu bằng cách sử dụng câu lệnh Create mà chúng ta đã biết, nhưng chỉ với việc bổ sung từ khóa index. Một toán tử như vậy trông như thế này: Tạo chỉ mục tên chỉ mục On tên quan hệ cơ sở (tên thuộc tính, ..); Ở đây chúng ta thấy ký hiệu metalinguistic quen thuộc ", .." biểu thị khả năng lặp lại một đối số được phân tách bằng dấu phẩy, tức là có thể tạo một chỉ mục tương ứng với một số thuộc tính trong toán tử này. Nếu bạn muốn khai báo một chỉ mục duy nhất, bạn thêm từ khóa duy nhất trước từ chỉ mục và sau đó toàn bộ câu lệnh tạo trong quan hệ chỉ mục cơ sở sẽ trở thành: Tạo chỉ mục duy nhất tên chỉ mục On tên quan hệ cơ sở (tên thuộc tính); Sau đó, ở dạng tổng quát nhất, nếu chúng ta nhớ lại quy tắc chỉ định các phần tử tùy chọn (ký hiệu metalinguistic []), toán tử tạo chỉ mục trong quan hệ cơ bản sẽ giống như sau: Tạo chỉ mục [duy nhất] tên chỉ mục On tên quan hệ cơ sở (tên thuộc tính, ..); Nếu bạn muốn xóa một chỉ mục đã tồn tại khỏi quan hệ cơ sở, hãy sử dụng toán tử Drop, cũng đã được chúng tôi biết đến: giảm chỉ số {tên quan hệ cơ sở. Tên chỉ mục}, ..; Tại sao tên chỉ mục đủ điều kiện "tên quan hệ cơ sở. Tên chỉ mục" được sử dụng ở đây? Toán tử thả chỉ mục luôn sử dụng tên đủ điều kiện của nó vì tên chỉ mục phải là duy nhất trong cùng một mối quan hệ, nhưng không được nhiều hơn. 6. Sửa đổi các quan hệ cơ bản Để làm việc thành công và hiệu quả với các mối quan hệ cơ sở khác nhau, các nhà phát triển thường cần phải sửa đổi mối quan hệ cơ sở này theo một cách nào đó. Các tùy chọn sửa đổi yêu cầu chính thường gặp nhất trong thực hành thiết kế cơ sở dữ liệu là gì? Hãy liệt kê chúng: 1) chèn các bộ giá trị. Thông thường, bạn cần phải chèn các bộ giá trị mới vào một quan hệ cơ sở đã được hình thành; 2) cập nhật các giá trị thuộc tính. Và nhu cầu sửa đổi này trong thực tế lập trình thậm chí còn phổ biến hơn so với trước đó, bởi vì khi có thông tin mới về các đối số của cơ sở dữ liệu của bạn, chắc chắn bạn sẽ phải cập nhật một số thông tin cũ; 3) loại bỏ các bộ giá trị. Và với xác suất xấp xỉ bằng nhau, cần phải loại bỏ khỏi quan hệ cơ sở những bộ giá trị mà sự hiện diện trong cơ sở dữ liệu của bạn không còn được yêu cầu do nhận được thông tin mới. Như vậy, chúng tôi đã nêu ra những điểm chính của việc sửa đổi các quan hệ cơ bản. Làm thế nào để đạt được từng mục tiêu này? Trong các hệ quản trị cơ sở dữ liệu, hầu hết thường có các toán tử sửa đổi mối quan hệ cơ bản được tích hợp sẵn. Hãy mô tả chúng trong một mục nhập mã giả: 1) chèn toán tử vào quan hệ cơ sở của các bộ giá trị mới. Đây là nhà điều hành Chèn. Nó trông như thế này: Chèn vào tên quan hệ cơ sở (tên thuộc tính, ..) Các giá trị (giá trị thuộc tính,..); Ký hiệu metalinguistic ", .." sau tên thuộc tính và giá trị thuộc tính cho chúng ta biết rằng toán tử này cho phép nhiều thuộc tính được thêm vào quan hệ cơ sở cùng một lúc. Trong trường hợp này, bạn phải liệt kê tên thuộc tính và giá trị thuộc tính, được phân tách bằng dấu phẩy, theo một thứ tự nhất quán. Từ khóa trong kết hợp với tên chung của nhà điều hành Chèn có nghĩa là "chèn vào" và cho biết mối quan hệ nào mà các thuộc tính trong ngoặc sẽ được chèn vào. Từ khóa Các giá trị trong câu lệnh này, và có nghĩa là "giá trị", "giá trị", được gán cho các thuộc tính mới được khai báo này; 2) bây giờ hãy xem xét cập nhật nhà điều hành các giá trị thuộc tính trong quan hệ cơ sở. Toán tử này được gọi là Cập nhật, được dịch từ tiếng Anh và có nghĩa đen là "cập nhật". Hãy cung cấp dạng tổng quát đầy đủ của toán tử này dưới dạng ký hiệu mã giả và giải mã nó: Cập nhật tên quan hệ cơ sở Thiết lập {tên thuộc tính - giá trị thuộc tính}, .. Ở đâu tình trạng; Vì vậy, trong dòng đầu tiên của toán tử sau từ khóa Cập nhật tên của quan hệ cơ sở trong đó các bản cập nhật sẽ được thực hiện được viết. Từ khóa Set được dịch từ tiếng Anh là "set", và dòng này của câu lệnh chỉ định tên của các thuộc tính sẽ được cập nhật và các giá trị thuộc tính mới tương ứng. Có thể cập nhật một số thuộc tính cùng một lúc trong một câu lệnh, sau khi sử dụng ký hiệu metalinguistic ", ..". Trên dòng thứ ba sau từ khóa Ở đâu một điều kiện được viết cho thấy chính xác những thuộc tính nào của quan hệ cơ sở này cần được cập nhật; 3) nhà điều hành Xóa bỏcho phép xóa bất kỳ bộ giá trị nào từ quan hệ cơ sở. Hãy viết dạng đầy đủ của nó bằng mã giả và giải thích ý nghĩa của tất cả các đơn vị cú pháp riêng lẻ: Xóa từ tên quan hệ cơ sở Ở đâu tình trạng; Từ khóa từ kết hợp với tên của nhà điều hành Xóa bỏ dịch là "loại bỏ khỏi". Và sau những từ khóa này trong dòng đầu tiên của toán tử, tên của quan hệ cơ sở được chỉ ra, từ đó bất kỳ bộ giá trị nào phải được loại bỏ. Và ở dòng thứ hai của toán tử sau từ khóa Ở đâu ("where") cho biết điều kiện mà các bộ giá trị được chọn không còn bắt buộc trong quan hệ cơ sở của chúng tôi. Bài giảng số 9. Phụ thuộc hàm 1. Hạn chế phụ thuộc chức năng Ràng buộc tính duy nhất được áp đặt bởi khai báo khóa chính và khóa ứng viên của một quan hệ là một trường hợp đặc biệt của ràng buộc liên quan đến khái niệm phụ thuộc chức năng. Để giải thích khái niệm phụ thuộc hàm, hãy xem xét ví dụ sau. Hãy cho chúng tôi một quan hệ chứa dữ liệu về kết quả của một phiên cụ thể. Lược đồ của mối quan hệ này trông giống như sau: Phiên họp (ghi số sách, Họ và tên, Vấn đề, Lớp); Các thuộc tính "Số trong sổ điểm" và "Chủ đề" tạo thành một tổ hợp (vì hai thuộc tính được khai báo là khóa) khóa chính của quan hệ này. Thật vậy, hai thuộc tính này có thể xác định duy nhất giá trị của tất cả các thuộc tính khác. Tuy nhiên, ngoài ràng buộc về tính duy nhất được liên kết với khóa này, mối quan hệ nhất thiết phải tuân theo điều kiện là một sổ điểm được cấp cho một người cụ thể và do đó, về mặt này, các bộ có cùng số sổ điểm phải chứa các giá trị giống nhau Thuộc tính "Họ", "Họ và tên đệm".
Nếu chúng ta có phân đoạn sau của một cơ sở dữ liệu nhất định về học sinh của một cơ sở giáo dục sau một buổi học nhất định, thì trong bộ dữ liệu có số điểm là 100, các thuộc tính "Họ", "Tên" và "Tên viết tắt" giống nhau, và các thuộc tính "Chủ đề" và "Đánh giá" - không khớp (điều này có thể hiểu được, vì chúng đang nói về các chủ đề khác nhau và hiệu suất trong đó). Điều này có nghĩa là các thuộc tính "Last Name", "First Name" và "Patronymic" phụ thuộc vào chức năng trên thuộc tính "Số điểm", trong khi các thuộc tính "Chủ đề" và "Đánh giá" là độc lập về mặt chức năng. Như vậy, phụ thuộc chức năng là một phụ thuộc có giá trị duy nhất được lập bảng trong hệ quản trị cơ sở dữ liệu. Bây giờ chúng tôi đưa ra một định nghĩa chặt chẽ về sự phụ thuộc hàm. Định nghĩa: cho X, Y là các phân thức con của lược đồ quan hệ S, xác định trên lược đồ S sơ đồ phụ thuộc hàm X → Y (đọc "X mũi tên Y"). Hãy xác định ràng buộc phụ thuộc hàm inv <X → Y> như một tuyên bố rằng, liên quan đến lược đồ S, bất kỳ hai bộ giá trị nào phù hợp trong phép chiếu lên địa chỉ con X cũng phải khớp trong phép chiếu vào địa chỉ con Y. Hãy viết định nghĩa tương tự dưới dạng công thức: Inv <X → Y> r (S) = t1, T2 ∈ r (t1[X] = t2[X] ⇒ t1[Y]=t2 [Y]), X, Y ⊆ S; Thật kỳ lạ, định nghĩa này sử dụng khái niệm về phép chiếu một ngôi mà chúng ta đã gặp trước đó. Thật vậy, làm thế nào khác, nếu bạn không sử dụng thao tác này, để hiển thị sự bằng nhau của hai cột trong bảng quan hệ, chứ không phải các hàng, với nhau? Do đó, chúng tôi đã viết về phép toán này rằng sự trùng hợp của các bộ giá trị trong phép chiếu lên một số thuộc tính hoặc một số thuộc tính (tập con X) chắc chắn sẽ dẫn đến sự trùng hợp của các bộ cột giống nhau trên tập con Y trong trường hợp Y phụ thuộc vào X. Điều thú vị là trong trường hợp phụ thuộc hàm của Y vào X, người ta cũng nói rằng X xác định chức năng Y hoặc cái gì Y phụ thuộc vào chức năng trên X. Trong lược đồ phụ thuộc hàm X → Y, mạch con X được gọi là bên trái và mạch con Y được gọi là bên phải. Trong thực hành thiết kế cơ sở dữ liệu, lược đồ phụ thuộc chức năng thường được gọi là phụ thuộc chức năng cho ngắn gọn. Kết thúc định nghĩa. Trong trường hợp đặc biệt khi phía bên phải của phụ thuộc hàm, tức là, địa chỉ con Y, khớp với toàn bộ lược đồ của mối quan hệ, ràng buộc phụ thuộc hàm trở thành ràng buộc duy nhất khóa chính hoặc khóa ứng viên. Có thật không: inv r (S) = ∀ t1, T2 ∈ r (t1[K] = t2 [K] → t1(S) = t2(S)), K ⊆ S; Chỉ là trong việc xác định một phụ thuộc hàm, thay vì tiểu phân X, bạn cần lấy ký hiệu của khóa K, và thay vì bên phải của phụ thuộc hàm, tiểu phân Y, hãy lấy toàn bộ lược đồ của các quan hệ S, tức là, thực sự, giới hạn về tính duy nhất của khóa quan hệ là một trường hợp đặc biệt của giới hạn phụ thuộc hàm khi vế phải là các lược đồ phụ thuộc hàm bằng nhau trong toàn bộ lược đồ quan hệ. Dưới đây là các ví dụ về hình ảnh của sự phụ thuộc hàm: {Số sổ tài khoản} → {Họ, Tên, Chữ viết tắt}; {số lớp, môn học} → {lớp}; 2. Quy tắc suy luận của Armstrong Nếu bất kỳ quan hệ cơ bản nào thỏa mãn các phụ thuộc hàm do vectơ xác định, thì với sự trợ giúp của các quy tắc suy luận đặc biệt khác nhau, có thể thu được các phụ thuộc hàm khác mà quan hệ cơ bản này chắc chắn sẽ thỏa mãn. Một ví dụ điển hình về các quy tắc đặc biệt đó là quy tắc suy luận của Armstrong. Nhưng trước khi tiếp tục phân tích các quy tắc suy luận Armstrong, chúng ta hãy giới thiệu một ký hiệu kim loại học mới "├", được gọi là ký hiệu xác nhận meta khả năng dẫn xuất. Ký hiệu này, khi xây dựng các quy tắc, được viết giữa hai biểu thức cú pháp và chỉ ra rằng công thức ở bên phải của nó có nguồn gốc từ công thức ở bên trái của nó. Bây giờ chúng ta hãy tự hình thành các quy tắc suy luận Armstrong dưới dạng định lý sau. Định lý. Các quy tắc sau đây là hợp lệ, được gọi là quy tắc suy luận của Armstrong. Quy tắc suy luận 1. ├ X → X; Quy tắc suy luận 2. X → Y├ X ∪ Z → Y; Quy tắc suy luận 3. X → Y, Y ∪ W → Z ├ X ∪ W → Z; Ở đây X, Y, Z, W là các tiểu phân tùy ý của lược đồ quan hệ S. Ký hiệu câu lệnh meta khả dẫn phân tách danh sách các tiền đề và danh sách các khẳng định (kết luận). 1. Quy tắc suy luận đầu tiên được gọi là "phản xạ"và đọc như sau:" quy tắc được suy ra: "X theo chức năng của X" ". Đây là quy tắc tính đạo hàm đơn giản nhất của Armstrong. Nó được suy ra theo nghĩa đen từ không khí loãng. Điều thú vị là cần lưu ý rằng sự phụ thuộc hàm có cả hai phần bên trái và bên phải được gọi là phản xạ. Theo quy tắc phản xạ, việc hạn chế phụ thuộc phản xạ được thực hiện tự động. 2. Quy tắc suy luận thứ hai được gọi là "bổ sung"và đọc như sau:" nếu X xác định Y theo chức năng, thì quy tắc được suy ra: "sự kết hợp của các mạch con X và Z theo chức năng kéo theo Y" ". Quy tắc hoàn thành cho phép bạn mở rộng phía bên trái của ràng buộc phụ thuộc chức năng. 3. Quy tắc suy luận thứ ba được gọi là "độ nhạy giả"và đọc như sau:" nếu mạch con X có chức năng bao gồm mạch con Y và sự kết hợp của các mạch con Y và W về mặt chức năng với Z, thì quy tắc được suy ra: "sự kết hợp của các mạch con X và W về mặt chức năng xác định mạch con Z" ". Quy tắc chuyển đổi giả tổng quát quy tắc chuyển đổi tương ứng với trường hợp đặc biệt W: = 0. Chúng ta hãy đưa ra ký hiệu chính thức của quy tắc này: X → Y, Y → Z ├X → Z. Cần lưu ý rằng các tiền đề và kết luận được đưa ra trước đó được trình bày dưới dạng viết tắt bằng cách chỉ định các sơ đồ phụ thuộc hàm. Ở dạng mở rộng, chúng tương ứng với các ràng buộc phụ thuộc hàm sau đây. Quy tắc suy luận 1. mời r(S); Quy tắc suy luận 2. mời r(S) ⇒ inv r(S); Quy tắc suy luận 3. mời r(S)&inv r(S) ⇒ inv r(S); Vẽ bằng chứng các quy tắc suy luận này. 1. Bằng chứng về quy tắc phản xạ tiếp theo trực tiếp từ định nghĩa của ràng buộc phụ thuộc hàm khi tiểu phân X được thay thế bởi tiểu mạch Y. Thật vậy, hãy lấy ràng buộc phụ thuộc hàm: inv r (S) và thay X thay vì Y vào nó, ta được: inv r (S), và đây là quy tắc phản xạ. Quy tắc phản xạ được chứng minh. 2. Bằng chứng về quy tắc bổ sung Hãy minh họa trên sơ đồ của sự phụ thuộc hàm. Sơ đồ đầu tiên là sơ đồ gói: tiền đề: X → Y
Sơ đồ thứ hai: kết luận: X ∪ Z → Y
Để các bộ giá trị bằng nhau trên X ∪ Z. Khi đó chúng bằng nhau trên X. Theo tiền đề, chúng cũng sẽ bằng nhau trên Y. Quy tắc bổ sung đã được chứng minh. 3. Bằng chứng về quy tắc siêu nhạy cảm giả chúng tôi cũng sẽ minh họa trên các sơ đồ, trong trường hợp cụ thể này sẽ là ba. Sơ đồ đầu tiên là tiền đề đầu tiên: tiền đề 1: X → Y
tiền đề 2: Y ∪ W → Z
Và cuối cùng, sơ đồ thứ ba là sơ đồ kết luận: kết luận: X ∪ W → Z
Để các bộ giá trị bằng nhau trên X ∪ W. Khi đó chúng bằng nhau trên cả X và W. Theo Phương án 1, chúng cũng sẽ bằng nhau trên Y. Do đó, theo Phương án 2, chúng cũng sẽ bằng nhau trên Z. Quy tắc độ nhạy giả được chứng minh. Tất cả các quy tắc đều được chứng minh. 3. Quy tắc suy luận bắt nguồn Một ví dụ khác về các quy tắc mà theo đó người ta có thể, nếu cần, tạo ra các quy tắc mới về sự phụ thuộc hàm là cái gọi là quy tắc suy luận có nguồn gốc. Những quy tắc này là gì, làm thế nào để đạt được? Người ta biết rằng nếu những quy tắc khác được suy ra từ một số quy tắc đã tồn tại bằng các phương pháp logic hợp pháp, thì những quy tắc mới này, được gọi là các dẫn xuất, có thể được sử dụng cùng với các quy tắc ban đầu. Cần đặc biệt lưu ý rằng những quy tắc rất tùy tiện này là "đạo hàm" chính xác từ các quy tắc suy luận của Armstrong mà chúng ta đã xem qua trước đó. Chúng ta hãy xây dựng các quy tắc dẫn xuất để lấy phụ thuộc hàm dưới dạng định lý sau. Định lý. Các quy tắc sau đây được rút ra từ các quy tắc suy luận của Armstrong. Quy tắc suy luận 1. ├ X ∪ Z → X; Quy tắc suy luận 2. X → Y, X → Z ├ X ∪ Y → Z; Quy tắc suy luận 3. X → Y ∪ Z ├ X → Y, X → Z; Ở đây X, Y, Z, W, như trong trường hợp trước, là các tiểu phân tùy ý của lược đồ quan hệ S. 1. Quy tắc dẫn xuất đầu tiên được gọi là quy tắc tầm thường và đọc như thế này: "Quy tắc được suy ra: 'sự kết hợp của các thẻ con X và Z về mặt chức năng bao gồm X'". Một phụ thuộc hàm với phía bên trái là một tập hợp con của phía bên phải được gọi là không đáng kể. Theo quy tắc tầm thường, các ràng buộc phụ thuộc tầm thường sẽ tự động được thực thi. Điều thú vị là, quy tắc tầm thường là một tổng quát của quy tắc phản xạ và, giống như quy tắc sau, có thể được rút ra trực tiếp từ định nghĩa của ràng buộc phụ thuộc hàm. Thực tế là quy tắc này được hình thành không phải ngẫu nhiên và có liên quan đến tính hoàn chỉnh của hệ thống các quy tắc của Armstrong. Chúng ta sẽ nói nhiều hơn về sự hoàn chỉnh của hệ thống các quy tắc của Armstrong một chút sau. 2. Quy tắc dẫn xuất thứ hai được gọi là quy tắc cộng gộp và đọc như sau: "Nếu mạch con X xác định chức năng của mạch con Y và X đồng thời xác định Z về mặt chức năng, thì quy tắc sau được suy ra từ các quy tắc này:" X xác định chức năng hợp nhất của các mạch con Y và Z "". 3. Quy tắc dẫn xuất thứ ba được gọi là quy tắc dự báo hoặc quy tắcsự đảo ngược độ nhạy". Nó có nội dung như sau:" Nếu mạch con X xác định chức năng kết hợp của các mạch con Y và Z, thì quy tắc sau được suy ra từ quy tắc này: "X xác định theo chức năng của mạch con Y và đồng thời X xác định theo chức năng của mạch con Z "", tức là, quy tắc dẫn xuất này là quy tắc cộng đảo ngược. Điều tò mò là các quy tắc cộng tính và tính dự tính được áp dụng cho các phụ thuộc hàm với các phần bên trái giống nhau cho phép người ta kết hợp hoặc ngược lại, tách các phần bên phải của phụ thuộc. Khi xây dựng chuỗi suy luận, sau khi hình thành tất cả các tiền đề, quy tắc chuyển đổi được áp dụng để bao gồm sự phụ thuộc hàm với vế phải trong kết luận. Vẽ bằng chứng liệt kê các quy tắc suy luận tùy ý. 1. Bằng chứng về quy tắc sự tầm thường. Hãy để chúng tôi thực hiện nó, giống như tất cả các bằng chứng tiếp theo, từng bước: 1) ta có: X → X (từ suy ra quy tắc phản xạ của Armstrong); 2) xa hơn, chúng ta có: X ∪ Z → X (thu được bằng cách áp dụng quy tắc hoàn thành suy luận của Armstrong trước tiên, và sau đó là hệ quả của bước đầu tiên của chứng minh). Quy tắc tầm thường đã được chứng minh. 2. Chúng tôi sẽ thực hiện từng bước chứng minh quy tắc sự bổ sung: 1) ta có: X → Y (đây là tiền đề 1); 2) ta có: X → Z (đây là tiền đề 2); 3) ta có: Y ∪ Z → Y ∪ Z (từ suy ra quy tắc phản xạ của Armstrong); 4) chúng ta có: X ∪ Z → Y ∪ Z (thu được bằng cách áp dụng quy tắc chuyển giả trong suy luận của Armstrong, và sau đó là hệ quả của bước đầu tiên và bước thứ ba của chứng minh); 5) ta có: X ∪ X → Y ∪ Z (thu được bằng cách áp dụng quy tắc suy luận giả siêu nhạy của Armstrong, sau đó làm theo từ bước thứ hai và thứ tư); 6) chúng ta có X → Y ∪ Z (tiếp theo từ bước thứ năm). Quy tắc cộng được chứng minh. 3. Và cuối cùng, chúng ta sẽ xây dựng một chứng minh của quy tắc tính tiên tri: 1) ta có: X → Y ∪ Z, X → Y ∪ Z (đây là tiền đề); 2) ta có: Y → Y, Z → Z (suy ra bằng cách sử dụng quy tắc phản xạ suy luận của Armstrong); 3) ta có: Y ∪ z → y, Y ∪ z → Z (nhận được từ quy tắc hoàn thành suy luận của Armstrong và hệ quả từ bước thứ hai của chứng minh); 4) chúng ta có: X → Y, X → Z (thu được bằng cách áp dụng quy tắc giả quá độ trong suy luận của Armstrong, và sau đó là hệ quả của bước đầu tiên và bước thứ ba của chứng minh). Quy luật dự báo được chứng minh. Tất cả các quy tắc suy luận đạo hàm đều được chứng minh. 4. Tính hoàn chỉnh của hệ thống các quy tắc Amstrong Gọi F (S) là một tập các phụ thuộc hàm đã cho được xác định trên lược đồ quan hệ S. Biểu thị bởi mời ràng buộc được áp đặt bởi tập hợp các phụ thuộc hàm này. Hãy viết nó ra: inv r (S) = ∀X → Y ∈F (S) [inv r (S)]. Vì vậy, tập hợp các hạn chế do phụ thuộc hàm áp đặt này được giải mã như sau: đối với bất kỳ quy tắc nào từ hệ phụ thuộc hàm X → Y thuộc tập phụ thuộc hàm F (S), giới hạn của phụ thuộc hàm inv r (S) được xác định trên tập quan hệ r (S). Cho một số quan hệ r (S) thỏa mãn ràng buộc này. Bằng cách áp dụng các quy tắc suy luận của Armstrong cho các phụ thuộc hàm được xác định cho tập F (S), người ta có thể thu được các phụ thuộc hàm mới, như chúng ta đã nói và chứng minh trước đây. Và, điều này cho thấy, quan hệ F (S) sẽ tự động thỏa mãn các hạn chế của các phụ thuộc hàm này, như có thể thấy từ dạng mở rộng của các quy tắc suy luận của Armstrong. Nhắc lại dạng tổng quát của các quy tắc suy luận mở rộng này: Quy tắc suy luận 1. inv < X → X > r(S); Quy tắc suy luận 2. mời r(S) ⇒ inv <X ∪ Z → Y> r (S); Quy tắc suy luận 3. mời r(S) & inv <Y ∪ W → Z> r (S) ⇒ inv <X ∪ W → Z>; Quay trở lại lý luận của chúng ta, chúng ta hãy bổ sung tập F (S) với các phụ thuộc mới bắt nguồn từ nó bằng cách sử dụng các quy tắc của Armstrong. Chúng tôi sẽ áp dụng quy trình bổ sung này cho đến khi chúng tôi không còn nhận được các phụ thuộc chức năng mới. Kết quả của việc xây dựng này, chúng ta sẽ nhận được một tập hợp các phụ thuộc hàm mới, được gọi là Khép kín đặt F (S) và ký hiệu là F+(S). Thật vậy, một cái tên như vậy khá hợp lý, bởi vì cá nhân chúng tôi, qua một quá trình xây dựng lâu dài, đã "đóng" tập hợp các phụ thuộc chức năng hiện có vào chính nó, thêm (do đó là dấu "+") tất cả các phụ thuộc chức năng mới là kết quả của những phụ thuộc chức năng hiện có. Cần lưu ý rằng quá trình xây dựng bao đóng này là hữu hạn, bởi vì bản thân lược đồ quan hệ, trên đó tất cả các kết cấu này được thực hiện, là hữu hạn. Không cần phải nói rằng một đóng là một tập trên của tập đang được đóng (thực sự, nó lớn hơn!) Và không thay đổi theo bất kỳ cách nào khi nó được đóng lại. Nếu chúng ta viết những gì vừa được nói ở dạng công thức, chúng ta nhận được: F (S) ⊆ F+(S), [F+(S)]+=F+(S); Hơn nữa, từ sự thật đã được chứng minh (tức là tính hợp pháp, tính hợp pháp) của các quy tắc suy luận của Armstrong và định nghĩa của bao đóng, nó theo sau rằng bất kỳ quan hệ nào thỏa mãn các ràng buộc của một tập hợp phụ thuộc hàm đã cho sẽ thỏa mãn ràng buộc của phụ thuộc thuộc về bao đóng. . X → Y ∈ F+(S) ⇒ ∀r (S) [inv r (S) ⇒ inv r (S)]; Vì vậy, định lý về tính đầy đủ của Armstrong cho hệ thống các quy tắc suy luận phát biểu rằng hàm ý bên ngoài hoàn toàn có thể được thay thế bằng sự tương đương một cách hợp pháp và chính đáng. (Chúng tôi sẽ không xem xét việc chứng minh định lý này, vì bản thân quá trình chứng minh không quá quan trọng trong quá trình giảng dạy cụ thể của chúng tôi.) Bài giảng số 10. Các dạng thông thường 1. Ý nghĩa của việc chuẩn hóa lược đồ cơ sở dữ liệu Khái niệm mà chúng ta sẽ xem xét trong phần này có liên quan đến khái niệm phụ thuộc hàm, tức là ý nghĩa của việc chuẩn hóa lược đồ cơ sở dữ liệu được liên kết chặt chẽ với khái niệm về các hạn chế được áp đặt bởi một hệ thống phụ thuộc hàm và phần lớn tuân theo khái niệm này. Điểm bắt đầu của bất kỳ thiết kế cơ sở dữ liệu nào là biểu diễn miền dưới dạng một hoặc nhiều mối quan hệ và ở mỗi bước thiết kế, một số tập hợp các lược đồ quan hệ được tạo ra có thuộc tính "nâng cao". Do đó, quá trình thiết kế là một quá trình chuẩn hóa các mẫu quan hệ, với mỗi dạng chuẩn kế tiếp có các thuộc tính tốt hơn dạng trước. Mỗi dạng chuẩn có một bộ ràng buộc nhất định và một quan hệ ở dạng chuẩn nhất định nếu nó thỏa mãn bộ ràng buộc của chính nó. Một ví dụ là giới hạn của dạng chuẩn đầu tiên - các giá trị của tất cả các thuộc tính của quan hệ là nguyên tử. Trong lý thuyết cơ sở dữ liệu quan hệ, chuỗi các dạng thông thường sau đây thường được phân biệt: 1) dạng chuẩn đầu tiên (1 NF); 2) dạng chuẩn thứ hai (2 NF); 3) dạng chuẩn thứ ba (3 NF); 4) Boyce-Codd dạng bình thường (BCNF); 5) dạng chuẩn thứ tư (4 NF); 6) dạng chuẩn thứ năm, hoặc dạng chuẩn nối phép chiếu (5 NF hoặc PJ / NF). (Nội dung bài giảng này bao gồm thảo luận chi tiết về bốn dạng thức đầu tiên của quan hệ cơ bản, vì vậy chúng tôi sẽ không phân tích chi tiết dạng thức thứ tư và thứ năm.) Các thuộc tính chính của các dạng thông thường như sau: 1) mỗi dạng bình thường sau theo một nghĩa nào đó tốt hơn dạng bình thường trước đó; 2) khi chuyển sang dạng chuẩn tiếp theo, các thuộc tính của dạng chuẩn trước đó được bảo toàn. Quá trình thiết kế dựa trên phương pháp chuẩn hóa, tức là phân tách một quan hệ ở dạng chuẩn trước đó thành hai hoặc nhiều quan hệ thỏa mãn các yêu cầu của dạng chuẩn tiếp theo (chúng ta sẽ gặp phải điều này khi chính chúng ta phải chuẩn hóa mối quan hệ đó khi chúng ta xem qua tài liệu). hoặc một số mối quan hệ cơ bản khác). Như đã đề cập trong phần tạo mối quan hệ cơ bản, các tập hợp phụ thuộc hàm đã cho áp đặt các hạn chế thích hợp lên các lược đồ của mối quan hệ cơ bản. Những hạn chế này thường được thực hiện theo hai cách: 1) khai báo, tức là, bằng cách khai báo các loại khóa chính, khóa ứng viên và khóa ngoại khác nhau trong quan hệ cơ sở (đây là phương pháp được sử dụng rộng rãi nhất); 2) về mặt thủ tục, tức là viết mã chương trình (sử dụng cái gọi là trình kích hoạt được đề cập ở trên). Với sự trợ giúp của logic đơn giản, bạn có thể hiểu điểm chuẩn hóa các lược đồ cơ sở dữ liệu là gì. Để chuẩn hóa cơ sở dữ liệu hoặc đưa cơ sở dữ liệu về dạng bình thường có nghĩa là xác định các lược đồ quan hệ cơ bản như vậy để giảm thiểu nhu cầu viết mã chương trình, tăng hiệu suất cơ sở dữ liệu và tạo điều kiện duy trì tính toàn vẹn của dữ liệu theo trạng thái và tính toàn vẹn tham chiếu. Đó là, làm cho mã và làm việc với nó đơn giản và thuận tiện nhất có thể cho các nhà phát triển và người dùng. Để chứng minh một cách trực quan so sánh hoạt động của cơ sở dữ liệu chưa chuẩn hóa và chuẩn hóa, hãy xem xét ví dụ sau. Hãy để chúng tôi có một quan hệ cơ sở chứa thông tin về kết quả của phiên kiểm tra. Chúng tôi đã xem xét một cơ sở dữ liệu như vậy trước đây. Vì vậy, tùy chọn 1 các lược đồ cơ sở dữ liệu. Phiên họp (ghi số sách, Họ và tên, Vấn đề, Lớp) Trong mối quan hệ này, như bạn có thể thấy từ hình ảnh lược đồ quan hệ cơ sở, một khóa chính tổng hợp được xác định: Khóa chính (số sách lớp, Chủ đề); Cũng về vấn đề này, một hệ thống các phụ thuộc hàm được thiết lập: {Số sổ tài khoản} → {Họ, Tên, Chữ viết tắt}; Đây là dạng xem dạng bảng của một phân đoạn nhỏ của cơ sở dữ liệu với lược đồ quan hệ này. Chúng tôi đã sử dụng đoạn này trong việc xem xét các hạn chế của phụ thuộc hàm, vì vậy sẽ khá dễ dàng để chúng tôi hiểu chủ đề này bằng cách sử dụng ví dụ của nó.
Ở đây, để duy trì tính toàn vẹn của dữ liệu theo trạng thái, tức là đáp ứng hạn chế của hệ thống phụ thuộc hàm {số sách lớp} → {Last name, First name, Patronymic} khi thay đổi, ví dụ, họ, nó là cần thiết để xem qua tất cả các bộ giá trị của mối quan hệ cơ bản này và nhập tuần tự các thay đổi cần thiết. Tuy nhiên, vì đây là một quá trình khá cồng kềnh và tốn thời gian (đặc biệt nếu chúng ta đang xử lý cơ sở dữ liệu của một cơ sở giáo dục lớn), các nhà phát triển hệ quản trị cơ sở dữ liệu đã đi đến kết luận rằng quá trình này cần được tự động hóa, nghĩa là , được thực hiện tự động. Giờ đây, việc kiểm soát việc thực hiện phụ thuộc hàm này (và bất kỳ phụ thuộc hàm nào khác) có thể được tổ chức tự động bằng cách sử dụng khai báo chính xác các khóa khác nhau trong quan hệ cơ sở và cái gọi là phân rã (nghĩa là chia một cái gì đó thành nhiều phần độc lập) của điều này quan hệ. Vì vậy, hãy chia lược đồ mối quan hệ "Phiên" hiện có của chúng ta thành hai lược đồ: lược đồ "Sinh viên", chỉ chứa thông tin về sinh viên của một cơ sở giáo dục nhất định và lược đồ "Phiên", chứa thông tin về phiên trước đó. Và sau đó chúng tôi sẽ khai báo các khóa theo cách mà chúng tôi có thể dễ dàng nhận được bất kỳ thông tin cần thiết nào. Hãy cho biết các lược đồ mối quan hệ mới này với các khóa của chúng sẽ trông như thế nào. Tùy chọn 2 các lược đồ cơ sở dữ liệu. Sinh viên (ghi số sách, Họ và tên), Khoá chính (số sách lớp). Phiên họp (Số sổ ghi, Chủ đề, Lớp), Khóa chính (số sách lớp, Chủ đề), Khoá ngoại (số sổ điểm) tài liệu tham khảo Học sinh (số sổ điểm). Chúng ta có những gì bây giờ? Liên quan đến "Học sinh", khóa chính "Số bảng điểm" xác định chức năng ba thuộc tính khác: "Họ", "Tên" và "Chữ viết tắt". Và liên quan đến "Phiên", khóa chính tổng hợp "Số Sổ điểm, Chủ đề" cũng rõ ràng, tức là, xác định theo nghĩa đen thuộc tính cuối cùng của lược đồ mối quan hệ này - "Điểm". Và mối liên hệ giữa hai mối quan hệ này đã được thiết lập: nó được thực hiện thông qua khóa bên ngoài của mối quan hệ "Phiên" "Sổ điểm số", tham chiếu đến thuộc tính cùng tên trong mối quan hệ "Học sinh" và khi được yêu cầu, cung cấp tất cả các thông tin cần thiết. Bây giờ chúng ta hãy chỉ ra các mối quan hệ được biểu diễn bởi các bảng tương ứng với tùy chọn thứ hai là chỉ định các lược đồ cơ sở dữ liệu tương ứng sẽ như thế nào.
Do đó, chúng ta thấy rằng mục tiêu của việc chuẩn hóa theo các hạn chế do các phụ thuộc hàm áp đặt là nhu cầu áp đặt các phụ thuộc hàm được yêu cầu vào bất kỳ cơ sở dữ liệu nào bằng cách sử dụng các khai báo của nhiều loại khóa chính, khóa ứng viên và khóa ngoại của các quan hệ cơ sở. 2. Dạng chuẩn đầu tiên (1NF) Trong giai đoạn đầu của quá trình thiết kế cơ sở dữ liệu và phát triển các chương trình quản lý cơ sở dữ liệu, các thuộc tính đơn giản và rõ ràng đã được sử dụng như các đơn vị mã hiệu quả và hợp lý nhất. Sau đó, họ sử dụng cùng với các thuộc tính đơn giản và phức hợp, cũng như cùng với các thuộc tính đơn giá trị và đa giá trị. Hãy để chúng tôi giải thích ý nghĩa của từng khái niệm này. Thuộc tính tổng hợp, trái ngược với những thuộc tính đơn giản, là các thuộc tính được tạo thành từ một số thuộc tính đơn giản. Thuộc tính đa giá trị, không giống như các thuộc tính có giá trị đơn, là các thuộc tính đại diện cho nhiều giá trị. Dưới đây là các ví dụ về các thuộc tính đơn giá trị, phức hợp, đơn giá trị và đa giá trị. Hãy xem xét bảng sau đại diện cho mối quan hệ:
Ở đây thuộc tính "Điện thoại" là đơn giản, rõ ràng và thuộc tính "Địa chỉ" đơn giản, nhưng có nhiều giá trị. Bây giờ hãy xem xét một bảng khác, với các thuộc tính khác nhau:
Trong mối quan hệ này, được biểu thị bằng bảng, thuộc tính "Điện thoại" là đơn giản nhưng có nhiều giá trị và thuộc tính "Địa chỉ" vừa là hỗn hợp vừa là đa giá trị. Nói chung, có thể kết hợp nhiều thuộc tính đơn giản hoặc phức hợp. Trong các trường hợp khác nhau, các bảng đại diện cho các mối quan hệ nói chung có thể trông như thế này:
Khi chuẩn hóa các lược đồ quan hệ cơ bản, người lập trình có thể sử dụng một trong bốn dạng chuẩn phổ biến nhất: dạng chuẩn đầu tiên (1NF), dạng chuẩn thứ hai (2NF), dạng chuẩn thứ ba (3NF) hoặc dạng chuẩn Boyce-Codd (NFBC) . Để làm rõ: chữ viết tắt NF là chữ viết tắt của cụm từ tiếng Anh Normal Form. Về hình thức, ngoài những loại trên, còn có những loại hình bình thường khác, nhưng những hình thức trên là một trong những loại phổ biến nhất. Hiện tại, các nhà phát triển cơ sở dữ liệu đang cố gắng tránh các thuộc tính phức hợp và đa giá trị để không làm phức tạp việc viết mã, không làm quá tải cấu trúc của nó và không gây nhầm lẫn cho người dùng. Từ những cân nhắc này, định nghĩa của dạng chuẩn đầu tiên tuân theo một cách logic. Sự định nghĩa. Bất kỳ mối quan hệ cơ sở nào đều nằm trong dạng bình thường đầu tiên nếu và chỉ khi lược đồ của mối quan hệ này chỉ chứa các thuộc tính đơn giản và chỉ có giá trị duy nhất và nhất thiết phải có cùng ngữ nghĩa. Để giải thích trực quan sự khác biệt giữa quan hệ chuẩn hóa và không chuẩn hóa, hãy xem xét một ví dụ. Giả sử, có một quan hệ không chuẩn hóa, với sơ đồ sau. Vì vậy, tùy chọn 1 lược đồ quan hệ với một khóa chính đơn giản được xác định trên đó: Người lao động (số nhân sự, Họ, Tên, Tên viết tắt, Mã chức vụ, Điện thoại, Ngày nhận hoặc miễn nhiệm); Khoá chính (số nhân sự); Hãy để chúng tôi liệt kê những lỗi nào có trong lược đồ mối quan hệ này, tức là chúng ta sẽ đặt tên cho những dấu hiệu làm cho lược đồ này không được chuẩn hóa thích hợp: 1) thuộc tính "Tên viết tắt của Họ" là hỗn hợp, tức là bao gồm các phần tử không đồng nhất; 2) thuộc tính "Điện thoại" là nhiều giá trị, tức là giá trị của nó là một tập hợp các giá trị; 3) thuộc tính "Ngày chấp nhận hoặc sa thải" không có ngữ nghĩa rõ ràng, tức là trong trường hợp thứ hai, không rõ ngày nào được nhập. Ví dụ: nếu một thuộc tính bổ sung được đưa vào để xác định chính xác hơn ý nghĩa của ngày, thì giá trị của thuộc tính này sẽ rõ ràng về mặt ngữ nghĩa, nhưng vẫn có thể lưu trữ chỉ một trong những ngày được chỉ định cho mỗi nhân viên. Cần phải làm gì để đưa mối quan hệ này về dạng bình thường? Đầu tiên, cần phải chia các thuộc tính hỗn hợp thành các thuộc tính đơn giản để loại trừ các thuộc tính rất phức hợp này, cũng như các thuộc tính có ngữ nghĩa tổng hợp. Và thứ hai, cần phải phân tách quan hệ này, tức là cần phải chia nó thành một số quan hệ độc lập mới để loại trừ các thuộc tính đa giá trị. Do đó, tính đến tất cả những điều trên, sau khi giảm quan hệ "Nhân viên" về dạng chuẩn đầu tiên hoặc 1NF bằng cách phân rã nó, chúng ta sẽ thu được một hệ thống các quan hệ sau với các khóa chính và khóa ngoại được đặt trên chúng. Vì vậy, tùy chọn 2 quan hệ: Người lao động (số nhân sựHọ, Tên, Tên viết tắt, Mã chức vụ, Ngày nhận, Ngày miễn nhiệm); Khoá chính (số nhân sự); Những cái điện thoại (Mã số nhân sự, Điện thoại); Khóa chính (số nhân sự, Điện thoại); Khóa ngoại (số nhân sự) tham chiếu Nhân viên (số nhân sự); Vậy chúng ta thấy gì? Thuộc tính ghép "Họ Tên Tên viết tắt" không còn trong mối quan hệ của chúng ta nữa, thay vào đó là ba thuộc tính đơn giản "Họ", "Tên" và "Tên viết tắt", do đó lý do này cho sự "bất thường" của mối quan hệ đã bị loại trừ . Ngoài ra, thay vì thuộc tính có ngữ nghĩa không rõ ràng "Ngày tuyển dụng hoặc sa thải", giờ đây chúng ta có hai thuộc tính "Ngày nhập học" và "Ngày sa thải", mỗi thuộc tính có ngữ nghĩa không rõ ràng. Do đó, lý do thứ hai khiến mối quan hệ "Nhân viên" của chúng tôi không ở dạng bình thường cũng được loại bỏ một cách an toàn. Và, cuối cùng, lý do cuối cùng khiến quan hệ "Nhân viên" không được chuẩn hóa là do sự hiện diện của thuộc tính đa giá trị "Điện thoại". Để loại bỏ thuộc tính này, cần phải phân hủy toàn bộ mối quan hệ. Kết quả của sự phân tách này, thuộc tính "Điện thoại" đã bị loại trừ khỏi quan hệ ban đầu "Nhân viên" nói chung, nhưng một quan hệ thứ hai đã được hình thành - "Điện thoại", trong đó có hai thuộc tính: "số nhân viên của nhân viên" và "Điện thoại ", tức là tất cả các thuộc tính - một lần nữa đơn giản, điều kiện thuộc về dạng chuẩn đầu tiên được thỏa mãn. Các thuộc tính "Số nhân viên" và "Điện thoại" này tạo thành khóa chính tổng hợp của mối quan hệ "Điện thoại" và thuộc tính "Số nhân viên", là khóa ngoại tham chiếu đến thuộc tính cùng tên trong "Nhân viên "Mối quan hệ, tức là trong mối quan hệ Thuộc tính" Điện thoại "của khóa chính" số nhân sự "cũng là khóa ngoại tham chiếu đến khóa chính của mối quan hệ" Nhân viên ". Do đó, một liên kết được cung cấp giữa hai mối quan hệ. Sử dụng liên kết này, bạn có thể hiển thị toàn bộ danh sách điện thoại của mình theo số lượng nhân sự của bất kỳ nhân viên nào mà không tốn nhiều công sức và thời gian mà không cần sử dụng các thuộc tính tổng hợp. Lưu ý rằng nếu có các phụ thuộc hàm trong mối quan hệ với hệ thống, thì sau tất cả các phép biến đổi ở trên, quá trình chuẩn hóa sẽ không hoàn thành. Tuy nhiên, trong ví dụ cụ thể này, không có ràng buộc phụ thuộc hàm, vì vậy không cần chuẩn hóa thêm mối quan hệ này. 3. Dạng chuẩn thứ hai (2NF) Các yêu cầu mạnh hơn được áp đặt cho các quan hệ theo dạng chuẩn thứ hai, hoặc 2NF. Điều này là do định nghĩa của dạng quan hệ thông thường thứ hai ngụ ý, trái ngược với dạng chuẩn đầu tiên, sự hiện diện của một hệ thống các hạn chế đối với các phụ thuộc hàm. Sự định nghĩa. Mối quan hệ cơ sở là trong dạng bình thường thứ hai liên quan đến một tập hợp các phụ thuộc chức năng nhất định nếu và chỉ khi nó ở dạng chuẩn đầu tiên và ngoài ra, mỗi thuộc tính không phải khóa phụ thuộc đầy đủ về mặt chức năng vào mỗi khóa. Theo định nghĩa này thuộc tính không khóa là bất kỳ thuộc tính quan hệ nào không có trong bất kỳ khóa chính hoặc khóa ứng viên nào của quan hệ. Sự phụ thuộc đầy đủ chức năng vào một khóa ngụ ý không có sự phụ thuộc chức năng vào bất kỳ phần nào của khóa đó. Do đó, bây giờ, khi chuẩn hóa một quan hệ, chúng ta cũng phải giám sát việc đáp ứng các điều kiện để quan hệ ở dạng chuẩn đầu tiên, tức là, đảm bảo rằng các thuộc tính của nó là đơn giản và rõ ràng, cũng như việc đáp ứng điều kiện thứ hai liên quan đến các hạn chế của phụ thuộc hàm. Rõ ràng là các quan hệ với các khóa đơn giản (chính và ứng viên) chắc chắn ở dạng bình thường thứ hai. Thật vậy, trong trường hợp này, sự phụ thuộc vào một phần của khóa dường như không thể thực hiện được, bởi vì khóa đơn giản là không có bất kỳ bộ phận riêng biệt nào. Bây giờ, như trong phần trước của chủ đề, hãy xem xét một ví dụ về lược đồ quan hệ không chuẩn hóa và chính quá trình chuẩn hóa. Vì vậy, tùy chọn 1 lược đồ quan hệ: Đối tượng (Số tòa nhà, Thính phòng số, Diện tích sq. m, Số chỉ huy phục vụ của quân đoàn); Khóa chính (số kho, số đối tượng); Ngoài ra, hệ thống phụ thuộc hàm sau đây được xác định: {Số của quân đoàn} → {Số của người chỉ huy phục vụ của quân đoàn}; Chúng ta thấy gì? Tất cả các điều kiện để mối quan hệ này "Đối tượng" duy trì ở dạng chuẩn đầu tiên được thỏa mãn, bởi vì mọi thuộc tính đơn lẻ của mối quan hệ này là rõ ràng và đơn giản. Nhưng điều kiện mà mỗi phần tử không phải khóa phải hoàn toàn phụ thuộc về mặt chức năng vào khóa không được thỏa mãn. Tại sao? Có, vì thuộc tính "số nhân viên của tư lệnh quân đoàn" về mặt chức năng không phụ thuộc vào khóa tổng hợp "số quân đoàn, số đối tượng", mà phụ thuộc vào một phần của khóa này, tức là vào thuộc tính "số quân đoàn". Thật vậy, sau tất cả, chính số quân đoàn quyết định hoàn toàn việc chỉ định người chỉ huy nào cho nó, và đến lượt nó, số lượng phục vụ của tư lệnh quân đoàn không thể phụ thuộc vào bất kỳ số lượng khán phòng nào. Do đó, nhiệm vụ chính của quá trình chuẩn hóa của chúng ta trở thành nhiệm vụ đảm bảo rằng các khóa được phân phối theo cách mà cụ thể là thuộc tính "Không. Để đạt được điều này, chúng ta sẽ phải áp dụng lại, như trong đoạn trước, việc phân tách quan hệ. Vì vậy, hệ thống quan hệ sau đây, tùy chọn 2 Mối quan hệ "Đối tượng" chỉ có được từ mối quan hệ ban đầu bằng cách phân tách nó thành một số mối quan hệ độc lập mới: Quân đoàn (Thân tàu không., số chỉ huy nhân sự của quân đoàn); Khóa chính (số trường hợp); Đối tượng (Số tòa nhà, Thính phòng số, Diện tích sq. m); Khóa chính (số kho, số đối tượng); Khóa ngoại (số trường hợp) tham chiếu Các trường hợp (số trường hợp); Chúng ta thấy gì bây giờ? Đối với thuộc tính không phải khóa của "Corpus" "Số nhân viên của chỉ huy quân đoàn" hoàn toàn phụ thuộc vào khóa chính "Số quân đoàn". Ở đây, điều kiện để tìm quan hệ ở dạng chuẩn thứ hai được thỏa mãn đầy đủ. Bây giờ chúng ta hãy chuyển sang việc xem xét mối quan hệ thứ hai - "Đối tượng". Đối với "Đối tượng", thuộc tính khóa chính "Trường hợp #" cũng là khóa ngoại đề cập đến khóa chính của mối quan hệ "Trường hợp". Về vấn đề này, thuộc tính không phải khóa "Diện tích mq. M" hoàn toàn phụ thuộc vào toàn bộ khóa chính tổng hợp "Tòa nhà #, Thính phòng #" và không, thậm chí không thể phụ thuộc vào bất kỳ bộ phận nào của nó. Như vậy, bằng cách phân rã quan hệ ban đầu, chúng ta đã đi đến kết luận rằng tất cả các điều kiện từ định nghĩa của dạng chuẩn thứ hai đều được thỏa mãn đầy đủ. Trong ví dụ này, tất cả các yêu cầu phụ thuộc chức năng được áp đặt bởi khai báo khóa chính (không có khóa ứng viên ở đây) và khóa ngoại. Do đó, không cần chuẩn hóa thêm. 4. Dạng thông thường thứ ba (3NF) Dạng bình thường tiếp theo mà chúng ta sẽ xem xét là dạng bình thường thứ ba (hoặc 3NF). Không giống như dạng chuẩn đầu tiên, cũng như dạng chuẩn thứ hai, dạng thứ ba ngụ ý gán một hệ thống các phụ thuộc hàm cùng với quan hệ. Chúng ta hãy hình thành các thuộc tính mà một quan hệ phải có để nó được rút gọn về dạng chuẩn thứ ba. Sự định nghĩa. Mối quan hệ cơ sở là trong hình thức bình thường thứ ba đối với một tập hợp các phụ thuộc chức năng đã cho nếu và chỉ khi nó ở dạng chuẩn thứ hai và mỗi thuộc tính không phải khóa chỉ phụ thuộc đầy đủ về mặt chức năng vào các khóa. Do đó, các yêu cầu của dạng chuẩn thứ ba mạnh hơn các yêu cầu của dạng chuẩn thứ nhất và thứ hai, thậm chí kết hợp với nhau. Trên thực tế, ở dạng chuẩn thứ ba, mọi thuộc tính không phải khóa phụ thuộc vào khóa, và toàn bộ khóa, và không phụ thuộc vào gì khác ngoài khóa. Hãy để chúng tôi minh họa quá trình đưa một quan hệ không chuẩn hóa về dạng chuẩn thứ ba. Để làm điều này, hãy xem xét một ví dụ: một quan hệ không ở dạng chuẩn thứ ba. Vì vậy, tùy chọn 1 sơ đồ của mối quan hệ "Nhân viên": Người lao động (số nhân sự, Họ, Tên, Tên viết tắt, Mã chức vụ, Mức lương); Khoá chính (số nhân sự); Ngoài ra, hệ thống phụ thuộc chức năng sau được đặt bên trên mối quan hệ "Nhân viên" này: {Mã chức vụ} → {Mức lương}; Thật vậy, theo quy luật, số tiền lương, tức là số tiền lương, phụ thuộc trực tiếp vào vị trí, và do đó, vào mã của nó trong cơ sở dữ liệu tương ứng. Đó là lý do tại sao mối quan hệ "Nhân viên" này không ở dạng thông thường thứ ba, vì hóa ra thuộc tính không phải khóa "Lương" hoàn toàn phụ thuộc về mặt chức năng vào thuộc tính "Mã chức vụ", mặc dù thuộc tính này không phải là thuộc tính khóa. Thật kỳ lạ, bất kỳ quan hệ nào cũng được giảm xuống dạng chuẩn thứ ba theo cách giống hệt như với hai dạng trước dạng này, cụ thể là bằng cách phân hủy. Sau khi phân tách quan hệ "Nhân viên", chúng tôi thu được hệ thống các quan hệ độc lập mới sau: Vì vậy, tùy chọn 2 sơ đồ của mối quan hệ "Nhân viên": Vị trí (Mã chức vụ, Lương); Khóa chính (mã chức vụ); Người lao động (số nhân sự, Họ, Tên, Chữ viết tắt, Mã chức vụ); Khóa chính (mã chức vụ); Khóa ngoại (Mã chức vụ) tham chiếu Các vị trí (Mã chức vụ); Như chúng ta thấy, liên quan đến "Chức vụ", thuộc tính không phải khóa "Lương" hoàn toàn phụ thuộc về mặt chức năng vào khóa chính đơn giản "Mã chức vụ" và chỉ trên khóa này. Lưu ý rằng liên quan đến "Nhân viên", tất cả bốn thuộc tính không phải khóa "Họ", "Tên", "Tên viết tắt" và "Mã chức vụ" hoàn toàn phụ thuộc vào khóa chính đơn giản "Số việc làm". Về mặt này, thuộc tính "ID vị trí" là một khóa ngoại tham chiếu đến khóa chính của mối quan hệ "Vị trí". Trong ví dụ này, tất cả các yêu cầu được áp đặt bằng cách khai báo khóa chính và khóa ngoại đơn giản, do đó không cần chuẩn hóa thêm. Thật thú vị và hữu ích khi biết rằng trong thực tế, người ta thường tự giới hạn mình trong việc đưa cơ sở dữ liệu về dạng bình thường thứ ba. Đồng thời, một số phụ thuộc hàm của các thuộc tính chính trên các thuộc tính khác của cùng một mối quan hệ có thể không được áp đặt. Hỗ trợ cho các phụ thuộc chức năng không chuẩn như vậy được thực hiện bằng cách sử dụng các trình kích hoạt đã đề cập trước đó (nghĩa là, về mặt thủ tục, bằng cách viết mã chương trình thích hợp). Hơn nữa, các trình kích hoạt phải hoạt động với các bộ giá trị của mối quan hệ này. 5. Dạng thông thường Boyce-Codd (NFBC) Dạng chuẩn Boyce-Codd đứng sau "độ phức tạp" chỉ sau dạng chuẩn thứ ba. Do đó, dạng bình thường Boyce-Codd đôi khi còn được gọi đơn giản là hình thức bình thường thứ ba mạnh mẽ (hoặc tăng cường 3 NF). Tại sao cô ấy được tăng cường? Chúng tôi xây dựng định nghĩa của dạng chuẩn Boyce-Codd: Sự định nghĩa. Mối quan hệ cơ sở là trong Boyce dạng bình thường - Kodd nếu và chỉ khi nó ở dạng bình thường thứ ba, và không chỉ bất kỳ thuộc tính không phải khóa nào cũng phụ thuộc đầy đủ về mặt chức năng vào bất kỳ khóa nào, mà bất kỳ thuộc tính khóa nào cũng phải phụ thuộc đầy đủ về mặt chức năng vào bất kỳ khóa nào. Do đó, yêu cầu rằng các thuộc tính không phải khóa thực sự phụ thuộc vào toàn bộ khóa và không phụ thuộc vào gì ngoài khóa cũng áp dụng cho các thuộc tính khóa. Trong một quan hệ ở dạng thông thường Boyce-Codd, tất cả các phụ thuộc hàm trong quan hệ được áp đặt bởi khai báo các khóa. Tuy nhiên, khi giảm các quan hệ cơ sở dữ liệu thành dạng Boyce-Codd, có thể xảy ra các tình huống trong đó các phụ thuộc giữa các thuộc tính của các quan hệ khác nhau trở thành phụ thuộc hàm không áp đặt. Việc hỗ trợ các phụ thuộc chức năng như vậy với các trình kích hoạt hoạt động trên các bộ giá trị của các quan hệ khác nhau sẽ khó hơn so với trường hợp ở dạng chuẩn thứ ba, khi các trình kích hoạt hoạt động trên các bộ giá trị của một quan hệ đơn lẻ. Ngoài ra, thực tiễn thiết kế hệ quản trị cơ sở dữ liệu đã chỉ ra rằng không phải lúc nào cũng có thể đưa quan hệ cơ bản về dạng chuẩn Boyce-Codd. Lý do cho sự bất thường được lưu ý là các yêu cầu của dạng chuẩn thứ hai và dạng chuẩn thứ ba không yêu cầu sự phụ thuộc hàm tối thiểu vào khóa chính của các thuộc tính là thành phần của các khóa khả thi khác. Vấn đề này được giải quyết bằng dạng chuẩn, trong lịch sử được gọi là dạng chuẩn Boyce-Codd và là dạng tinh chỉnh của dạng chuẩn thứ ba trong trường hợp có một số khóa chồng chéo có thể có. Nói chung, chuẩn hóa lược đồ cơ sở dữ liệu làm cho việc cập nhật cơ sở dữ liệu hiệu quả hơn để hệ quản trị cơ sở dữ liệu thực hiện vì nó làm giảm số lần kiểm tra và sao lưu để duy trì tính toàn vẹn của cơ sở dữ liệu. Khi thiết kế cơ sở dữ liệu quan hệ, bạn hầu như luôn đạt được dạng bình thường thứ hai của tất cả các mối quan hệ trong cơ sở dữ liệu. Trong cơ sở dữ liệu được cập nhật thường xuyên, chúng thường cố gắng cung cấp dạng quan hệ thông thường thứ ba. Dạng thông thường Boyce-Codd ít được chú ý hơn nhiều vì trong thực tế, các tình huống trong đó một quan hệ có nhiều khóa ứng viên chồng chéo nhau là rất hiếm. Tất cả những điều trên làm cho dạng thông thường Boyce-Codd không thuận tiện lắm để sử dụng khi phát triển mã chương trình, do đó, như đã đề cập trước đó, trong thực tế, các nhà phát triển thường hạn chế đưa cơ sở dữ liệu của họ sang dạng thông thường thứ ba. Tuy nhiên, nó cũng có một tính năng riêng khá gây tò mò. Vấn đề là các tình huống trong đó một quan hệ ở dạng chuẩn thứ ba nhưng không ở dạng chuẩn Boyce-Codd là cực kỳ hiếm trong thực tế, tức là sau khi rút gọn xuống dạng chuẩn thứ ba, thường tất cả các phụ thuộc hàm được áp đặt bởi các khai báo của chính, ứng cử viên và khóa ngoại, vì vậy không cần trình kích hoạt để hỗ trợ các phụ thuộc chức năng. Tuy nhiên, nhu cầu về trình kích hoạt vẫn để hỗ trợ các ràng buộc toàn vẹn không được liên kết bởi các phụ thuộc chức năng. 6. Làm tổ ở dạng bình thường Làm tổ của các hình thức bình thường có nghĩa là gì? Làm tổ ở dạng bình thường - đây là tỷ lệ của các khái niệm về dạng yếu đi và dạng tăng cường trong mối quan hệ với nhau. Việc lồng các hình thức bình thường hoàn toàn tuân theo các định nghĩa tương ứng của chúng. Hãy tưởng tượng một biểu đồ minh họa mối quan hệ lồng nhau của các dạng thông thường mà chúng ta đã biết:
Hãy để chúng tôi giải thích các khái niệm về dạng bình thường yếu đi và tăng cường đối với nhau bằng cách sử dụng các ví dụ cụ thể. Dạng chuẩn đầu tiên bị suy yếu so với dạng chuẩn thứ hai (và liên quan đến tất cả các dạng bình thường khác). Thật vậy, nhớ lại các định nghĩa của tất cả các dạng thông thường mà chúng ta đã trải qua, chúng ta có thể thấy rằng các yêu cầu của mỗi dạng bình thường bao gồm yêu cầu thuộc về dạng chuẩn đầu tiên (sau cùng, nó đã được đưa vào mỗi định nghĩa tiếp theo). Dạng bình thường thứ hai mạnh hơn dạng bình thường thứ nhất, nhưng yếu hơn dạng bình thường thứ ba và dạng bình thường Boyce-Codd. Trên thực tế, thuộc về dạng chuẩn thứ hai được bao gồm trong định nghĩa của dạng thứ ba, và bản thân dạng thứ hai, đến lượt nó, bao gồm dạng chuẩn đầu tiên. Dạng chuẩn Boyce-Codd không chỉ được tăng cường đối với dạng bình thường thứ ba, mà còn đối với tất cả các dạng khác trước nó. Và đến lượt nó, dạng bình thường thứ ba bị suy yếu chỉ so với dạng bình thường Boyce-Codd. Bài giảng số 11. Thiết kế lược đồ cơ sở dữ liệu Phương tiện phổ biến nhất để trừu tượng hóa các lược đồ cơ sở dữ liệu khi thiết kế ở mức logic là cái gọi là mô hình mối quan hệ thực thể. Nó cũng đôi khi được gọi là Mô hình ER, trong đó ER là chữ viết tắt của cụm từ tiếng Anh Entity - Relationship, dịch theo nghĩa đen là "thực thể - mối quan hệ". Các phần tử của các mô hình đó là các lớp thực thể, các thuộc tính và mối quan hệ của chúng. Chúng tôi sẽ đưa ra lời giải thích và định nghĩa của từng yếu tố này. Lớp thực thể giống như một lớp đối tượng vô phương thức theo nghĩa của lập trình hướng đối tượng. Khi chuyển sang lớp vật lý, các lớp thực thể được chuyển đổi thành các mối quan hệ cơ sở dữ liệu quan hệ cơ bản cho các hệ quản trị cơ sở dữ liệu cụ thể. Bản thân chúng cũng giống như các quan hệ cơ bản, có các thuộc tính riêng. Hãy để chúng tôi đưa ra một định nghĩa chính xác và chặt chẽ hơn về các đối tượng vừa cho. lớp được gọi là mô tả được đặt tên của một tập hợp các đối tượng có các thuộc tính, phép toán, mối quan hệ và ngữ nghĩa chung. Về mặt đồ họa, một lớp thường được mô tả như một hình chữ nhật. Mỗi lớp phải có một tên (một chuỗi văn bản) để phân biệt duy nhất nó với tất cả các lớp khác. thuộc tính lớp là một thuộc tính được đặt tên của một lớp mô tả tập hợp các giá trị mà các thể hiện của thuộc tính này có thể nhận. Một lớp có thể có bất kỳ số lượng thuộc tính nào (đặc biệt, nó có thể không có thuộc tính). Thuộc tính được thể hiện bởi một thuộc tính là một thuộc tính của thực thể được mô hình hóa chung cho tất cả các đối tượng của lớp đã cho. Vì vậy, một thuộc tính là một trừu tượng của trạng thái của một đối tượng. Bất kỳ thuộc tính nào của bất kỳ đối tượng lớp nào cũng phải có một số giá trị. Các mối quan hệ được gọi là được thực hiện bằng cách sử dụng khai báo khóa ngoại (chúng ta đã gặp các hiện tượng tương tự trước đây), tức là trong quan hệ, khóa ngoại được khai báo tham chiếu đến khóa chính hoặc khóa ứng viên của một số mối quan hệ khác. Và thông qua đó, một số quan hệ cơ bản độc lập khác nhau được "liên kết" thành một hệ thống duy nhất được gọi là cơ sở dữ liệu. Hơn nữa, sơ đồ hình thành cơ sở đồ họa của mô hình mối quan hệ-thực thể được mô tả bằng cách sử dụng ngôn ngữ mô hình hóa thống nhất UML. Rất nhiều cuốn sách được dành cho ngôn ngữ mô hình hóa hướng đối tượng UML (hoặc Ngôn ngữ mô hình hóa thống nhất), nhiều cuốn sách đã được dịch sang tiếng Nga (và một số được viết bởi các tác giả người Nga). Nói chung, UML cho phép bạn mô hình hóa các loại hệ thống khác nhau: hoàn toàn là phần mềm, hoàn toàn là phần cứng, phần mềm-phần cứng, hỗn hợp, rõ ràng bao gồm các hoạt động của con người, v.v. Tuy nhiên, trong số những thứ khác, như chúng ta đã đề cập, ngôn ngữ UML được sử dụng tích cực để thiết kế cơ sở dữ liệu quan hệ. Đối với điều này, một phần nhỏ của ngôn ngữ (sơ đồ lớp) được sử dụng, và thậm chí sau đó không đầy đủ. Từ góc độ thiết kế cơ sở dữ liệu quan hệ, khả năng mô hình hóa không quá khác biệt so với sơ đồ ER. Chúng tôi cũng muốn chỉ ra rằng trong bối cảnh thiết kế cơ sở dữ liệu quan hệ, các phương pháp thiết kế cấu trúc dựa trên việc sử dụng sơ đồ ER và phương pháp hướng đối tượng dựa trên việc sử dụng ngôn ngữ UML chỉ khác nhau về thuật ngữ. Mô hình ER đơn giản hơn về mặt khái niệm so với UML, nó có ít khái niệm, thuật ngữ và tùy chọn ứng dụng hơn. Và điều này cũng dễ hiểu, vì các phiên bản khác nhau của các mô hình ER được phát triển đặc biệt để hỗ trợ thiết kế cơ sở dữ liệu quan hệ và các mô hình ER hầu như không chứa các tính năng vượt quá nhu cầu thực sự của một nhà thiết kế cơ sở dữ liệu quan hệ. UML thuộc về thế giới đối tượng. Thế giới này phức tạp hơn nhiều (nếu bạn thích, khó hiểu hơn, khó hiểu hơn) so với thế giới quan hệ. Bởi vì UML có thể được sử dụng cho mô hình hướng đối tượng thống nhất của bất kỳ thứ gì, ngôn ngữ này chứa rất nhiều khái niệm, thuật ngữ và trường hợp sử dụng thừa từ quan điểm thiết kế cơ sở dữ liệu quan hệ. Nếu chúng ta trích xuất từ cơ chế chung của biểu đồ lớp những gì thực sự cần thiết cho việc thiết kế cơ sở dữ liệu quan hệ, thì chúng ta sẽ nhận được biểu đồ ER chính xác với một ký hiệu và thuật ngữ khác. Điều kỳ lạ là khi tạo tên lớp trong UML, cho phép sự kết hợp tùy ý của các chữ cái, số và thậm chí cả dấu chấm câu. Tuy nhiên, trong thực tế, nên sử dụng các tính từ và danh từ ngắn gọn và có ý nghĩa làm tên lớp, mỗi tên bắt đầu bằng một chữ cái viết hoa. (Chúng ta sẽ xem xét khái niệm sơ đồ chi tiết hơn trong đoạn tiếp theo của bài giảng.) 1. Các loại và số bội của trái phiếu Mối quan hệ giữa các mối quan hệ trong thiết kế các lược đồ cơ sở dữ liệu được mô tả như các đường kết nối các lớp thực thể. Hơn nữa, mỗi đầu của kết nối có thể (và nói chung nên) được đặc trưng bởi tên (tức là kiểu kết nối) và tính đa dạng của vai trò của lớp trong kết nối. Chúng ta hãy xem xét chi tiết hơn các khái niệm về tính đa dạng và các loại kết nối. sự đa dạng (tính đa dạng) là một đặc tính cho biết có bao nhiêu thuộc tính của một lớp thực thể với một vai trò nhất định có thể hoặc nên tham gia vào mỗi trường hợp của một mối quan hệ nào đó. Cách phổ biến nhất để đặt bản số của một vai trò quan hệ là chỉ định trực tiếp một số hoặc phạm vi cụ thể. Ví dụ: chỉ định "1" nói rằng mỗi lớp có vai trò nhất định phải tham gia vào một số trường hợp của kết nối này và chính xác một đối tượng của lớp có vai trò này có thể tham gia vào mỗi trường hợp của kết nối. Việc chỉ định phạm vi "0..1" chỉ ra rằng không phải tất cả các đối tượng của lớp với một vai trò nhất định đều được yêu cầu tham gia vào bất kỳ trường hợp nào của mối quan hệ này, nhưng chỉ một đối tượng có thể tham gia vào mỗi trường hợp của mối quan hệ. Hãy nói chi tiết hơn về tính đa dạng. Các bản số điển hình, phổ biến nhất trong hệ thống thiết kế cơ sở dữ liệu là các bản số sau: 1) 1 - bội số của kết nối ở đầu tương ứng của nó bằng một; 2) 0... 1 - dạng ký hiệu này có nghĩa là bội số của một kết nối nhất định ở đầu tương ứng của nó không thể vượt quá một; 3) 0... ∞ - bội số này được giải mã đơn giản là “nhiều”. Thật tò mò rằng, theo quy luật, “rất nhiều” có nghĩa là “không có gì”; 4) 1... ∞ - ký hiệu này được đặt cho bội số “một hoặc nhiều”. Hãy để chúng tôi đưa ra một ví dụ về một sơ đồ đơn giản để minh họa công việc với các liên kết nhân khác nhau.
Theo sơ đồ này, ta có thể dễ dàng hiểu rằng mỗi phòng vé có nhiều vé, và lần lượt mỗi phòng vé được đặt tại một (và không quá nhiều) phòng vé. Bây giờ hãy xem xét các loại hoặc tên liên kết phổ biến nhất. Hãy liệt kê chúng: 1) 1: 1 - chỉ định này đã được trao cho kết nối "một đối một", tức là, nó giống như một sự tương ứng một-một của hai tập hợp; 2) 1 : 0... ∞ - đây là ký hiệu cho kết nối như "một đến nhiều". Để ngắn gọn, mối quan hệ như vậy được gọi là" 1: M ". Trong sơ đồ được xem xét trước đó, như bạn có thể thấy, có một mối quan hệ chỉ với một cái tên như vậy; 3) 0... ∞ : 1 - đây là sự đảo ngược của kết nối trước đó hoặc kết nối thuộc loại "nhiều đến một"; 4) 0... ∞ : 0... ∞ là ký hiệu cho kết nối như "nhiều nhiều", tức là có nhiều thuộc tính ở mỗi đầu của liên kết; 5) 0... 1 : 0... 1 - đây là kết nối tương tự như kết nối kiểu “một đối một” đã được giới thiệu trước đó, đến lượt nó, nó được gọi là "không nhiều hơn một đến không nhiều hơn một"; 6) 0... 1 : 0... ∞ - đây là kết nối tương tự như kết nối một-nhiều, gọi là “không quá một đến nhiều”; 7) 0... ∞ : 0... 1 - đây là kết nối, tương tự như kết nối nhiều-một, nó được gọi là "nhiều đến không nhiều hơn một". Như bạn có thể thấy, ba kết nối cuối cùng thu được từ các kết nối được liệt kê trong bài giảng của chúng tôi dưới các số một, hai và ba bằng cách thay thế bội số của "một" bằng bội của "không nhiều hơn một". 2. Các sơ đồ. Các loại biểu đồ Và bây giờ cuối cùng chúng ta hãy tiến hành trực tiếp đến việc xem xét các sơ đồ và các loại của chúng. Nói chung, có ba cấp độ của mô hình logic. Các cấp độ này khác nhau về độ sâu đại diện của thông tin về cấu trúc dữ liệu. Các mức này tương ứng với các sơ đồ sau: 1) sơ đồ trình bày; 2) sơ đồ chính; 3) sơ đồ thuộc tính hoàn chỉnh. Hãy để chúng tôi phân tích từng loại sơ đồ này và giải thích chi tiết ý nghĩa của sự khác biệt của chúng về độ sâu trình bày thông tin về cấu trúc dữ liệu. 1. Sơ đồ trình bày. Các sơ đồ như vậy chỉ mô tả các lớp cơ bản nhất của các thực thể và các mối quan hệ của chúng. Các phím trong sơ đồ như vậy có thể hoàn toàn không được mô tả, và do đó, các kết nối có thể không được cá nhân hóa theo bất kỳ cách nào. Do đó, các mối quan hệ nhiều-nhiều có thể chấp nhận được, mặc dù chúng thường bị tránh hoặc nếu chúng tồn tại, hãy tinh chỉnh. Các thuộc tính tổng hợp và nhiều giá trị cũng hoàn toàn hợp lệ, mặc dù chúng tôi đã viết trước đó rằng các quan hệ cơ sở với các thuộc tính như vậy không bị giảm xuống bất kỳ dạng bình thường nào. Điều thú vị là trong số ba loại biểu đồ chúng ta đã xem xét, chỉ có loại cuối cùng (biểu đồ thuộc tính đầy đủ) giả định rằng dữ liệu được trình bày với nó ở dạng bình thường. Trong khi sơ đồ trình bày đã được xem xét và sơ đồ chính ở dòng tiếp theo không ngụ ý bất cứ điều gì thuộc loại này. Các sơ đồ như vậy thường được sử dụng cho các bài thuyết trình (do đó tên của chúng - thuyết trình, nghĩa là, được sử dụng cho các bài thuyết trình, trình diễn, nơi không cần chi tiết quá mức). Đôi khi khi thiết kế cơ sở dữ liệu, cần phải tham khảo ý kiến của các chuyên gia trong lĩnh vực mà cơ sở dữ liệu cụ thể này xử lý thông tin. Sau đó, sơ đồ trình bày cũng được sử dụng, bởi vì để có được thông tin cần thiết từ các chuyên gia trong một nghề khác xa với lập trình, không cần phải làm rõ quá mức các chi tiết cụ thể. 2. Sơ đồ phím. Không giống như sơ đồ trình bày, sơ đồ khóa nhất thiết phải mô tả tất cả các lớp của thực thể và mối quan hệ của chúng, tuy nhiên, chỉ về khóa chính. Ở đây, các mối quan hệ nhiều-nhiều đã nhất thiết phải chi tiết (tức là các mối quan hệ kiểu này ở dạng thuần túy đơn giản là không thể được chỉ định ở đây). Các thuộc tính đa giá trị vẫn được phép theo cách tương tự như trong sơ đồ trình bày, nhưng nếu chúng hiện diện trong sơ đồ khóa, chúng thường được chuyển đổi thành các lớp thực thể độc lập. Tuy nhiên, thật kỳ lạ, các thuộc tính rõ ràng vẫn có thể được trình bày không đầy đủ hoặc được mô tả dưới dạng hỗn hợp. Những "quyền tự do" này, vẫn còn hiệu lực trong các sơ đồ như sơ đồ trình bày và sơ đồ khóa, không được phép trong loại sơ đồ tiếp theo, bởi vì chúng xác định rằng quan hệ cơ sở không được chuẩn hóa. Do đó, chúng ta có thể kết luận rằng các sơ đồ khóa trong tương lai chỉ giả sử các thuộc tính "treo" trên các lớp thực thể đã được mô tả, tức là sử dụng sơ đồ trình bày, nó đủ để mô tả các lớp thực thể cần thiết nhất và sau đó, bằng cách sử dụng sơ đồ khóa, thêm mọi thứ cho nó các thuộc tính cần thiết và chỉ định tất cả các liên kết quan trọng nhất. 3. Sơ đồ thuộc tính đầy đủ. Các sơ đồ thuộc tính đầy đủ mô tả chi tiết nhất về tất cả các lớp thực thể ở trên, các thuộc tính của chúng và mối quan hệ giữa các lớp thực thể này. Theo quy định, các biểu đồ như vậy đại diện cho dữ liệu ở dạng chuẩn thứ ba, do đó, trong các mối quan hệ cơ bản được mô tả bởi các biểu đồ đó, các thuộc tính phức hợp hoặc nhiều giá trị không được phép, cũng như không có nhiều-to- không chi tiết nhiều mối quan hệ. Tuy nhiên, các biểu đồ thuộc tính hoàn chỉnh vẫn có một nhược điểm, đó là chúng không thể được gọi là hoàn chỉnh nhất trong các biểu đồ về cách trình bày dữ liệu. Ví dụ, tính đặc thù của các hệ quản trị cơ sở dữ liệu cụ thể khi sử dụng các sơ đồ thuộc tính đầy đủ vẫn chưa được tính đến, và đặc biệt, kiểu dữ liệu chỉ được chỉ định ở mức độ cần thiết cho mức logic cần thiết của mô hình hóa. 3. Các hiệp hội và sự di chuyển quan trọng Trước đó một chút, chúng ta đã nói về những mối quan hệ trong cơ sở dữ liệu. Đặc biệt, mối quan hệ được thiết lập khi khai báo khóa ngoại của mối quan hệ. Nhưng trong phần này của khóa học, chúng ta không còn nói về các quan hệ cơ bản nữa, mà là về máy tính tiền của các thực thể. Theo nghĩa này, quá trình thiết lập các mối quan hệ vẫn gắn liền với việc khai báo các khóa khác nhau, nhưng bây giờ chúng ta đang nói về các khóa của các lớp thực thể. Cụ thể, quá trình thiết lập các mối quan hệ gắn liền với việc chuyển một khóa chính đơn giản hoặc tổng hợp của một lớp thực thể này sang một lớp khác. Quá trình chuyển giao như vậy còn được gọi là di chuyển chính. Trong trường hợp này, lớp thực thể có khóa chính được chuyển được gọi là lớp cha mẹvà lớp các thực thể mà khóa ngoại được di chuyển vào được gọi là lớp trẻ em các thực thể. Trong một lớp thực thể con, các thuộc tính khóa nhận trạng thái của các thuộc tính khóa ngoại và có thể hoặc không tham gia vào việc hình thành khóa chính của chính nó. Do đó, khi một khóa chính được di chuyển từ lớp cha sang lớp thực thể con, một khóa ngoại sẽ xuất hiện trong lớp con tham chiếu đến khóa chính của lớp cha. Để thuận tiện cho việc biểu diễn công thức của quá trình di chuyển khóa, chúng tôi giới thiệu các điểm đánh dấu chính sau: 1) PK - đây là cách chúng ta sẽ biểu thị bất kỳ thuộc tính nào của khóa chính (khóa chính); 2) FK - với điểm đánh dấu này chúng ta sẽ biểu thị các thuộc tính của khóa ngoại (khóa ngoại); 3) PFK - với một điểm đánh dấu như vậy, chúng ta sẽ biểu thị một thuộc tính của khóa chính / khóa ngoại, tức là bất kỳ thuộc tính nào như vậy là một phần của khóa chính duy nhất của một số lớp thực thể và đồng thời là một phần của một số khóa ngoại của cùng một lớp thực thể . Do đó, các thuộc tính của một lớp thực thể với các dấu PK và FK tạo thành khóa chính của lớp này. Và các thuộc tính với các điểm đánh dấu FK và PFK là một phần của một số khóa ngoại của lớp thực thể này. Nói chung, các khóa có thể di chuyển theo nhiều cách khác nhau và trong mỗi trường hợp khác nhau, một số loại kết nối sẽ phát sinh. Vì vậy, chúng ta hãy xem xét có những loại liên kết nào tùy thuộc vào sơ đồ di chuyển chính. Tổng cộng, có hai chương trình di chuyển chính. 1. Lược đồ di chuyển ∀PK (PK |→PFK); Trong mục này, ký hiệu "| →" có nghĩa là khái niệm "di chuyển", tức là công thức trên sẽ được đọc như sau: bất kỳ (mỗi) thuộc tính nào của khóa chính PK của lớp thực thể mẹ được chuyển (di chuyển) đến khóa chính PFLớp thực thể con K, tất nhiên, cũng là một khóa ngoại cho lớp này. Trong trường hợp này, chúng ta đang nói về thực tế là, không có ngoại lệ, mọi thuộc tính khóa của lớp thực thể mẹ phải được chuyển sang lớp thực thể con. Loại kết nối này được gọi là xác định, vì khóa của lớp thực thể mẹ hoàn toàn tham gia vào việc xác định các thực thể con. Trong số các liên kết của kiểu xác định, có thể có thêm hai loại liên kết độc lập. Vì vậy, có hai loại liên kết xác định: 1) xác định đầy đủ. Mối quan hệ nhận dạng được cho là xác định đầy đủ nếu và chỉ khi các thuộc tính của khóa chính di chuyển của lớp thực thể mẹ hoàn toàn tạo thành khóa chính (và khóa ngoài) của lớp thực thể con. Một mối quan hệ xác định đầy đủ đôi khi cũng được gọi là phân loại, bởi vì mối quan hệ nhận dạng đầy đủ xác định các thực thể con trên tất cả các danh mục; 2) không xác định đầy đủ. Mối quan hệ nhận dạng được gọi là xác định không hoàn toàn nếu và chỉ khi các thuộc tính của khóa chính di chuyển của lớp thực thể mẹ chỉ tạo thành một phần khóa chính (đồng thời là khóa ngoại) của lớp thực thể con. Như vậy, ngoài khóa có điểm đánh dấu PFK cũng sẽ có một khóa được đánh dấu PK. Trong trường hợp này, khóa ngoại PFK của lớp thực thể con sẽ hoàn toàn được xác định bởi PK khóa chính của lớp thực thể mẹ, nhưng đơn giản là PK khóa chính của mối quan hệ con này sẽ không được xác định bởi PK khóa chính của khóa cha. lớp thực thể, nó sẽ ở trên chính nó. 2. Đề án di cư ∃PK (PK |→ FK); Sơ đồ di chuyển như vậy nên được đọc như sau: có những thuộc tính khóa chính của lớp thực thể mẹ, trong quá trình di chuyển, được chuyển sang các thuộc tính không khóa bắt buộc của lớp thực thể con. Do đó, trong trường hợp này, chúng ta đang nói về thực tế là một số, chứ không phải tất cả, như trong trường hợp trước, các thuộc tính khóa chính của lớp thực thể mẹ được chuyển sang lớp thực thể con. Ngoài ra, nếu lược đồ di chuyển trước đó xác định việc di chuyển đến khóa chính của quan hệ con, khóa này đồng thời cũng trở thành khóa ngoại, thì kiểu di chuyển cuối cùng xác định rằng các thuộc tính khóa chính của lớp thực thể mẹ sẽ chuyển thành khóa bình thường , ban đầu thuộc tính không phải khóa, sau đó có trạng thái khóa ngoại. Loại kết nối này được gọi là không xác định, bởi vì, thực sự, khóa cha không hoàn toàn tham gia vào việc hình thành các thực thể con, nó chỉ đơn giản là không xác định chúng. Trong số các mối quan hệ không xác định, hai loại mối quan hệ có thể có cũng được phân biệt. Do đó, các mối quan hệ không xác định có hai loại sau: 1) nhất thiết không xác định được. Các mối quan hệ không nhận dạng được cho là nhất thiết không nhận dạng nếu và chỉ khi các giá trị Null cho tất cả các thuộc tính khóa di chuyển của một lớp thực thể con bị cấm; 2) tùy chọn không nhận dạng. Các mối quan hệ không nhận dạng được cho là không nhất thiết là không xác định nếu và chỉ khi các giá trị rỗng được cho phép đối với một số thuộc tính khóa di chuyển của lớp thực thể con. Chúng tôi tóm tắt tất cả những điều trên dưới dạng bảng sau để thuận tiện cho công việc hệ thống hóa và hiểu tài liệu đã trình bày. Cũng trong bảng này, chúng tôi sẽ bao gồm thông tin về các loại mối quan hệ ("không nhiều hơn một", "nhiều với một", "nhiều đến không nhiều hơn một") tương ứng với loại quan hệ nào (xác định đầy đủ, không đầy đủ xác định, nhất thiết không xác định, không nhất thiết không xác định). Vì vậy, giữa các lớp thực thể cha và con, kiểu quan hệ sau đây được thiết lập, tùy thuộc vào kiểu quan hệ.
Vì vậy, chúng ta thấy rằng trong tất cả các trường hợp ngoại trừ trường hợp cuối cùng, tham chiếu không trống (không rỗng) → 1. Lưu ý xu hướng rằng ở đầu cuối của kết nối mẹ trong mọi trường hợp ngoại trừ trường hợp cuối cùng, tính đa dạng được đặt thành "một". Điều này là do giá trị của khóa ngoại trong các trường hợp của các mối quan hệ này (cụ thể là xác định đầy đủ, không xác định đầy đủ và nhất thiết không xác định các loại quan hệ) nhất thiết phải tương ứng (và hơn nữa, là giá trị duy nhất) của khóa chính của lớp thực thể mẹ. Và trong trường hợp thứ hai, do thực tế là giá trị của khóa ngoại có thể bằng giá trị Null (cờ hiệu lực FK: null), nên bội số được đặt thành "không nhiều hơn một" ở phần cuối cùng của mối quan hệ. Chúng tôi thực hiện phân tích của chúng tôi sâu hơn. Ở đầu con của kết nối, trong mọi trường hợp, ngoại trừ trường hợp đầu tiên, tính đa dạng được đặt thành "nhiều". Điều này là do, do nhận dạng không đầy đủ, như trong trường hợp thứ hai, (hoặc hoàn toàn không nhận dạng như vậy, trong trường hợp thứ hai và thứ ba), giá trị của khóa chính của lớp thực thể mẹ có thể lặp lại giữa các giá trị của khóa ngoại của lớp con. Và trong trường hợp đầu tiên, mối quan hệ được xác định đầy đủ, vì vậy các thuộc tính của khóa chính của lớp thực thể mẹ chỉ có thể xuất hiện một lần trong số các thuộc tính của khóa của lớp thực thể con. Bài giảng số 12. Các mối quan hệ của các lớp thực thể Vì vậy, tất cả các khái niệm mà chúng ta đã trải qua, cụ thể là sơ đồ và các loại của chúng, các phép nhân và loại mối quan hệ, cũng như các kiểu di chuyển chính, giờ đây sẽ giúp chúng ta tìm hiểu tài liệu về các mối quan hệ giống nhau, nhưng đã có giữa các lớp cụ thể của các thực thể. Trong số chúng, như chúng ta sẽ thấy, cũng có những kết nối thuộc nhiều loại khác nhau. 1. Mối quan hệ đệ quy phân cấp Loại mối quan hệ đầu tiên giữa các lớp thực thể, mà chúng ta sẽ xem xét, là cái gọi là mối quan hệ đệ quy phân cấp. nói chung đệ quy (hoặc liên kết đệ quy) là quan hệ của một lớp thực thể với chính nó. Đôi khi, bằng cách tương tự với các tình huống trong cuộc sống, một kết nối như vậy còn được gọi là "lưỡi câu". Mối quan hệ đệ quy phân cấp (hoặc đơn giản đệ quy phân cấp) là bất kỳ mối quan hệ đệ quy nào thuộc kiểu "nhiều nhất một-nhiều". Đệ quy phân cấp được sử dụng phổ biến nhất để lưu trữ dữ liệu trong cấu trúc cây. Khi chỉ định mối quan hệ đệ quy phân cấp, khóa chính của lớp thực thể mẹ (trong trường hợp cụ thể này cũng hoạt động như một lớp thực thể con) phải được di chuyển dưới dạng khóa ngoại đến các thuộc tính không khóa bắt buộc của cùng một lớp thực thể. Tất cả điều này là cần thiết để duy trì tính toàn vẹn logic của chính khái niệm "đệ quy phân cấp". Do đó, tính đến tất cả những điều trên, chúng ta có thể kết luận rằng mối quan hệ đệ quy phân cấp chỉ có thể là không nhất thiết là không xác định và không khác, bởi vì nếu bất kỳ loại quan hệ nào khác được sử dụng, các giá trị Null cho khóa ngoại sẽ không hợp lệ và đệ quy sẽ là vô hạn. Cũng cần nhớ rằng các thuộc tính không thể xuất hiện hai lần trong cùng một lớp thực thể dưới cùng một tên. Do đó, các thuộc tính của khóa được di chuyển phải được đặt tên gọi là vai trò. Do đó, trong mối quan hệ đệ quy phân cấp, các thuộc tính của một nút được mở rộng bằng khóa ngoại là một tham chiếu tùy chọn đến khóa chính của nút là tổ tiên trực tiếp của nó. Hãy xây dựng một bản trình bày và sơ đồ khóa triển khai đệ quy phân cấp trong mô hình dữ liệu quan hệ và đưa ra một ví dụ về dạng bảng. Trước tiên, hãy tạo một sơ đồ trình bày:
Bây giờ chúng ta hãy xây dựng một sơ đồ chi tiết hơn - chính:
Hãy xem xét một ví dụ minh họa rõ ràng một kiểu quan hệ như một mối quan hệ đệ quy phân cấp. Chúng ta hãy cung cấp cho chúng ta lớp thực thể sau, giống như ví dụ trước, bao gồm các thuộc tính "Mã tổ tiên" và "Mã nút". Đầu tiên, hãy hiển thị một biểu diễn dạng bảng của lớp thực thể này:
Bây giờ chúng ta hãy xây dựng một sơ đồ đại diện cho lớp thực thể này. Để làm điều này, chúng tôi chọn từ bảng tất cả các thông tin cần thiết cho việc này: tổ tiên của nút với mã "một" không tồn tại hoặc không được xác định, từ đó chúng tôi kết luận rằng nút "một" là một đỉnh. Cùng một nút "một" là tổ tiên của các nút có mã "hai" và "ba". Lần lượt, nút có mã "hai" có hai nút con: nút có mã "bốn" và nút có mã "năm". Và nút có mã "ba" chỉ có một nút con - nút có mã "sáu". Vì vậy, tính đến tất cả những điều trên, hãy xây dựng một cấu trúc cây phản ánh thông tin về dữ liệu có trong bảng trước:
Vì vậy, chúng ta đã thấy rằng việc biểu diễn các cấu trúc cây bằng cách sử dụng mối quan hệ đệ quy phân cấp là thực sự thuận tiện. 2. Giao tiếp đệ quy mạng Kết nối đệ quy mạng của các lớp thực thể giữa chúng, giống như nó, là một tương tự đa chiều của kết nối đệ quy phân cấp mà chúng ta đã đi qua. Chỉ khi đệ quy phân cấp được xác định là mối quan hệ đệ quy "nhiều nhất là một-nhiều", thì đệ quy mạng đại diện cho cùng một mối quan hệ đệ quy, chỉ thuộc loại "nhiều-nhiều". Do thực tế là nhiều lớp thực thể tham gia vào kết nối này ở mỗi bên, nó được gọi là kết nối mạng. Như bạn đã có thể đoán bằng cách tương tự với đệ quy phân cấp, các liên kết thuộc loại đệ quy mạng được thiết kế để biểu diễn cấu trúc dữ liệu đồ thị (trong khi các liên kết phân cấp được sử dụng, như chúng ta nhớ, dành riêng cho việc triển khai cấu trúc cây). Nhưng, vì trong kết nối của kiểu đệ quy mạng, các kết nối của kiểu "nhiều-nhiều" được chỉ định, nên không thể thực hiện được nếu không có chi tiết bổ sung của chúng. Do đó, để tinh chỉnh tất cả các mối quan hệ nhiều-nhiều trong lược đồ, cần phải tạo một lớp thực thể độc lập mới chứa tất cả các tham chiếu đến mẹ hoặc con của mối quan hệ Tổ tiên-Hậu duệ. Một lớp như vậy thường được gọi là lớp thực thể liên kết. Trong trường hợp cụ thể của chúng tôi (trong cơ sở dữ liệu được xem xét trong khóa học của chúng tôi), thực thể liên kết không có các thuộc tính bổ sung của riêng nó và được gọi là kêu gọi, bởi vì nó đặt tên cho các mối quan hệ Tổ tiên-Hậu duệ bằng cách tham chiếu đến chúng. Do đó, khóa chính của lớp thực thể đại diện cho các máy chủ phải được di chuyển hai lần sang các lớp thực thể kết hợp. Trong lớp này, các khóa được di chuyển cùng nhau phải tạo thành khóa chính tổng hợp. Từ những điều đã nói ở trên, chúng ta có thể kết luận rằng việc thiết lập các liên kết khi sử dụng đệ quy mạng không nên hoàn toàn xác định và không có gì khác. Cũng giống như khi sử dụng mối quan hệ đệ quy phân cấp, khi sử dụng đệ quy mạng làm mối quan hệ, không thuộc tính nào có thể xuất hiện hai lần trong cùng một lớp thực thể dưới cùng một tên. Vì vậy, giống như lần trước, nó được quy định cụ thể rằng tất cả các thuộc tính của khóa di chuyển phải nhận được tên vai trò. Để minh họa hoạt động của truyền thông đệ quy mạng, chúng ta hãy xây dựng một bản trình bày và các sơ đồ chính thực hiện đệ quy mạng trong một mô hình dữ liệu quan hệ. Hãy bắt đầu với một sơ đồ trình bày:
Bây giờ chúng ta hãy xây dựng một sơ đồ chính chi tiết hơn:
Chúng ta thấy gì ở đây? Và chúng ta thấy rằng cả hai kết nối trong sơ đồ chính này đều là kết nối “nhiều với một”. Hơn nữa, bội số “0... ∞” hoặc bội số “nhiều” nằm ở cuối kết nối đối diện với lớp đặt tên của các thực thể. Thật vậy, có rất nhiều liên kết, nhưng tất cả chúng đều đề cập đến một mã nút, là khóa chính của lớp thực thể “Nút”. Và, cuối cùng, chúng ta hãy xem xét một ví dụ minh họa hoạt động của một kiểu kết nối như vậy bởi một lớp thực thể dưới dạng đệ quy mạng. Hãy để chúng tôi cung cấp một biểu diễn dạng bảng của một số lớp thực thể, cũng như một lớp thực thể đặt tên chứa thông tin về các liên kết. Chúng ta hãy nhìn vào các bảng này. Núm:
Links:
Thật vậy, cách biểu diễn trên là đầy đủ: nó cung cấp tất cả các thông tin cần thiết để dễ dàng tái tạo cấu trúc đồ thị được mã hóa ở đây. Ví dụ, chúng ta có thể thấy mà không có bất kỳ trở ngại nào rằng nút có mã "một" có ba nút con tương ứng với các mã "hai", "ba" và "bốn". Chúng tôi cũng thấy rằng các nút có mã "hai" và "ba" hoàn toàn không có con cháu nào và một nút có mã "bốn" có (cũng như nút "một") ba con cháu với các mã "một", "hai" và số ba". Hãy vẽ một biểu đồ được cung cấp bởi các lớp thực thể đã cho ở trên:
Vì vậy, biểu đồ chúng ta vừa xây dựng là dữ liệu mà các lớp thực thể được liên kết bằng cách sử dụng kết nối kiểu đệ quy mạng. 3. Hiệp hội Trong số tất cả các loại kết nối được đưa vào xem xét của khóa học cụ thể của bài giảng của chúng tôi, chỉ có hai loại là kết nối đệ quy. Chúng tôi đã quản lý để xem xét chúng, đây là các liên kết phân cấp và đệ quy mạng, tương ứng. Tất cả các loại mối quan hệ khác mà chúng ta phải xem xét không phải là đệ quy, nhưng theo quy luật, đại diện cho mối quan hệ của một số lớp thực thể mẹ và một số lớp thực thể con. Hơn nữa, như bạn có thể đoán, các lớp thực thể cha và con bây giờ sẽ không bao giờ trùng nhau (thực sự, chúng ta không còn nói về đệ quy nữa). Kết nối, sẽ được thảo luận trong phần này của bài giảng, được gọi là kết hợp và đề cập chính xác đến kiểu kết nối không đệ quy. Vì vậy, kết nối được gọi là sự kết hợp, được thực hiện như một mối quan hệ giữa nhiều lớp thực thể mẹ và một lớp thực thể con. Và đồng thời, gây tò mò, mối quan hệ này được mô tả bằng các mối quan hệ của nhiều loại khác nhau. Cũng cần lưu ý rằng chỉ có thể có một lớp thực thể mẹ trong quá trình liên kết, như trong đệ quy mạng, nhưng ngay cả trong trường hợp như vậy, số lượng mối quan hệ đến từ lớp thực thể con phải ít nhất là hai. Điều thú vị là trong liên kết, cũng như trong đệ quy mạng, có các loại lớp thực thể đặc biệt. Ví dụ về một lớp như vậy là một lớp thực thể con. Thật vậy, trong trường hợp chung, trong một liên kết, một lớp thực thể con được gọi là lớp thực thể liên kết. Trong trường hợp đặc biệt khi một lớp thực thể kết hợp không có các thuộc tính bổ sung của riêng nó và chỉ chứa các thuộc tính di chuyển cùng với các khóa chính từ các lớp thực thể mẹ, một lớp như vậy được gọi là lớp các thực thể đặt tên. Như bạn có thể thấy, có một sự tương đồng gần như tuyệt đối với khái niệm về các thực thể liên kết và đặt tên trong một kết nối đệ quy mạng. Thông thường, một liên kết được sử dụng để tinh chỉnh (giải quyết) các mối quan hệ nhiều-nhiều. Hãy minh họa câu nói này. Ví dụ, chúng ta được cung cấp sơ đồ trình bày sau, mô tả sơ đồ tiếp nhận một bác sĩ nhất định tại một bệnh viện nhất định:
Sơ đồ này theo nghĩa đen có nghĩa là có nhiều bác sĩ và nhiều bệnh nhân trong bệnh viện, và không có mối quan hệ và thư từ nào khác giữa bác sĩ và bệnh nhân. Vì vậy, tất nhiên, với một cơ sở dữ liệu như vậy, sẽ không bao giờ rõ ràng đối với ban giám đốc bệnh viện làm thế nào để sắp xếp các cuộc hẹn với các bác sĩ khác nhau cho các bệnh nhân khác nhau. Rõ ràng là các mối quan hệ nhiều-nhiều được sử dụng ở đây chỉ cần được chi tiết hóa để cụ thể hóa mối quan hệ giữa các bác sĩ và bệnh nhân, hay nói cách khác là tổ chức hợp lý lịch hẹn của tất cả các bác sĩ và bệnh nhân của họ trong bệnh viện. Và bây giờ chúng ta hãy xây dựng một sơ đồ chính chi tiết hơn, trong đó chúng ta đã trình bày chi tiết tất cả các mối quan hệ nhiều-nhiều hiện có. Để làm điều này, theo đó, chúng tôi sẽ giới thiệu một lớp thực thể mới, chúng tôi sẽ gọi nó là "Nhận", sẽ hoạt động như một lớp thực thể kết hợp (sau này chúng ta sẽ biết lý do tại sao đây sẽ là một lớp thực thể kết hợp chứ không chỉ là một lớp đặt tên các thực thể mà chúng ta đã nói trước đó). Vì vậy, sơ đồ chính của chúng ta sẽ trông như thế này:
Vì vậy, bây giờ bạn có thể thấy rõ ràng tại sao lớp mới "Nhận" không phải là một lớp đặt tên các thực thể. Xét cho cùng, lớp này có thuộc tính bổ sung của riêng nó là "Date - Time", do đó, theo định nghĩa, lớp mới được giới thiệu "Reception" là một lớp của các thực thể liên kết. Lớp này "liên kết" các lớp thực thể "Bác sĩ" và "Bệnh nhân" với nhau theo thời gian mà cuộc hẹn này hoặc cuộc hẹn đó được thực hiện, điều này làm cho việc làm việc với cơ sở dữ liệu như vậy thuận tiện hơn nhiều. Do đó, bằng cách giới thiệu thuộc tính "Ngày - Giờ", chúng tôi đã sắp xếp lịch làm việc rất cần thiết cho các bác sĩ khác nhau theo đúng nghĩa đen. Chúng tôi cũng thấy rằng khóa chính bên ngoài "Mã bác sĩ" của lớp thực thể "Lễ tân" tham chiếu đến khóa chính cùng tên của lớp thực thể "Bác sĩ". Và tương tự, khóa chính bên ngoài "Mã bệnh nhân" của lớp thực thể "Lễ tân" tham chiếu đến khóa chính cùng tên trong lớp thực thể "Bệnh nhân". Trong trường hợp này, tất nhiên, các lớp thực thể "Bác sĩ" và "Bệnh nhân" là cha mẹ, và đến lượt lớp thực thể liên kết "Reception", là lớp con duy nhất. Chúng ta có thể thấy rằng mối quan hệ nhiều-nhiều trong sơ đồ trình bày trước đây đã được trình bày đầy đủ chi tiết. Thay vì một mối quan hệ nhiều-nhiều mà chúng ta thấy trong sơ đồ trình bày ở trên, chúng ta có hai mối quan hệ nhiều-một. Kết thúc con của mối quan hệ đầu tiên có nhiều "nhiều", nghĩa đen là lớp thực thể "Tiếp nhận" có nhiều bác sĩ (tất cả đều ở bệnh viện). Và ở đầu cuối của mối quan hệ này là sự đa dạng của "một", điều này có nghĩa là gì? Điều này có nghĩa là trong lớp thực thể "Lễ tân", mỗi mã có sẵn của từng bác sĩ cụ thể có thể xảy ra nhiều lần vô thời hạn. Thật vậy, trong lịch trình ở bệnh viện, mật mã của cùng một bác sĩ xảy ra nhiều lần, vào những ngày và giờ khác nhau. Và đây là cùng một mã, nhưng đã thuộc lớp thực thể "Bác sĩ", nó có thể xảy ra một lần và chỉ một lần. Thật vậy, trong danh sách tất cả các bác sĩ bệnh viện (và lớp thực thể "Bác sĩ" không có gì khác ngoài một danh sách như vậy), mã của mỗi bác sĩ cụ thể chỉ có thể xuất hiện một lần. Một điều tương tự cũng xảy ra với mối quan hệ giữa lớp cha "Bệnh nhân" và lớp con "Bệnh nhân". Trong danh sách tất cả bệnh nhân của bệnh viện (trong lớp thực thể "Bệnh nhân"), mã của từng bệnh nhân cụ thể chỉ có thể xuất hiện một lần. Nhưng mặt khác, trong lịch hẹn (trong lớp thực thể "Lễ tân"), mỗi mã của một bệnh nhân cụ thể có thể xảy ra nhiều lần tùy ý. Đó là lý do tại sao các phép nhân ở hai đầu của liên kết được sắp xếp theo cách này. Để làm ví dụ về việc triển khai liên kết trong mô hình dữ liệu quan hệ, hãy xây dựng mô hình mô tả lịch trình các cuộc họp giữa khách hàng và nhà thầu với sự tham gia tùy chọn của chuyên gia tư vấn. Chúng tôi sẽ không tập trung vào sơ đồ trình bày, bởi vì chúng tôi cần phải xem xét việc xây dựng sơ đồ trong tất cả các chi tiết, và sơ đồ trình bày không thể cung cấp cơ hội như vậy. Vì vậy, chúng ta hãy xây dựng một sơ đồ chính phản ánh bản chất của mối quan hệ giữa khách hàng, nhà thầu và nhà tư vấn.
Vì vậy, chúng ta hãy bắt đầu phân tích chi tiết về sơ đồ chính trên. Thứ nhất, lớp "Đồ thị" là một lớp các thực thể liên kết, nhưng, như trong ví dụ trước, nó không phải là một lớp các thực thể được đặt tên, bởi vì nó có một thuộc tính không di chuyển vào nó cùng với các khóa, nhưng là thuộc tính riêng. Đây là thuộc tính "Ngày - Giờ". Thứ hai, chúng ta thấy rằng các thuộc tính của lớp thực thể con "Biểu đồ" "Mã khách hàng", "Mã người thực thi" và "Ngày - giờ" tạo thành một khóa chính tổng hợp của lớp thực thể này. Thuộc tính "Mã cố vấn" chỉ đơn giản là một khóa ngoại của lớp thực thể "Biểu đồ". Xin lưu ý rằng thuộc tính này cho phép các giá trị Null trong số các giá trị của nó, bởi vì theo điều kiện, sự hiện diện của chuyên gia tư vấn tại cuộc họp là không cần thiết. Hơn nữa, thứ ba, chúng tôi lưu ý rằng hai liên kết đầu tiên (trong ba liên kết có sẵn) không hoàn toàn xác định. Cụ thể là không xác định đầy đủ vì khóa di chuyển trong cả hai trường hợp (khóa chính "Mã khách hàng" và "Mã người thực thi") không hoàn toàn tạo thành khóa chính của lớp thực thể "Đồ thị". Thật vậy, thuộc tính "Ngày - Giờ" vẫn còn, cũng là một phần của khóa chính tổng hợp. Ở phần cuối của cả hai liên kết xác định không đầy đủ này, các phép nhân "một" và "nhiều" được đánh dấu. Điều này được thực hiện để cho thấy (như trong ví dụ về bác sĩ và bệnh nhân) sự khác biệt giữa việc đề cập đến mã của khách hàng hoặc người biểu diễn trong các lớp thực thể khác nhau. Thật vậy, trong lớp thực thể "Đồ thị", bất kỳ mã khách hàng hoặc nhà thầu nào cũng có thể xảy ra nhiều lần như mong muốn. Do đó, ở điểm này, đứa trẻ, phần cuối của kết nối có rất nhiều "nhiều". Và trong lớp thực thể "Khách hàng" hoặc "Nhà thầu", mỗi mã của khách hàng hoặc nhà thầu, tương ứng, có thể xuất hiện một lần và chỉ một lần, bởi vì mỗi lớp thực thể này không khác gì một danh sách đầy đủ của tất cả khách hàng và người thực hiện. Do đó, tại thời điểm này, đầu cuối của kết nối, có rất nhiều "một". Và cuối cùng, lưu ý rằng mối quan hệ thứ ba, cụ thể là mối quan hệ của lớp thực thể "Đồ thị" với lớp thực thể "Nhà tư vấn", không nhất thiết là không xác định. Thật vậy, trong trường hợp này, chúng ta đang nói về việc chuyển thuộc tính khóa "Mã nhà tư vấn" của lớp thực thể "Nhà tư vấn" thành thuộc tính không khóa của lớp thực thể "Đồ thị" cùng tên, tức là khóa chính của lớp thực thể "Nhà tư vấn" trong lớp thực thể "Đồ thị" không xác định khóa chính đã có của lớp này. Và bên cạnh đó, như đã đề cập trước đó, thuộc tính "Advisor Code" cho phép các giá trị Null, vì vậy ở đây chính xác là mối quan hệ không nhận dạng được sử dụng. Do đó, thuộc tính "Advisor Code" có được trạng thái của một khóa ngoại và không có gì hơn. Chúng ta cũng hãy chú ý đến sự đa dạng của các liên kết được đặt ở đầu mẹ và con của liên kết không xác định đầy đủ này. Kết thúc cha của nó có nhiều "không nhiều hơn một". Thật vậy, nếu chúng ta nhớ lại định nghĩa của mối quan hệ không hoàn toàn là không xác định, thì chúng ta sẽ hiểu rằng thuộc tính "Mã nhà tư vấn" từ lớp thực thể "Đồ thị" không thể tương ứng với nhiều hơn một mã nhà tư vấn từ danh sách tất cả các nhà tư vấn. (là lớp thực thể "Nhà tư vấn"). Và nói chung, nó có thể không tương ứng với bất kỳ mã nhà tư vấn nào (hãy nhớ hộp kiểm cho khả năng chấp nhận các giá trị Null Mã nhà tư vấn: Null), bởi vì theo điều kiện, sự hiện diện của một nhà tư vấn tại một nói chung, cuộc họp giữa khách hàng và nhà thầu là không cần thiết. 4. Khái quát Một kiểu quan hệ khác giữa các lớp thực thể, mà chúng ta sẽ xem xét, là mối quan hệ dạng sự khái quát. Nó cũng là một loại quan hệ không đệ quy. Vì vậy, một mối quan hệ như sự khái quát được thực hiện như một mối quan hệ của một lớp thực thể mẹ với một số lớp thực thể con (trái ngược với mối quan hệ Liên kết trước đó, xử lý một số lớp thực thể mẹ và một lớp thực thể con). Khi xây dựng các quy tắc biểu diễn dữ liệu bằng cách sử dụng mối quan hệ Tổng quát hóa, cần phải nói ngay rằng mối quan hệ này của một lớp thực thể mẹ và một số lớp thực thể con được mô tả bằng cách xác định đầy đủ các mối quan hệ, tức là mối quan hệ phân loại. Nhắc lại định nghĩa về các mối quan hệ xác định đầy đủ, chúng tôi kết luận rằng khi sử dụng Tổng quát hóa, mỗi thuộc tính của khóa chính của lớp thực thể mẹ được chuyển sang khóa chính của các lớp thực thể con, tức là các thuộc tính của khóa di chuyển chính của lớp cha. lớp thực thể hoàn toàn tạo thành các khóa chính của tất cả các lớp thực thể con, chúng xác định chúng. Thật tò mò cần lưu ý rằng Tổng quát hóa thực hiện cái gọi là phân cấp danh mục hoặc hệ thống phân cấp kế thừa. Trong trường hợp này, lớp thực thể mẹ định nghĩa lớp thực thể chung, được đặc trưng bởi các thuộc tính chung cho các thực thể của tất cả các lớp con hoặc cái gọi là các thực thể phân loại tức là, một lớp thực thể mẹ là sự tổng quát hóa theo nghĩa đen của tất cả các lớp thực thể con của nó. Để làm ví dụ về việc thực hiện tổng quát hóa trong mô hình dữ liệu quan hệ, chúng ta sẽ xây dựng mô hình sau. Mô hình này sẽ dựa trên khái niệm khái quát về "Sinh viên" và sẽ mô tả các khái niệm phân loại sau (nghĩa là nó sẽ khái quát hóa các lớp thực thể con sau): "Học sinh", "Sinh viên" và "Sinh viên sau đại học". Vì vậy, chúng ta hãy xây dựng một sơ đồ khóa phản ánh bản chất của mối quan hệ giữa lớp thực thể mẹ và các lớp thực thể con, được mô tả bằng một kết nối của kiểu Tổng quát hóa.
Vậy chúng ta thấy gì? Thứ nhất, mỗi quan hệ cơ bản (hoặc từ các lớp thực thể giống nhau) "Học sinh", "Sinh viên" và "Sinh viên sau đại học" tương ứng với các thuộc tính riêng của nó, chẳng hạn như "Lớp học", "Khóa học" và "Năm học ". Mỗi thuộc tính này đặc trưng cho các thành viên của lớp thực thể riêng của nó. Chúng ta cũng thấy rằng khóa chính của lớp thực thể mẹ "Sinh viên" sẽ di chuyển đến từng lớp thực thể con và tạo thành khóa ngoại chính ở đó. Với sự trợ giúp của các kết nối này, chúng tôi có thể xác định bằng mã của bất kỳ học sinh nào, tên, họ và chữ viết tắt của học sinh, thông tin mà chúng tôi sẽ không tìm thấy trong chính các lớp thực thể con tương ứng. Thứ hai, vì chúng ta đang nói về mối quan hệ xác định đầy đủ (hoặc phân loại) của các lớp thực thể, chúng ta sẽ chú ý đến sự đa dạng của các mối quan hệ giữa lớp thực thể mẹ và các lớp con của nó. Đầu cuối của mỗi liên kết này có nhiều "một" và mỗi đầu con của các liên kết có nhiều "nhiều nhất một". Nếu chúng ta nhớ lại định nghĩa về mối quan hệ nhận dạng đầy đủ của các lớp thực thể, thì sẽ thấy rõ rằng mã sinh viên thực sự duy nhất, là khóa chính của lớp thực thể "Sinh viên", chỉ định nhiều nhất một thuộc tính có mã như vậy trong mỗi thực thể con. lớp "Sinh viên", "Sinh viên". và Sinh viên sau Đại học. Do đó, tất cả các trái phiếu chỉ có các cấp số nhân như vậy. Hãy viết một đoạn các toán tử để tạo các quan hệ cơ bản "Học sinh" và "Học sinh" với định nghĩa các quy tắc để duy trì tính toàn vẹn tham chiếu của kiểu thác. Vì vậy chúng tôi có: Tạo học sinh bảng hữu ích. Cảm ơn ! khóa chính (Mã sinh viên) khóa ngoại (Mã số sinh viên) tham chiếu Sinh viên (Mã số sinh viên) cập nhật thác trên xóa thác Tạo bảng Sinh viên hữu ích. Cảm ơn ! khóa chính (Mã sinh viên) khóa ngoại (Mã số sinh viên) tham chiếu Sinh viên (Mã số sinh viên) cập nhật thác về xóa thác; Do đó, chúng ta thấy rằng trong lớp thực thể con (hoặc mối quan hệ) "Sinh viên", một khóa ngoại chính được chỉ định tham chiếu đến lớp thực thể mẹ (hoặc mối quan hệ) "Sinh viên". Quy tắc phân tầng để duy trì tính toàn vẹn tham chiếu xác định rằng khi các thuộc tính của lớp thực thể mẹ "Sinh viên" bị xóa hoặc cập nhật, các thuộc tính tương ứng của quan hệ con "Sinh viên" sẽ tự động được cập nhật hoặc xóa. Tương tự, khi các thuộc tính của lớp thực thể mẹ "Sinh viên" bị xóa hoặc cập nhật, các thuộc tính tương ứng của quan hệ con "Sinh viên" cũng sẽ tự động được cập nhật hoặc xóa. Cần lưu ý rằng quy tắc toàn vẹn tham chiếu này được sử dụng ở đây, bởi vì trong ngữ cảnh này (danh sách sinh viên) không hợp lý để cấm xóa và cập nhật thông tin, đồng thời gán một giá trị không xác định thay vì thông tin thực. . Bây giờ chúng ta hãy đưa ra một ví dụ về các lớp thực thể được mô tả trong sơ đồ trước, chỉ được trình bày dưới dạng bảng. Vì vậy, chúng ta có các bảng quan hệ sau: Học sinh - mối quan hệ mẹ kết hợp thông tin về các thuộc tính của tất cả các mối quan hệ khác:
Sinh viên - quan hệ con cái:
Học sinh - quan hệ con thứ hai:
Nghiên cứu sinh - quan hệ con thứ ba:
Vì vậy, thực sự, chúng ta thấy rằng các lớp con của các thực thể không chứa thông tin về họ, tên và chữ viết tắt của học sinh, tức là học sinh, sinh viên và nghiên cứu sinh. Thông tin này chỉ có thể được lấy thông qua các tham chiếu đến lớp thực thể mẹ. Chúng tôi cũng thấy rằng các mã sinh viên khác nhau trong lớp thực thể "Sinh viên" có thể tương ứng với các lớp thực thể con khác nhau. Vì vậy, về sinh viên có mã số "1" Nikolai Zabotin, không có gì được biết đến trong mối quan hệ cha mẹ, ngoại trừ tên của anh ta và tất cả thông tin khác (anh ta là ai, một học sinh, sinh viên hoặc nghiên cứu sinh) chỉ có thể được tìm thấy bằng cách tham khảo đến lớp thực thể con tương ứng (được xác định bởi mã). Tương tự, bạn cần làm việc với các học sinh còn lại, có mã được chỉ định trong lớp thực thể mẹ "Học sinh". 5. Thành phần Mối quan hệ của các lớp thực thể thuộc kiểu thành phần, giống như hai lớp trước, không thuộc kiểu quan hệ đệ quy. Thành phần (hoặc, như đôi khi nó được gọi là, tổng hợp tổng hợp) là một mối quan hệ của một lớp thực thể cha duy nhất với nhiều lớp thực thể con, giống như mối quan hệ mà chúng ta đã thảo luận trước đó. Sự khái quát. Nhưng nếu khái quát hóa được định nghĩa là mối quan hệ của các lớp thực thể được mô tả bằng cách xác định đầy đủ các mối quan hệ, thì đến lượt nó, thành phần được mô tả bằng cách xác định không đầy đủ các mối quan hệ, tức là trong quá trình cấu thành, mỗi thuộc tính của khóa chính của lớp thực thể mẹ sẽ chuyển sang thuộc tính khóa của lớp thực thể con. Và đồng thời, các thuộc tính khóa di chuyển chỉ một phần tạo thành khóa chính của lớp thực thể con. Vì vậy, với tập hợp tổng hợp (với thành phần), lớp thực thể mẹ (hoặc đơn vị) được liên kết với nhiều lớp thực thể con (hoặc các thành phần). Trong trường hợp này, các thành phần của tổng thể (tức là các thành phần của lớp thực thể mẹ) tham chiếu đến tổng thể thông qua khóa ngoại là một phần của khóa chính và do đó, không thể tồn tại bên ngoài tập hợp. Nói chung, tập hợp tổng hợp là một dạng tập hợp đơn giản nâng cao (mà chúng ta sẽ nói về một chút sau). Một thành phần (hoặc tập hợp tổng hợp) được đặc trưng bởi thực tế là: 1) tham chiếu đến lắp ráp liên quan đến việc xác định các thành phần; 2) những thành phần này không thể tồn tại bên ngoài tổng thể. Một tập hợp (một mối quan hệ mà chúng ta sẽ xem xét thêm) với các mối quan hệ nhất thiết không xác định cũng không cho phép các thành phần tồn tại bên ngoài tập hợp và do đó có ý nghĩa gần với việc triển khai tập hợp tổng hợp được mô tả ở trên. Hãy xây dựng một sơ đồ khóa mô tả mối quan hệ giữa một lớp thực thể mẹ và một số lớp thực thể con, tức là mô tả mối quan hệ của các lớp thực thể của kiểu tập hợp tổng hợp. Đây là một sơ đồ chính mô tả thành phần của các tòa nhà trong một khuôn viên nhất định, bao gồm các tòa nhà, phòng học và thang máy của chúng. Vì vậy, sơ đồ này sẽ giống như sau:
Vì vậy, chúng ta hãy nhìn vào sơ đồ mà chúng tôi vừa tạo. Chúng ta thấy gì trong đó? Đầu tiên, chúng ta thấy rằng mối quan hệ được sử dụng trong tập hợp tổng hợp này thực sự là xác định và thực sự là không xác định đầy đủ. Rốt cuộc, khóa chính của lớp thực thể mẹ "Tòa nhà" có liên quan đến việc hình thành khóa chính của các lớp thực thể con "Đối tượng" và "Thang máy", nhưng không hoàn toàn xác định nó. Khóa chính "Case No" của lớp thực thể mẹ sẽ chuyển sang khóa chính ngoại "Case No" của cả hai lớp con, nhưng ngoài khóa được di chuyển này, cả hai lớp thực thể con cũng có khóa chính của riêng chúng, tương ứng là "Đối tượng Không "và" Số thang máy ", tức là khóa chính tổng hợp của các lớp thực thể con chỉ là thuộc tính được hình thành một phần của khóa chính của lớp thực thể mẹ. Bây giờ chúng ta hãy xem xét các phép nhân của các liên kết kết nối lớp cha và lớp con. Vì chúng tôi đang xử lý các liên kết xác định không đầy đủ, nên các phép nhân hiện diện: "một" và "nhiều". Sự đa dạng "một" có ở đầu cuối của cả hai mối quan hệ và tượng trưng cho điều đó trong danh sách tất cả kho ngữ liệu có sẵn (và lớp thực thể "Corpus" chỉ là một danh sách như vậy), mỗi số chỉ có thể xuất hiện một lần, (và không hơn hơn thế) lần. Và ngược lại, trong số các thuộc tính của các lớp "Khán giả" và "Thang máy", mỗi số tòa nhà có thể xảy ra nhiều lần, vì có nhiều khán giả (hoặc thang máy) hơn tòa nhà và trong mỗi tòa nhà có một số khán phòng và thang máy. Do đó, khi liệt kê tất cả các phòng học và thang máy, chắc chắn chúng ta sẽ lặp lại số hiệu của tòa nhà. Và, cuối cùng, như trong trường hợp của kiểu kết nối trước, chúng ta hãy viết ra các đoạn của toán tử để tạo các quan hệ cơ bản (hoặc, điều tương tự, các lớp thực thể) "Đối tượng" và "Thang máy", và chúng ta sẽ thực hiện điều này với định nghĩa các quy tắc để duy trì tính toàn vẹn tham chiếu của kiểu thác. Vì vậy, câu lệnh này sẽ giống như sau: Tạo đối tượng trong bảng hữu ích. Cảm ơn ! khóa chính (số công cụ, số đối tượng) khóa ngoại (số trường hợp) tham chiếu Các mẫu (số trường hợp) cập nhật thác trên xóa thác Tạo bảng nâng hữu ích. Cảm ơn ! khóa chính (số hồ sơ, số thang máy) khóa ngoại (số trường hợp) tham chiếu Các mẫu (số trường hợp) cập nhật thác về xóa thác; Như vậy, chúng ta đã thiết lập tất cả các khóa chính và khóa ngoại cần thiết của các lớp thực thể con. Chúng tôi lại lấy quy tắc duy trì tính toàn vẹn của tham chiếu là dòng chảy, vì chúng tôi đã mô tả nó là hợp lý nhất. Bây giờ chúng ta sẽ đưa ra một ví dụ dưới dạng bảng của tất cả các lớp thực thể mà chúng ta vừa xem xét. Hãy để chúng tôi mô tả những mối quan hệ cơ bản mà chúng tôi đã phản ánh với sự trợ giúp của một biểu đồ dưới dạng bảng và để rõ ràng, chúng tôi sẽ giới thiệu một lượng dữ liệu chỉ dẫn nhất định ở đó. Vỏ bọc Mối quan hệ gốc trông như thế này:
Đối tượng - lớp thực thể con:
Thang máy - lớp thực thể con thứ hai của lớp cha "Enclosures":
Vì vậy, chúng ta có thể thấy thông tin được tổ chức như thế nào cho tất cả các tòa nhà, lớp học và thang máy của chúng trong cơ sở dữ liệu này. Cơ sở dữ liệu này có thể được sử dụng bởi bất kỳ tổ chức giáo dục ngoài đời thực nào. 6. Tính tổng hợp Tổng hợp là kiểu quan hệ cuối cùng giữa các lớp thực thể sẽ được coi là một phần của khóa học của chúng ta. Nó cũng không phải là đệ quy, và một trong hai kiểu của nó có ý nghĩa khá gần với tập hợp tổng hợp được coi là trước đây. Vì vậy, tập hợp là mối quan hệ của một lớp thực thể mẹ với nhiều lớp thực thể con. Trong trường hợp này, mối quan hệ có thể được mô tả bằng hai loại mối quan hệ: 1) các liên kết nhất thiết không xác định; 2) các liên kết không xác định tùy chọn. Nhớ lại rằng với các mối quan hệ nhất thiết không xác định, một số thuộc tính của khóa chính của lớp thực thể mẹ được chuyển sang thuộc tính không phải khóa của lớp con và các giá trị Null cho tất cả các thuộc tính của khóa di chuyển bị cấm. Và không nhất thiết phải có các mối quan hệ không định danh, việc di chuyển các khóa chính diễn ra theo nguyên tắc chính xác, nhưng giá trị Null cho một số thuộc tính của khóa di chuyển được cho phép. Khi tổng hợp, lớp thực thể mẹ (hoặc đơn vị) được liên kết với nhiều lớp thực thể con (hoặc các thành phần). Các thành phần của tổng thể (tức là lớp thực thể mẹ) tham chiếu đến tổng thể thông qua khóa ngoại không phải là một phần của khóa chính và do đó, trong trường hợp không nhất thiết là các liên kết không xác định, các thành phần tổng hợp có thể tồn tại bên ngoài tập hợp. Trong trường hợp tập hợp có các mối quan hệ nhất thiết không xác định, các thành phần của tổng thể không được phép tồn tại bên ngoài tập hợp và theo nghĩa này, tập hợp có các mối quan hệ nhất thiết không xác định là gần với tập hợp tổng hợp. Bây giờ nó đã trở nên rõ ràng mối quan hệ kiểu tập hợp là gì, hãy xây dựng một sơ đồ chính mô tả hoạt động của mối quan hệ này. Hãy để sơ đồ tương lai của chúng tôi mô tả các thành phần được đánh dấu của ô tô (cụ thể là động cơ và khung gầm). Đồng thời, chúng tôi sẽ giả định rằng sự ngừng hoạt động của ô tô ngụ ý sự ngừng hoạt động của khung gầm cùng với nó, nhưng không ngụ ý sự ngừng hoạt động đồng thời của động cơ. Vì vậy, sơ đồ chính của chúng tôi trông như thế này:
Vậy chúng ta thấy gì trong sơ đồ chính này? Đầu tiên, mối quan hệ của lớp thực thể mẹ "Cars" với lớp thực thể con "Engines" không nhất thiết là không xác định, vì thuộc tính "car #" cho phép giá trị rỗng trong số các giá trị của nó. Đổi lại, thuộc tính này cho phép các giá trị Null vì lý do rằng việc ngừng hoạt động của động cơ, theo điều kiện, không phụ thuộc vào việc ngừng hoạt động của toàn bộ xe và do đó, nó không nhất thiết xảy ra khi cho xe dừng hoạt động. Chúng tôi cũng thấy rằng khóa chính "Engine #" của lớp thực thể "Cars" sẽ di chuyển sang thuộc tính không phải khóa "Engine #" của lớp thực thể "Engines". Và đồng thời, thuộc tính này có được trạng thái của khóa ngoại. Và khóa chính trong lớp thực thể Engines này là thuộc tính Engine Marker, không tham chiếu đến bất kỳ thuộc tính nào của mối quan hệ mẹ. Thứ hai, mối quan hệ giữa lớp thực thể mẹ "Motors" và lớp thực thể con "Chassis" nhất thiết phải là mối quan hệ không xác định, vì thuộc tính khóa ngoại "Car #" không cho phép các giá trị Null trong số các giá trị của nó. Đến lượt nó, điều này xảy ra bởi vì nó được biết đến với điều kiện rằng việc ngừng hoạt động của ô tô có nghĩa là bắt buộc phải ngừng hoạt động đồng thời của khung xe. Ở đây, giống như trong trường hợp của mối quan hệ trước đó, khóa chính của lớp thực thể mẹ "Motors" được di chuyển sang thuộc tính không phải khóa "Số xe" của lớp thực thể con "Chassis". Đồng thời, khóa chính của lớp thực thể này là thuộc tính "Chassis Marker", không tham chiếu đến bất kỳ thuộc tính nào của mối quan hệ mẹ "Motors". Tiến lên. Để chủ đề được đồng hóa tốt nhất, chúng ta hãy viết lại một lần nữa các phân đoạn của các toán tử để tạo ra các quan hệ cơ bản "Động cơ" và "Khung xe" với định nghĩa các quy tắc để duy trì tính toàn vẹn tham chiếu. Tạo công cụ bảng hữu ích. Cảm ơn ! khóa chính (Điểm đánh dấu động cơ) khóa nước ngoài (số xe) tham chiếu Ô tô (xe số) cập nhật thác trên xóa tập hợp Null Tạo khung bảng hữu ích. Cảm ơn ! khóa chính (điểm đánh dấu khung) khóa nước ngoài (số xe) tham chiếu Ô tô (xe số) cập nhật thác về xóa thác; Chúng tôi thấy rằng chúng tôi đã sử dụng cùng một quy tắc để duy trì tính toàn vẹn của tham chiếu ở mọi nơi - theo tầng, vì ngay cả trước đó chúng tôi đã công nhận nó là hợp lý nhất. Tuy nhiên, lần này chúng tôi đã sử dụng (ngoài quy tắc xếp tầng) quy tắc toàn vẹn tham chiếu Null được đặt. Hơn nữa, chúng tôi đã sử dụng nó trong điều kiện sau: nếu một số giá trị của khóa chính "Số ô tô" từ lớp thực thể mẹ "Ô tô" bị xóa, thì giá trị của khóa ngoại "Số ô tô" của quan hệ con "Động cơ" tham chiếu đến nó sẽ được gán giá trị Null. 7. Hợp nhất các thuộc tính Nếu, trong quá trình di chuyển các khóa chính của một lớp thực thể mẹ nhất định, các thuộc tính từ các lớp cha khác nhau trùng khớp về ý nghĩa nhận được vào cùng một lớp con, thì các thuộc tính này phải được "hợp nhất", tức là cần phải thực hiện -gọi là hợp nhất các thuộc tính. Ví dụ, trong trường hợp một nhân viên có thể làm việc trong một tổ chức, được liệt kê trong không quá một bộ phận, sau khi thống nhất thuộc tính "Mã tổ chức", chúng ta nhận được sơ đồ chính sau:
Khi di chuyển khóa chính từ lớp thực thể mẹ "Tổ chức" và "Phòng ban" sang lớp con "Nhân viên", thuộc tính "ID tổ chức" sẽ được đưa vào lớp thực thể "Nhân viên". Và hai lần: 1) lần đầu tiên với điểm đánh dấu PFK từ lớp thực thể "Tổ chức" khi thiết lập mối quan hệ xác định không đầy đủ; 2) và lần thứ hai, với điểm đánh dấu FK với điều kiện chấp nhận giá trị Null từ lớp thực thể "Phòng ban" khi thiết lập mối quan hệ không nhất thiết không xác định. Khi hợp nhất, thuộc tính "ID tổ chức" sẽ mang trạng thái của thuộc tính khóa chính / khóa ngoại, hấp thụ trạng thái của thuộc tính khóa ngoại. Hãy xây dựng một sơ đồ chính mới thể hiện chính quá trình hợp nhất:
Như vậy, sự thống nhất của các thuộc tính đã diễn ra. Bài giảng số 13. Hệ chuyên gia và mô hình sản xuất tri thức 1. Bổ nhiệm hệ thống chuyên gia Để làm quen với một khái niệm mới đối với chúng tôi như những hệ thống chuyên gia chúng tôi, đối với những người mới bắt đầu, sẽ đi qua lịch sử hình thành và phát triển của hướng "hệ thống chuyên gia", và sau đó chúng tôi sẽ xác định khái niệm về hệ thống chuyên gia. Vào đầu những năm 80. Thế kỷ XNUMX trong nghiên cứu về việc tạo ra trí tuệ nhân tạo, một hướng độc lập mới đã được hình thành, được gọi là những hệ thống chuyên gia. Mục đích của nghiên cứu mới này về hệ thống chuyên gia là phát triển các chương trình đặc biệt được thiết kế để giải quyết các dạng vấn đề cụ thể. Loại vấn đề đặc biệt này đòi hỏi phải tạo ra một kỹ thuật tri thức hoàn toàn mới là gì? Loại nhiệm vụ đặc biệt này có thể bao gồm các nhiệm vụ từ hoàn toàn bất kỳ lĩnh vực chủ đề nào. Điều chính để phân biệt chúng với các vấn đề thông thường là nó dường như là một nhiệm vụ rất khó khăn đối với một chuyên gia về con người để giải quyết chúng. Sau đó, cái gọi là đầu tiên hệ thống chuyên gia (trong đó vai trò của một chuyên gia không còn là một con người mà là một cỗ máy), và hệ thống chuyên gia nhận được những kết quả không thua kém về chất lượng và hiệu quả so với những giải pháp mà một người bình thường - một chuyên gia thu được. Kết quả của công việc của các hệ thống chuyên gia có thể được giải thích cho người sử dụng ở cấp độ rất cao. Chất lượng này của hệ thống chuyên gia được đảm bảo bởi khả năng suy luận về kiến thức và kết luận của chính họ. Hệ thống chuyên gia có thể bổ sung kiến thức của chính họ trong quá trình tương tác với chuyên gia. Do đó, chúng có thể được đặt hoàn toàn tự tin ngang hàng với một trí tuệ nhân tạo đã được hình thành hoàn chỉnh. Các nhà nghiên cứu trong lĩnh vực hệ thống chuyên gia cho tên ngành của họ cũng thường sử dụng thuật ngữ "kỹ thuật tri thức" đã được đề cập trước đây, được giới thiệu bởi nhà khoa học người Đức E. Feigenbaum là "đưa các nguyên tắc và công cụ nghiên cứu từ lĩnh vực trí tuệ nhân tạo vào giải những bài toán khó ứng dụng đòi hỏi kiến thức chuyên môn. " Tuy nhiên, thành công thương mại đối với các công ty phát triển không đến ngay lập tức. Trong một phần tư thế kỷ từ 1960 đến 1985. Những thành công của trí tuệ nhân tạo chủ yếu liên quan đến các phát triển nghiên cứu. Tuy nhiên, bắt đầu từ khoảng năm 1985, và trên quy mô lớn từ năm 1987 đến năm 1990. hệ thống chuyên gia đã được sử dụng tích cực trong các ứng dụng thương mại. Giá trị của các hệ thống chuyên gia là khá lớn và như sau: 1) công nghệ hệ thống chuyên gia mở rộng đáng kể phạm vi các nhiệm vụ thực tế quan trọng được giải quyết trên máy tính cá nhân, giải pháp mang lại lợi ích kinh tế đáng kể và đơn giản hóa đáng kể tất cả các quy trình liên quan; 2) công nghệ hệ thống chuyên gia là một trong những công cụ quan trọng nhất trong việc giải quyết các vấn đề toàn cầu của lập trình truyền thống, chẳng hạn như thời lượng, chất lượng và do đó, chi phí phát triển các ứng dụng phức tạp cao, do đó hiệu quả kinh tế bị giảm đáng kể. ; 3) chi phí vận hành và bảo trì các hệ thống phức tạp cao, thường vượt quá chi phí phát triển nhiều lần, cũng như mức độ tái sử dụng của các chương trình thấp, v.v.; 4) sự kết hợp của công nghệ hệ thống chuyên gia với công nghệ lập trình truyền thống bổ sung chất lượng mới cho các sản phẩm phần mềm, trước hết, cung cấp khả năng sửa đổi động các ứng dụng bởi một người dùng bình thường, chứ không phải bởi một lập trình viên; thứ hai, tính “minh bạch” của ứng dụng lớn hơn, đồ họa, giao diện và sự tương tác của các hệ thống chuyên gia tốt hơn. Theo người dùng thông thường và các chuyên gia hàng đầu, trong tương lai gần, các hệ thống chuyên gia sẽ tìm thấy các ứng dụng sau: 1) hệ thống chuyên gia sẽ đóng vai trò hàng đầu ở tất cả các giai đoạn thiết kế, phát triển, sản xuất, phân phối, gỡ lỗi, kiểm soát và cung cấp dịch vụ; 2) công nghệ hệ thống chuyên gia, đã nhận được sự phân phối thương mại rộng rãi, sẽ cung cấp một bước đột phá mang tính cách mạng trong việc tích hợp các ứng dụng từ các mô-đun tương tác thông minh được tạo sẵn. Nói chung, các hệ thống chuyên gia được thiết kế cho cái gọi là nhiệm vụ không chính thức, tức là, các hệ thống chuyên gia không bác bỏ và không thay thế cách tiếp cận truyền thống để phát triển chương trình tập trung vào giải quyết các vấn đề chính thức hóa, nhưng bổ sung cho chúng, do đó mở rộng đáng kể các khả năng. Đây chính xác là điều mà một chuyên gia về con người đơn thuần không thể làm được. Các nhiệm vụ phức tạp không chính thức hóa như vậy được đặc trưng bởi: 1) ngụy biện, không chính xác, mơ hồ, cũng như tính không đầy đủ và không nhất quán của dữ liệu nguồn; 2) ngụy biện, mơ hồ, không chính xác, không đầy đủ và không thống nhất của kiến thức về lĩnh vực vấn đề và vấn đề đang được giải quyết; 3) kích thước lớn của không gian các giải pháp của một vấn đề cụ thể; 4) sự thay đổi năng động của dữ liệu và kiến thức trực tiếp trong quá trình giải quyết một vấn đề không chính thức như vậy. Các hệ thống chuyên gia chủ yếu dựa trên tìm kiếm heuristic cho một giải pháp, chứ không phải dựa trên việc thực hiện một thuật toán đã biết. Đây là một trong những lợi thế chính của công nghệ hệ thống chuyên gia so với cách tiếp cận truyền thống để phát triển phần mềm. Đây là điều cho phép họ đối phó rất tốt với các nhiệm vụ được giao. Công nghệ hệ thống chuyên gia được sử dụng để giải quyết nhiều vấn đề khác nhau. Chúng tôi liệt kê các nhiệm vụ chính của những công việc này. 1. Giải thích. Các hệ thống chuyên gia thực hiện việc giải thích thường sử dụng kết quả đọc của các công cụ khác nhau để mô tả tình trạng của công việc. Hệ thống chuyên gia phiên dịch có khả năng xử lý nhiều loại thông tin khác nhau. Một ví dụ là việc sử dụng dữ liệu phân tích quang phổ và sự thay đổi đặc tính của các chất để xác định thành phần và tính chất của chúng. Một ví dụ nữa là việc giải thích số đọc của các dụng cụ đo lường trong phòng nồi hơi để mô tả trạng thái của các nồi hơi và nước trong đó. Các hệ thống diễn giải thường giải quyết trực tiếp các chỉ định. Về vấn đề này, những khó khăn nảy sinh mà các loại hệ thống khác không có. Những khó khăn này là gì? Những khó khăn này nảy sinh do thực tế là các hệ thống chuyên gia phải giải thích thông tin thừa bị tắc nghẽn, không đầy đủ, không đáng tin cậy hoặc không chính xác. Do đó, lỗi hoặc sự gia tăng đáng kể trong quá trình xử lý dữ liệu là không thể tránh khỏi. 2. Dự báo. Các hệ thống chuyên gia thực hiện dự báo về điều gì đó xác định các điều kiện xác suất của các tình huống nhất định. Ví dụ như dự báo thiệt hại về thu hoạch ngũ cốc do điều kiện thời tiết bất lợi, đánh giá nhu cầu khí đốt trên thị trường thế giới, dự báo thời tiết theo các đài khí tượng. Các hệ thống dự báo đôi khi sử dụng mô hình hóa, tức là các chương trình hiển thị một số mối quan hệ trong thế giới thực để tạo lại chúng trong môi trường lập trình và sau đó thiết kế các tình huống có thể phát sinh với một số dữ liệu ban đầu nhất định. 3. Chẩn đoán các thiết bị khác nhau. Các hệ thống chuyên gia thực hiện các chẩn đoán đó bằng cách sử dụng các mô tả về mọi tình huống, hành vi hoặc dữ liệu về cấu trúc của các thành phần khác nhau để xác định các nguyên nhân có thể khiến hệ thống chẩn đoán bị trục trặc. Ví dụ như thiết lập hoàn cảnh của bệnh bằng các triệu chứng được quan sát thấy ở bệnh nhân (trong y học); xác định lỗi trong mạch điện tử và xác định các thành phần bị lỗi trong cơ chế của các thiết bị khác nhau. Hệ thống chẩn đoán thường là trợ lý không chỉ chẩn đoán mà còn giúp khắc phục sự cố. Trong những trường hợp như vậy, các hệ thống này có thể tương tác tốt với người dùng để hỗ trợ khắc phục sự cố và sau đó cung cấp danh sách các hành động cần thiết để giải quyết chúng. Hiện nay, nhiều hệ thống chẩn đoán đang được phát triển như các ứng dụng cho kỹ thuật và hệ thống máy tính. 4. Lập kế hoạch các sự kiện khác nhau. Hệ thống chuyên gia được thiết kế để lập kế hoạch thiết kế các hoạt động khác nhau. Các hệ thống xác định trước một chuỗi hành động gần như hoàn chỉnh trước khi bắt đầu triển khai. Ví dụ về việc lập kế hoạch các sự kiện như vậy là việc tạo ra các kế hoạch cho các hoạt động quân sự, cả phòng thủ và tấn công, được xác định trước trong một thời gian nhất định để giành được lợi thế trước các lực lượng của đối phương. 5. Thiết kế. Các hệ thống chuyên gia thực hiện thiết kế phát triển các dạng đối tượng khác nhau, có tính đến các trường hợp phổ biến và tất cả các yếu tố liên quan. Một ví dụ là kỹ thuật di truyền. 6. Kiểm soát. Các hệ thống chuyên gia thực hiện quyền kiểm soát so sánh hành vi hiện tại của hệ thống với hành vi dự kiến của nó. Hệ thống chuyên gia quan sát phát hiện hành vi được kiểm soát xác nhận kỳ vọng của họ so với hành vi bình thường hoặc giả định của họ về các sai lệch tiềm ẩn. Các hệ thống chuyên gia điều khiển, về bản chất, phải hoạt động trong thời gian thực và thực hiện giải thích hành vi của đối tượng được kiểm soát phụ thuộc vào thời gian và ngữ cảnh. Các ví dụ bao gồm theo dõi chỉ số của các dụng cụ đo lường trong lò phản ứng hạt nhân để phát hiện các trường hợp khẩn cấp hoặc đánh giá dữ liệu chẩn đoán từ bệnh nhân trong phòng chăm sóc đặc biệt. 7. Управление. Rốt cuộc, ai cũng biết rằng các hệ thống chuyên gia thực hiện quyền kiểm soát, quản lý rất hiệu quả hành vi của toàn bộ hệ thống. Một ví dụ là việc quản lý các ngành công nghiệp khác nhau, cũng như việc phân phối các hệ thống máy tính. Hệ thống chuyên gia kiểm soát phải bao gồm các thành phần quan sát để kiểm soát hành vi của một đối tượng trong một thời gian dài, nhưng chúng cũng có thể cần các thành phần khác từ các loại nhiệm vụ đã được phân tích. Hệ thống chuyên gia được sử dụng trong các lĩnh vực khác nhau: giao dịch tài chính, công nghiệp dầu khí. Công nghệ hệ thống chuyên gia cũng có thể được ứng dụng trong năng lượng, giao thông vận tải, công nghiệp dược phẩm, phát triển không gian, công nghiệp luyện kim và khai thác mỏ, hóa học và nhiều lĩnh vực khác. 2. Cấu trúc của hệ thống chuyên gia Sự phát triển của các hệ thống chuyên gia có một số khác biệt đáng kể so với sự phát triển của một sản phẩm phần mềm thông thường. Kinh nghiệm tạo ra các hệ thống chuyên gia đã chỉ ra rằng việc sử dụng phương pháp được áp dụng trong lập trình truyền thống trong quá trình phát triển của chúng hoặc làm tăng đáng kể lượng thời gian dành cho việc tạo ra các hệ thống chuyên gia, hoặc thậm chí dẫn đến kết quả tiêu cực. Hệ thống chuyên gia thường được chia thành tĩnh и năng động. Đầu tiên, hãy xem xét một hệ thống chuyên gia tĩnh. tiêu chuẩn hệ thống chuyên gia tĩnh bao gồm các thành phần chính sau: 1) bộ nhớ làm việc, còn được gọi là cơ sở dữ liệu; 2) cơ sở tri thức; 3) một người giải quyết, còn được gọi là một thông dịch viên; 4) các thành phần của việc tiếp thu kiến thức; 5) thành phần giải thích; 6) thành phần hộp thoại. Bây giờ chúng ta hãy xem xét từng thành phần chi tiết hơn. trí nhớ làm việc (tương tự tuyệt đối với RAM máy tính đang làm việc) được thiết kế để nhận và lưu trữ dữ liệu ban đầu và dữ liệu trung gian của tác vụ đang được giải quyết tại thời điểm hiện tại. База знаний được thiết kế để lưu trữ dữ liệu dài hạn mô tả một lĩnh vực chủ đề cụ thể và các quy tắc mô tả sự chuyển đổi hợp lý của dữ liệu trong lĩnh vực này của vấn đề đang được giải quyết. Người giải quyếtcòn được gọi là thông dịch viên, chức năng như sau: sử dụng dữ liệu ban đầu từ bộ nhớ làm việc và dữ liệu dài hạn từ cơ sở tri thức, nó hình thành các quy tắc, ứng dụng của nó vào dữ liệu ban đầu dẫn đến giải pháp của bài toán. Trong một từ, anh ta thực sự "giải quyết" vấn đề đặt ra trước anh ta; Thành phần thu thập kiến thức tự động hóa quá trình lấp đầy hệ thống chuyên gia với kiến thức chuyên môn, tức là chính thành phần này cung cấp cơ sở kiến thức với tất cả các thông tin cần thiết từ lĩnh vực chủ đề cụ thể này. Giải thích thành phần giải thích cách hệ thống có được giải pháp cho vấn đề này hoặc tại sao nó không nhận được giải pháp này và kiến thức mà hệ thống sử dụng để làm như vậy. Nói cách khác, thành phần giải thích tạo ra một báo cáo tiến trình. Thành phần này rất quan trọng trong toàn bộ hệ thống chuyên gia, vì nó tạo điều kiện thuận lợi đáng kể cho việc kiểm tra hệ thống bởi một chuyên gia, đồng thời cũng làm tăng sự tin tưởng của người dùng vào kết quả thu được và do đó, đẩy nhanh quá trình phát triển. Thành phần hộp thoại phục vụ cho việc cung cấp một giao diện người dùng thân thiện cả trong quá trình giải quyết một vấn đề và trong quá trình tiếp thu kiến thức và tuyên bố kết quả của công việc. Bây giờ chúng ta đã biết một hệ thống chuyên gia thống kê thường bao gồm những thành phần nào, hãy xây dựng một sơ đồ phản ánh cấu trúc của một hệ thống chuyên gia như vậy. Nó trông như thế này:
Hệ thống chuyên gia tĩnh thường được sử dụng nhiều nhất trong các ứng dụng kỹ thuật, nơi có thể không tính đến những thay đổi của môi trường xảy ra trong quá trình giải quyết vấn đề. Thật tò mò khi biết rằng các hệ thống chuyên gia đầu tiên được ứng dụng thực tế chính xác là tĩnh. Vì vậy, đến đây chúng ta sẽ kết thúc việc xem xét hệ thống chuyên gia thống kê, hãy chuyển sang phần phân tích của hệ thống chuyên gia động. Thật không may, chương trình của khóa học của chúng tôi không bao gồm việc xem xét chi tiết về hệ thống chuyên gia này, vì vậy chúng tôi sẽ giới hạn bản thân trong việc phân tích những điểm khác biệt cơ bản nhất giữa hệ thống chuyên gia động và hệ thống chuyên gia tĩnh. Không giống như một hệ thống chuyên gia tĩnh, cấu trúc hệ thống chuyên gia năng động Ngoài ra, hai thành phần sau được giới thiệu: 1) một hệ thống con để mô hình hóa thế giới bên ngoài; 2) một hệ thống con của các quan hệ với môi trường bên ngoài. Tiểu hệ thống quan hệ với môi trường bên ngoài Nó chỉ tạo kết nối với thế giới bên ngoài. Cô ấy thực hiện điều này thông qua một hệ thống cảm biến và bộ điều khiển đặc biệt. Ngoài ra, một số thành phần truyền thống của hệ thống chuyên gia tĩnh trải qua những thay đổi đáng kể để phản ánh logic thời gian của các sự kiện hiện đang xảy ra trong môi trường. Đây là sự khác biệt chính giữa hệ thống chuyên gia tĩnh và động. Một ví dụ về hệ thống chuyên gia năng động là quản lý việc sản xuất các loại thuốc khác nhau trong ngành dược phẩm. 3. Những người tham gia phát triển hệ thống chuyên gia Đại diện của các chuyên ngành khác nhau tham gia vào việc phát triển hệ thống chuyên gia. Thông thường, một hệ thống chuyên gia cụ thể được phát triển bởi ba chuyên gia. Điều này thường là: 1) chuyên gia; 2) kỹ sư tri thức; 3) một lập trình viên để phát triển các công cụ. Hãy để chúng tôi giải thích trách nhiệm của từng chuyên gia được liệt kê ở đây. Chuyên gia là một chuyên gia trong lĩnh vực chủ đề, các nhiệm vụ sẽ được giải quyết với sự trợ giúp của hệ thống chuyên gia cụ thể này đang được phát triển. Kỹ sư kiến thức là chuyên gia trực tiếp phát triển hệ thống chuyên gia. Các công nghệ và phương pháp được ông sử dụng được gọi là công nghệ và phương pháp kỹ thuật tri thức. Một kỹ sư tri thức giúp một chuyên gia xác định từ tất cả thông tin trong lĩnh vực chủ đề, thông tin cần thiết để làm việc với một hệ thống chuyên gia cụ thể đang được phát triển, và sau đó cấu trúc nó. Điều tò mò là sự vắng mặt của các kỹ sư tri thức trong số những người tham gia phát triển, tức là sự thay thế của họ bởi các lập trình viên, dẫn đến sự thất bại của toàn bộ dự án tạo ra một hệ thống chuyên gia cụ thể hoặc làm tăng đáng kể thời gian phát triển hệ thống đó. Và cuối cùng, người lập trình phát triển các công cụ (nếu các công cụ được phát triển mới) được thiết kế để đẩy nhanh sự phát triển của các hệ thống chuyên gia. Trong giới hạn, những công cụ này chứa tất cả các thành phần chính của một hệ thống chuyên gia; lập trình viên cũng giao diện các công cụ của mình với môi trường mà nó sẽ được sử dụng. 4. Phương thức hoạt động của hệ thống chuyên gia Hệ thống chuyên gia hoạt động theo hai chế độ chính: 1) trong phương thức thu nhận kiến thức; 2) trong phương thức giải quyết vấn đề (còn được gọi là phương thức tham vấn, hoặc phương thức sử dụng hệ thống chuyên gia). Điều này là hợp lý và dễ hiểu, bởi vì trước tiên cần phải tải hệ thống chuyên gia với thông tin từ lĩnh vực chủ đề mà nó phải làm việc, đây là chế độ "đào tạo" của hệ thống chuyên gia, chế độ khi nó tiếp nhận kiến thức. Và sau khi tải tất cả các thông tin cần thiết cho công việc, công việc tự nó theo sau. Hệ thống chuyên gia đã sẵn sàng hoạt động và hiện có thể được sử dụng để tham vấn hoặc giải quyết bất kỳ vấn đề nào. Hãy xem xét chi tiết hơn chế độ tiếp thu kiến thức. Trong phương thức thu nhận kiến thức, công việc với hệ thống chuyên gia được thực hiện bởi một chuyên gia thông qua một kỹ sư tri thức. Trong chế độ này, chuyên gia, sử dụng thành phần thu nhận kiến thức, lấp đầy hệ thống bằng kiến thức (dữ liệu), do đó, cho phép hệ thống giải quyết các vấn đề từ lĩnh vực chủ đề này ở chế độ giải pháp mà không cần sự tham gia của chuyên gia. Cần lưu ý rằng chế độ thu nhận kiến thức trong cách tiếp cận truyền thống để phát triển chương trình tương ứng với các giai đoạn thuật toán hóa, lập trình và gỡ lỗi do người lập trình trực tiếp thực hiện. Theo đó, trái ngược với cách tiếp cận truyền thống, trong trường hợp hệ thống chuyên gia, việc phát triển các chương trình không được thực hiện bởi một lập trình viên, mà bởi một chuyên gia, tất nhiên, với sự trợ giúp của các hệ thống chuyên gia, tức là , một người không biết lập trình. Và bây giờ chúng ta hãy xem xét phương thức hoạt động thứ hai của hệ thống chuyên gia, tức là chế độ giải quyết vấn đề. Trong chế độ giải quyết vấn đề (hay còn gọi là chế độ tham vấn), giao tiếp với các hệ thống chuyên gia được thực hiện trực tiếp bởi người dùng cuối, người quan tâm đến kết quả cuối cùng của công việc và đôi khi là phương pháp đạt được nó. Cần lưu ý rằng tùy thuộc vào mục đích của hệ thống chuyên gia, người dùng không cần phải là chuyên gia trong lĩnh vực vấn đề này. Trong trường hợp này, anh ta chuyển sang các hệ thống chuyên gia cho kết quả, không có đủ kiến thức để thu được kết quả. Hoặc, người dùng vẫn có thể có một trình độ kiến thức đủ để tự mình đạt được kết quả mong muốn. Trong trường hợp này, người dùng có thể tự lấy kết quả, nhưng chuyển sang các hệ thống chuyên gia để tăng tốc quá trình lấy kết quả hoặc giao công việc đơn điệu cho các hệ thống chuyên gia. Trong chế độ tham vấn, dữ liệu về nhiệm vụ của người dùng, sau khi được thành phần hộp thoại xử lý, sẽ đi vào bộ nhớ làm việc. Bộ giải, dựa trên dữ liệu đầu vào từ bộ nhớ làm việc, dữ liệu chung về khu vực vấn đề và các quy tắc từ cơ sở dữ liệu, tạo ra giải pháp cho vấn đề. Khi giải quyết một vấn đề, các hệ thống chuyên gia không chỉ thực hiện trình tự quy định của một hoạt động cụ thể, mà còn hình thành sơ bộ nó. Điều này được thực hiện đối với trường hợp phản ứng của hệ thống không hoàn toàn rõ ràng đối với người dùng. Trong tình huống này, người sử dụng có thể yêu cầu giải thích lý do tại sao hệ thống chuyên gia này hỏi một câu hỏi cụ thể hoặc tại sao hệ thống chuyên gia này không thể thực hiện thao tác này, cách thu được kết quả này hoặc kết quả do hệ thống chuyên gia này cung cấp. 5. Mô hình sản xuất tri thức Tại cốt lõi của nó, mô hình sản xuất tri thức gần với các mô hình logic, cho phép bạn tổ chức các thủ tục rất hiệu quả để suy luận dữ liệu logic. Đây là một mặt. Tuy nhiên, mặt khác, nếu chúng ta xem xét các mô hình sản xuất tri thức so với các mô hình logic, thì kiến thức trước đây hiển thị rõ ràng hơn, đó là một lợi thế không thể chối cãi. Do đó, không nghi ngờ gì nữa, mô hình sản xuất tri thức là một trong những phương tiện chính đại diện cho tri thức trong các hệ thống trí tuệ nhân tạo. Vì vậy, chúng ta hãy bắt đầu xem xét chi tiết về khái niệm mô hình sản xuất tri thức. Mô hình sản xuất tri thức truyền thống bao gồm các thành phần cơ bản sau: 1) một tập hợp các quy tắc (hoặc quy trình sản xuất) đại diện cho cơ sở tri thức của hệ thống sản xuất; 2) bộ nhớ làm việc, lưu trữ các dữ kiện ban đầu, cũng như các dữ kiện rút ra từ các dữ kiện ban đầu bằng cách sử dụng cơ chế suy luận; 3) bản thân cơ chế suy luận lôgic, cho phép, từ các dữ kiện có sẵn, theo các quy tắc suy luận hiện có, để rút ra các dữ kiện mới. Và, thật kỳ lạ, số lượng các phép toán như vậy có thể là vô hạn. Mỗi quy tắc đại diện cho cơ sở tri thức của hệ thống sản xuất chứa một phần điều kiện và một phần cuối cùng. Phần có điều kiện của quy tắc chứa một dữ kiện duy nhất hoặc một số dữ kiện được kết nối bằng một liên kết. Phần cuối cùng của quy tắc chứa các dữ kiện cần được bổ sung với bộ nhớ hoạt động nếu phần điều kiện của quy tắc là đúng. Nếu chúng ta cố gắng mô tả một cách sơ đồ mô hình sản xuất tri thức, thì sản xuất được hiểu là một biểu hiện của dạng sau: (chỉ số thông minh; P; A → B; N; Ở đây tôi là tên của mô hình sản xuất tri thức hoặc số sê-ri của nó, với sự trợ giúp của mô hình sản xuất này được phân biệt với toàn bộ tập hợp các mô hình sản xuất, nhận được một số loại nhận dạng. Một số đơn vị từ vựng phản ánh bản chất của sản phẩm này có thể đóng vai trò như một cái tên. Trên thực tế, chúng tôi đặt tên cho các sản phẩm để nhận thức tốt hơn bằng ý thức, nhằm đơn giản hóa việc tìm kiếm sản phẩm mong muốn từ danh sách. Hãy lấy một ví dụ đơn giản: mua một cuốn sổ "hoặc" một bộ bút chì màu. Rõ ràng, mỗi sản phẩm thường được gọi bằng những từ phù hợp với thời điểm này. Nói cách khác, gọi một thuổng là một thuổng. Tiến lên. Phần tử Q đặc trưng cho phạm vi của mô hình sản xuất tri thức cụ thể này. Những hình cầu như vậy dễ dàng được phân biệt trong tâm trí con người, do đó, như một quy luật, không có khó khăn gì với định nghĩa của nguyên tố này. Hãy lấy một ví dụ. Chúng ta hãy xem xét tình huống sau: giả sử rằng trong một lĩnh vực ý thức của chúng ta, kiến thức về cách nấu thực phẩm được lưu trữ, ở một lĩnh vực khác, cách đi làm, thứ ba là cách vận hành máy giặt đúng cách. Một bộ phận tương tự cũng hiện diện trong bộ nhớ của mô hình sản xuất tri thức. Việc phân chia kiến thức thành các lĩnh vực riêng biệt này có thể tiết kiệm đáng kể thời gian dành cho việc tìm kiếm một số mô hình sản xuất cụ thể của kiến thức cần thiết vào lúc này, và do đó đơn giản hóa đáng kể quá trình làm việc với chúng. Tất nhiên, yếu tố sản xuất chính là cái gọi là cốt lõi của nó, mà trong công thức trên của chúng ta được ký hiệu là A → B. Công thức này có thể được hiểu là "nếu điều kiện A được đáp ứng, thì hành động B sẽ được thực hiện." Nếu chúng ta đang xử lý các cấu trúc hạt nhân phức tạp hơn, thì lựa chọn thay thế sau được cho phép ở phía bên phải: "nếu điều kiện A được thỏa mãn, thì hành động B sẽ được thực hiện1, nếu không, bạn nên thực hiện hành động B2". Tuy nhiên, việc giải thích cốt lõi của mô hình sản xuất tri thức có thể khác nhau và phụ thuộc vào những gì sẽ nằm ở bên trái và bên phải của dấu tuần tự "→". Với một trong những cách giải thích về cốt lõi của mô hình sản xuất tri thức, trình tự có thể được hiểu theo nghĩa logic thông thường, tức là như một dấu hiệu của hệ quả logic của hành động B từ điều kiện A. Tuy nhiên, cũng có thể diễn giải khác về cốt lõi của mô hình sản xuất tri thức. Vì vậy, ví dụ, A có thể mô tả một số điều kiện, việc thực hiện điều kiện đó là cần thiết để một số hành động B được thực hiện. Tiếp theo, chúng ta xem xét một yếu tố của mô hình sản xuất tri thức R. Элемент Р được định nghĩa như một điều kiện cho khả năng ứng dụng của lõi sản phẩm. Nếu điều kiện P là đúng, thì lõi sản xuất được kích hoạt. Ngược lại, nếu điều kiện P không được thỏa mãn, tức là sai, lõi không thể được kích hoạt. Như một ví dụ minh họa, hãy xem xét mô hình sản xuất tri thức sau: "Tính khả dụng của tiền"; "Nếu bạn muốn mua thứ A, thì bạn nên thanh toán chi phí của nó cho nhân viên thu ngân và xuất trình séc cho người bán." Chúng tôi xem xét, nếu điều kiện P là đúng, nghĩa là, giao dịch mua được thanh toán và xuất trình séc, thì lõi được kích hoạt. Mua hàng đã hoàn tất. Nếu trong mô hình sản xuất tri thức này, điều kiện khả năng áp dụng của phần lõi là sai, tức là nếu không có tiền, thì không thể áp dụng phần cốt lõi của mô hình sản xuất tri thức và nó không được kích hoạt. Và cuối cùng đi đến phần tử N. Phần tử N được gọi là điều kiện hậu của mô hình dữ liệu sản xuất. Hậu điều kiện xác định các hành động và thủ tục phải được thực hiện sau khi thực hiện cốt lõi sản xuất. Để có nhận thức tốt hơn, hãy đưa ra một ví dụ đơn giản: sau khi mua một thứ trong cửa hàng, cần phải giảm số thứ thuộc loại này xuống một thứ trong kho hàng hóa của cửa hàng này, tức là nếu việc mua hàng được thực hiện (do đó , lõi được bán), sau đó cửa hàng có ít hơn một đơn vị của sản phẩm cụ thể này. Do đó, điều kiện sau "Gạch bỏ đơn vị của mặt hàng đã mua". Tóm lại, chúng ta có thể nói rằng việc biểu diễn tri thức như một tập hợp các quy tắc, tức là thông qua việc sử dụng mô hình sản xuất tri thức, có những ưu điểm sau: 1) đó là sự dễ dàng trong việc tạo ra và hiểu các quy tắc riêng lẻ; 2) đó là sự đơn giản của cơ chế lựa chọn hợp lý. Tuy nhiên, trong việc biểu diễn tri thức dưới dạng tập hợp các quy tắc cũng có nhược điểm là vẫn hạn chế phạm vi và tần suất áp dụng của các mô hình tri thức sản xuất. Nhược điểm chính như vậy là sự mơ hồ về mối quan hệ lẫn nhau giữa các quy tắc tạo nên một mô hình sản xuất cụ thể của tri thức, cũng như các quy tắc của sự lựa chọn hợp lý. Ghi chú 1. Phông chữ được gạch chân trong phiên bản in của cuốn sách tương ứng với in nghiêng đậm trong phiên bản (điện tử) của cuốn sách. (Khoảng e. Ed.)
▪ Điều trị tại bệnh viện. Ghi chú bài giảng
Máy tỉa hoa trong vườn
02.05.2024 Kính hiển vi hồng ngoại tiên tiến
02.05.2024 Bẫy không khí cho côn trùng
01.05.2024
▪ Biến đổi khí hậu có thể gây dị ứng vĩnh viễn ▪ Trung tâm đa phương tiện Jaguar InControl ▪ Ổ cứng HGST Ultrastar He 6TB Helium ▪ Công tắc ăng ten thu nhỏ cho điện thoại di động
▪ phần của trang web Nhà, làm vườn, sở thích. Lựa chọn các bài viết ▪ bài báo Tiêu đề chính xác trong bất kỳ cơn gió nào. Lời khuyên cho một người mẫu ▪ bài báo Khai thác vàng đầu tiên bắt đầu từ đâu? đáp án chi tiết ▪ bài viết Thợ mộc. Hướng dẫn tiêu chuẩn về bảo hộ lao động ▪ bài viết Radio ô tô trong dải 144-146 MHz. Bách khoa toàn thư về điện tử vô tuyến và kỹ thuật điện
Trang chủ | Thư viện | bài viết | Sơ đồ trang web | Đánh giá trang web
www.diagram.com.ua |



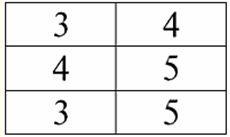
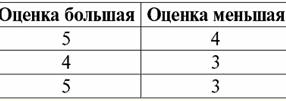

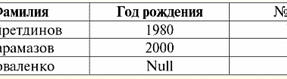

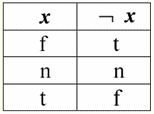

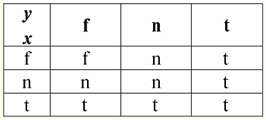
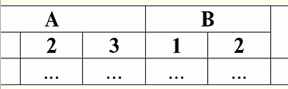


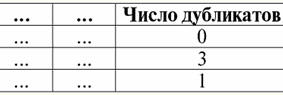
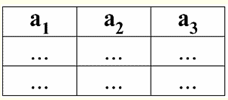






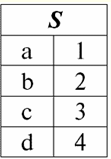
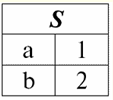

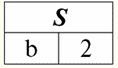
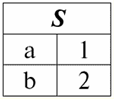

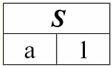
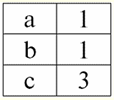

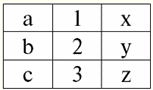









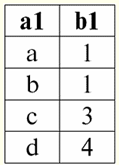






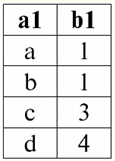



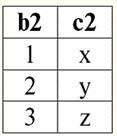

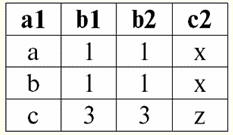
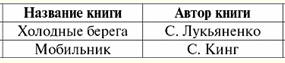







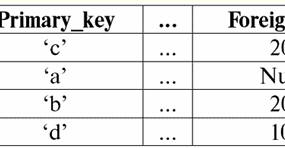











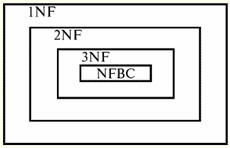

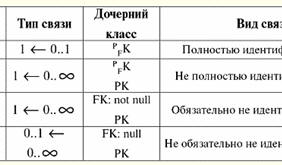






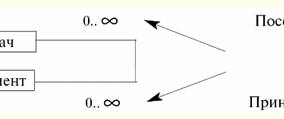

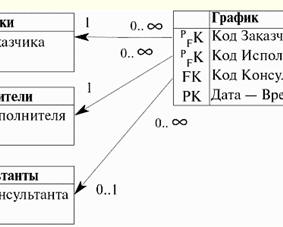


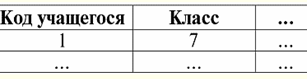
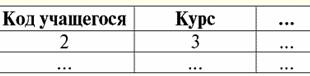





 Xem các bài viết khác razdela
Xem các bài viết khác razdela 